このブログでは、過去作成したブログのモデルの部分を畳み込みニューラルネットワーク(CNN)に変更して、多値分類を行う方法について解説します。
データの準備
以下のコードでは、MNISTデータセットを読み込み、前処理を行っています。
from torchvision import datasets, transforms
transformation = transforms.Compose([transforms.ToTensor()])
train_dataset = datasets.MNIST('data', train=True, transform=transformation, download=True)
test_dataset = datasets.MNIST('data', train=False, transform=transformation, download=True)
train_dataloader = torch.utils.data.DataLoader(train_dataset, batch_size=64, shuffle=True)
test_dataloader = torch.utils.data.DataLoader(test_dataset, batch_size=64)
-
transforms.ToTensor(): データをテンソル形式に変換し、ピクセル値を0~1に正規化します -
DataLoader: データセットを小分け(バッチ)で扱えるようにするクラスです
CNNモデルの構造
モデル定義
以下がCNNモデルの定義部分です。
class Model(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(1, 6, 5) # 入力チャンネル1、出力チャンネル6、カーネルサイズ5x5
self.conv2 = nn.Conv2d(6, 16, 5) # 入力チャンネル6、出力チャンネル16、カーネルサイズ5x5
self.pool = nn.MaxPool2d(2) # 2x2の最大プーリング層
self.linear_1 = nn.Linear(16*4*4, 256) # 平坦化された特徴量を256次元に変換
self.linear_2 = nn.Linear(256, 10) # 出力クラス数10(0〜9)
層ごとの詳細
-
Conv2d:
CNN層(畳み込み層)。画像から特徴を抽出します。(1, 6, 5)は次の意味を持ちます:- 入力チャンネル数: グレースケール画像のため1
- 出力チャンネル数: 6つのフィルタを適用
- カーネルサイズ: 5x5のフィルタを使用
-
MaxPool2d:
プーリング層。特徴マップのサイズを小さくして計算量を削減します。2x2のフィルタで最大値を取得 -
Linear:
全結合層。畳み込みとプーリングで抽出した特徴を分類器に渡します
フォワードパス
次に、データがどのように処理されるかを見ていきます。
def forward(self, x):
x = F.relu(self.conv1(x)) # 畳み込み層1 + ReLU
x = self.pool(x) # プーリング層1
x = F.relu(self.conv2(x)) # 畳み込み層2 + ReLU
x = self.pool(x) # プーリング層2
# print(x.size())
# torch.Size([64, 16, 4, 4])
x = x.view(-1, 16*4*4) # データを1次元に整形
x = F.relu(self.linear_1(x)) # 全結合層1 + ReLU
logits = self.linear_2(x) # 全結合層2
return logits
重要なポイント
- ReLU関数: 負の値を0に置き換えることで、非線形性を導入します
-
x.view(-1, 16*4*4): データを1次元に整形します。ここでのパラメーターはx.size()の出力でわかります
トレーニングループ
def train(dataloader, model, loss_fn, optimizer):
total_loss, total_correct = 0, 0
model.train()
for x, y in dataloader:
