ゾネスさん(@takahiro-yamada)からバトンを受け取ってPOLのアドベントカレンダーを書きます、業務委託でエンジニアをしている田村です。
二年連続でクリスマスイブにアドベントカレンダーを書いているのですが、決して毎年予定がないわけではないですよ。今年も健全にお仕事頑張るぞい。
今回の題材
はい、そんな田村も今年で社会人3年目なのですが、今年は任せてもらえる仕事が増えました。小さい案件の要求定義書作やリリース後の効果測定やサービスの要因分析をしてグラフにまとめる等、仕事の幅が広がりました。
特にDBからデータを抽出し、そのデータをまとめ分析をするということは結構行っていて、一年間でクエリを92個ほど書いてました(けっこうびっくり)
ただ最初からスムーズにできたかと言われるとそうではなかったです。
やり始めた当初は、SQL自体の知識はあったのですが、実務で使うことはあまりなく**「どういう場面で使う関数なんだろう?」、「実際に使ってみないとイメージ沸かないな」**というものが多数あり、身についてない状態になっていました。
実際にクエリを書いてみると慣れないSQLに苦戦し、一個のデータを出すのに何十分何時間と時間を浪費してました(ほんとその説はすいませんでした)
SQLを勉強して、いざ実務でクエリを書いてみようとなるとこういったことに陥る人が結構いるかなと思います。
そんな実務でSQLを使いたての人向けに、この一年でよく使った関数を紹介したいと思います。
紹介する中には**「これ勉強した時に見たことある!」みたいなものが多数あると思います。(というかそれしかない気がする)
自分が学んできたことと紐付けて見てもらえると、「あ、これ進研ゼミでやったやつだ」**みたいな感覚になれると思います。
データ抽出をする前の田村の知識量
実務経験はほとんどないけど、関数に関してはうろ覚えで頭の片隅にあるレベルでした。
- ORACLE MASTER Bronze DBAを取得
→基礎的な知識は資格取得の際に学んでいます
- PythonのDjangoを使った、DB操作
→SQLとしては書いてませんが、ORMを使いデータベース操作は行っておりました。
環境
- MySQL
- Redash or SQLクライアント(Sequel pro)
前提
今回はデータ抽出をする際に使う関数のみの紹介になるため、テーブル操作系のコマンドについては紹介しません。
また、実行計画やチューニングについても触れないです。
関数紹介
それでは、関数について紹介していきます!
今回は、関数の概要、使用頻度、例文、補足(使用時の注意点・実際にデータ分析に使う時はこういう場面で使うよ等)でそれぞれ紹介していきます。
LEFT JOIN, INNER JOIN
概要:テーブル間の結合をする時に使う関数
使用頻度:★★★★★
基本的な関数なので書くか迷ったのですが、データ抽出の際に必ず書くといっても過言ではないので紹介します。
基本的にデータを抽出する時は、テーブルを跨いで抽出するのでまずは結合してデータを取れるようにしていきましょう。
また結合する時にも使える関数が複数あるのですが、今回は自分がよく使ったLEFT JOIN, INNER JOINについて紹介します。
LEFT JOINは外部結合、INNER JOINは内部結合と言われる結合関数になってます。
外部結合?内部結合?と言われてもピンとこないと思うので図にするとこんな感じです。
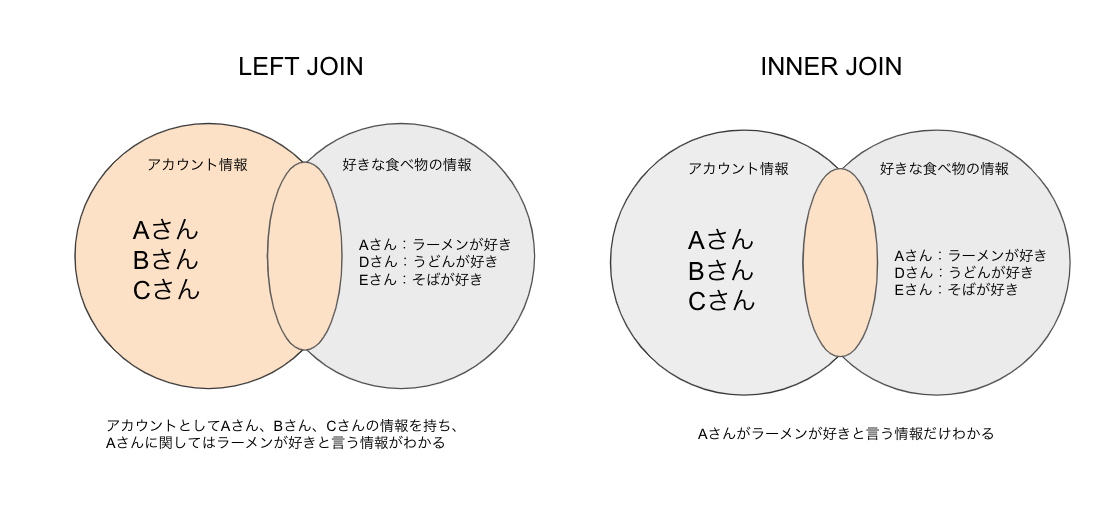
このように
LEFT JOINは条件に合わくても、結合する側のテーブル(実際に書くと上のテーブル)の情報はレコードに抽出し、結合される側のテーブルの情報はNULLとしてレコードに抽出される
INNER JOINは条件に合わない場合はレコードそのものが抽出されなくなります。
特性がわかったらどんな時に使うんだって話に移ります。自分はこんな感じで2つを棲み分けてます。
テーブルの中身がユーザに依って任意の時はLEFT JOIN(外部結合)、テーブルの中にユーザに対して必須でデータが入ってる時はINNER JOIN(内部結合)
データがない時でも必要なレコードの時はLEFT JOIN(外部結合)、データがない時に必要ないレコードの時はINNER JOIN(内部結合)
という感じにやってます。基本的にはINNER JOINの方がレコードを絞れる・レコードが絞れたことで後の処理速度が上がるといったメリットがあります。INNER JOINでかけるところは基本書いていくようにしましょう。
GROUP_CONCAT
概要:指定したカラムに含まれている値をGROUP BYで指定したグループごとに連結させた文字列を表示する関数
使用頻度:★★★★☆
1対多のデータを扱うときには大抵使います。そしてだいたいのクエリは、1対多のデータを扱うのでほとんどで使うことになります。
例えば、ユーザに紐づく好きな食べ物を管理するテーブルがあったとして
| id | account_id | food |
|---|---|---|
| 1 | 1 | ラーメン |
| 2 | 1 | うどん |
| 3 | 1 | 焼き肉 |
| 4 | 1 | ハンバーガー |
| 5 | 2 | 寿司 |
| 6 | 2 | カレーライス |
| 7 | 2 | ケバブ |
ユーザごとでまとめようとするとGROUP BYを使うことになり‥
SELECT
account_id
,food
FROM
test_table
GROUP BY account_id
| account_id | food |
|---|---|
| 1 | ラーメン |
| 2 | 寿司 |
これだけだと全部の値をデータとして取ることができません。1番の人がただラーメンが好きな人になってしまいます。(最初やりがち)
ここでGROUP_CONCATを使うと一つのカラムに文字列を連結させることができます。
SELECT
account_id
,GROUP_CONCAT(food)
FROM
test_table
GROUP BY account_id
| account_id | food |
|---|---|
| 1 | ラーメン,うどん,焼き肉,ハンバーガー |
| 2 | 寿司,カレーライス,ケバブ |
こうして1番の人がうどんも好きなことがわかるようになりましたね。
また区切り文字に関しては第2パラメータで指定できるので用途に合わせて変更しましょう(タブ文字なんかは結構使います)
CONCAT
概要:引数に指定した複数の文字列を連結して文字列にする関数
使用頻度:★★★☆☆
プログラムを書いてても文字列結合って結構使うと思うのですが、SQLでも同様なことが言えます。
名字と名前の結合等で使われることがあります。
特にデータをそのまま見る際に、クエリを作る段階で数値に単位を付けたり、見やすいように補足文を入れたりと加工した方が何かと良い場面が多いです。その際にCONCATはよく使いますね。
DATEDIFF
概要:2つの日付の差分をカウントしてくれる関数
使用頻度:★★★★☆
データ抽出の際に、日付を扱うことが結構多いので日付系の関数は覚えたほうがよいです。
この関数でいうと、「登録から何日経った」や「施策を出してから何日経った」や「ユーザが再ログインするまで何日かかった」等、例を上げると切りがないくらい色んなところで使えます。
一緒によく使うNOW()やLAST_DAY()だったり時刻の差分をカウントするTIMEDIFFなども覚えておくと幅が広がります。
DATE_FORMAT
概要:指定した日付の値を指定のフォーマットで整形した文字列を返す関数
使用頻度:★★★★☆
DATEDIFFに続いて日付を扱う関数になっているのでこちらも使用頻度は高めになってます。
データを抽出する上でデータ型をそのまま出してもよいのですが、実際にみたい・欲しいとなった時に「曜日も入れてほしい」・「時刻以降は見ない」など要望に沿った形式で出す方が親切ですし見やすいです。
例えば田村の場合、スプレッドシートにデータを貼り付けることがたまにあるのですが、その際にスプレッドシートのデフォルトの日付のフォーマットに合わせて日付を出したりします。こういった細かいところを気を遣えると良いですね。