x, y = x.to(device), y.to(device)
y_pred = model(x)
loss = loss_fn(y_pred, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
with torch.no_grad():
total_correct += (y_pred.argmax(1) == y).type(torch.float).sum().item()
total_loss += loss.item()
return total_correct / len(dataloader.dataset), total_loss / len(dataloader)
実行例
モデルを学習させ、損失と精度を可視化します。
epochs = 10
train_loss, train_acc, test_loss, test_acc = fit(epochs, train_dataloader, test_dataloader, model, loss_fn, optimizer)
出力ログ:
epoch: 0, train loss: 0.24114, train acc: 92.7%, test loss: 0.07422, test acc: 97.8%
epoch: 1, train loss: 0.06535, train acc: 98.0%, test loss: 0.04346, test acc: 98.5%
epoch: 2, train loss: 0.04610, train acc: 98.5%, test loss: 0.04457, test acc: 98.5%
epoch: 3, train loss: 0.03605, train acc: 98.9%, test loss: 0.03183, test acc: 98.8%
epoch: 4, train loss: 0.02945, train acc: 99.0%, test loss: 0.03241, test acc: 99.0%
epoch: 5, train loss: 0.02325, train acc: 99.2%, test loss: 0.03362, test acc: 98.9%
epoch: 6, train loss: 0.02022, train acc: 99.4%, test loss: 0.02977, test acc: 99.1%
epoch: 7, train loss: 0.01768, train acc: 99.4%, test loss: 0.03135, test acc: 99.0%
epoch: 8, train loss: 0.01431, train acc: 99.5%, test loss: 0.03510, test acc: 99.0%
epoch: 9, train loss: 0.01217, train acc: 99.6%, test loss: 0.03852, test acc: 98.8%
Done
学習の進行をグラフで確認することで、モデルの性能を評価します。
plt.plot(range(epochs), train_loss, label="train_loss")
plt.plot(range(epochs), test_loss, label="test_loss")
plt.legend()
plt.show()
plt.plot(range(epochs), train_acc, label="train_acc")
plt.plot(range(epochs), test_acc, label="test_acc")
plt.legend()
plt.show()
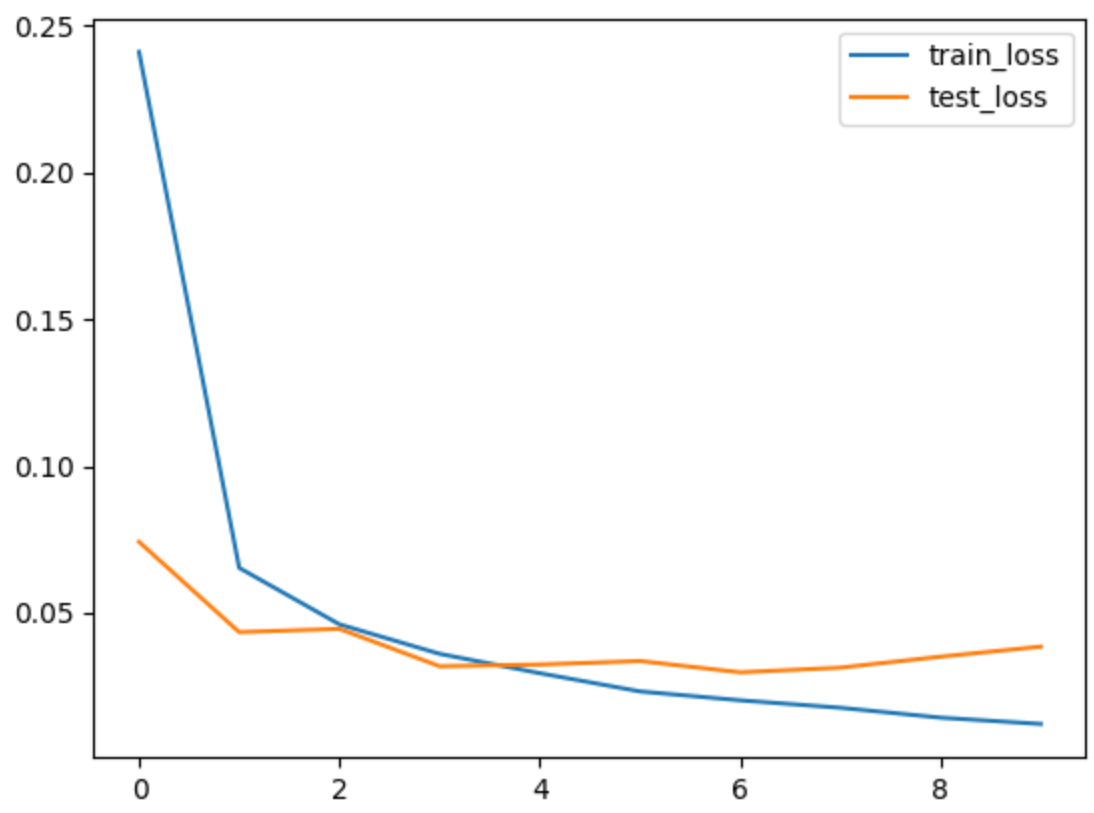
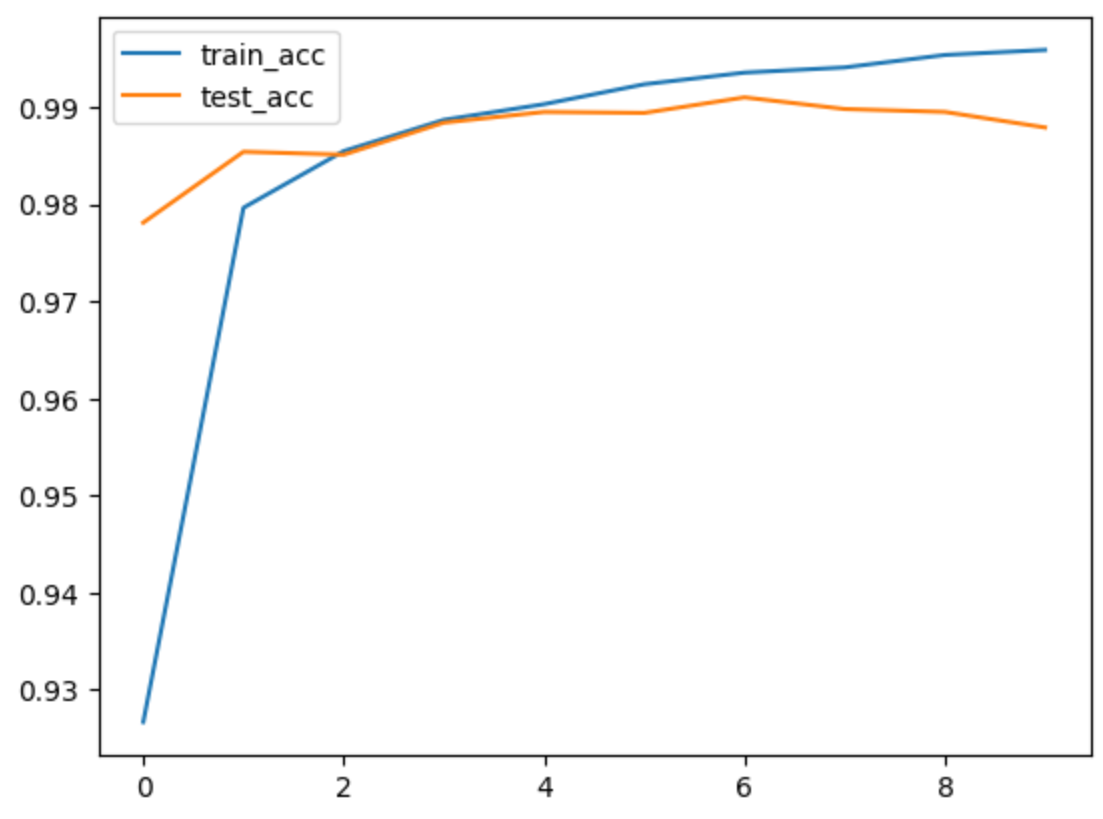
図を見てみると、3epoch以後オーバーフィットが発生、3epochの結果がベストです。
おわりに
CNNを用いた多値分類の基本的な実装を初心者向けに解説しました。MNISTのような単純なデータセットではありますが、実際の応用では、この構造を複雑化してより高度なタスクに対応することが可能です。ぜひ試してみてください!