また、DATE_FORMATはGROUP BYと合わせて使うことで日付のデータをまとめることができます。
月次:
SELECT
DATE_FORMAT(date, '%Y-%m')
,COUNT(*)
FROM
test_table
GROUP BY DATE_FORMAT(date, '%Y-%m')
週次:
SELECT
DATE_FORMAT(date, '%X-%V')
,COUNT(*)
FROM
test_table
GROUP BY DATE_FORMAT(date, '%X-%V')
日時:
SELECT
DATE_FORMAT(date, '%Y-%m-%d')
,COUNT(*)
FROM
test_table
GROUP BY DATE_FORMAT(date, '%Y-%m-%d')
こういった形で使ってあげることでDAU、WAU、MAUのような日付ごとの統計データを取ることができます。
CASE式
概要:SQLで条件分岐させたい時に使う関数
使用頻度:★★★☆☆
使用用途としては、クエリを作る段階で抽出する目的に沿った形でデータを抽出するために使われることが多いです(CONCATと同じですね)
例えば、ユーザごとのテストの合否が知りたいってなった際に、DB上ではユーザごとの点数を持っているけど合否の情報は持たないということが多いと思うんですよね(持ってる場合もあるけど)
そんな時、点数だけを引っ張ってきても合格してるかどうかはわからないですよね。そういう時はCASE式を使い条件分岐させ、合否のカラムを作ってあげるみたいなことをします。
CHAR_LENGTH
概要:指定した文字列の文字数を抽出できる関数
使用頻度:★★☆☆☆
ユーザが自由記述で入力したデータをDBで持つケースが結構あります。
そういったデータの記入率の分布を出したり、編集履歴も残ってる場合は前回更新の差分を出したりとデータを見る上で結構使われます。
自由記述はデータを出す際に様々な観点で出す必要があるのでCHAR_LENGTHは大事です。
DISTINCT
概要:重複したデータを除外してデータを取得することができる関数
使用頻度:★★★☆☆
よく使う場面でいうと重複を省いてその人が持っている属性を数える時に使います。
なのでCOUNTと一緒に使うことが多いですね
そしてこのDISTINCTは挙動がちょっとややこしいので例を出しながら説明すると
例えば以下のようなテーブルがあったとします(決して田村の一週間の献立とかじゃないですよ)
| shop | food |
|---|---|
| バーガー屋 | ハンバーガー |
| 焼き肉 | 牛タン |
| ラーメン | 醤油ラーメン |
| ラーメン | 牛タン |
| バーガー屋 | ハンバーガー |
| バーガー屋 | チキンバーガー |
| うどん | ぶっかけうどん |
こいつを以下の形で取ろうとすると
SELECT
DISTINCT shop
,food
FROM
test_table
重複除外されるのはshopとfoodが一致している「バーガー屋 ハンバーガー」のみになります。
実際にまとめてみると「そりゃそうじゃ」ってなるのですが、実際使ってみると「なんで数値おかしいんだろう・・」みたいなことになるので要注意です。
この場合ですと
何店舗で食べたかを抽出するなら COUNT(DISTINCT shop)
店舗の商品を何種類食べたかを抽出するなら COUNT(DISTINCT shop, food)
という感じで使い分けます。
まとめ
MySQL初心者が1年間でデータ抽出をする時によく使った関数について紹介しました。いかがでしたか?
「この関数知ってたけどこういう用途で使われるんだな」って言うのが少しでも伝わったら幸いです。
この記事が少しでも良かったと思ったらLGTMと他の日のアドベントカレンダーの記事を見ていただたいです!
さて、明日は我らがリーダーのミズノさん(@mizno)にバトンを渡します!
最終日どんないい記事を書いてくれるか期待大ですね>ω</