みなさんこんにちは!
はじめに
Databricks には Delta Live Tables というETL処理用のフレームワークがあり、その機能の1つとしてストリーミングデータを扱えるストリーミングテーブルがサポートされています。
ストリーミングテーブルは Kafka 等のデータソースから送られてきたデータをパイプライン実行のタイミングで取り込み、新しく到着したデータのみをテーブルに追加していくことができます。ストリーミングテーブルにより、リアルタイム性の高い処理を高い信頼性で実現することができます。
本記事では、ストリーミングテーブルを利用したデータ取り込み方法について、実際の例とともに詳しくご紹介していきます。
※本記事では Azure Databricks を使用しています。
Azure Event Hubs からのデータ取り込み
Apache Kafka を利用可能なデータストリーミングサービスである Azure Event Hubs からデータ取り込みを行ってみます。
1. Azure Event Hubs 設定
データストリーミング用に Event Hubs の設定を行います。
Event Hubs 名前空間の設定やローカル環境からのメッセージ送受信方法については以下の記事をご参照ください。
Azure Event Hubs のセットアップ方法&ストリーミング基本操作
2. 情報取得
Delta Live Tables パイプライン実行の際に必要となる以下の情報を取得しておきます。
- Event Hubs 名前空間
- Event Hubs トピック名
- 接続文字列
Event Hubs 名前空間は Event Hubs名前空間自体の名前です。
Event Hubs トピック名はデータ取得対象のトピック名です。
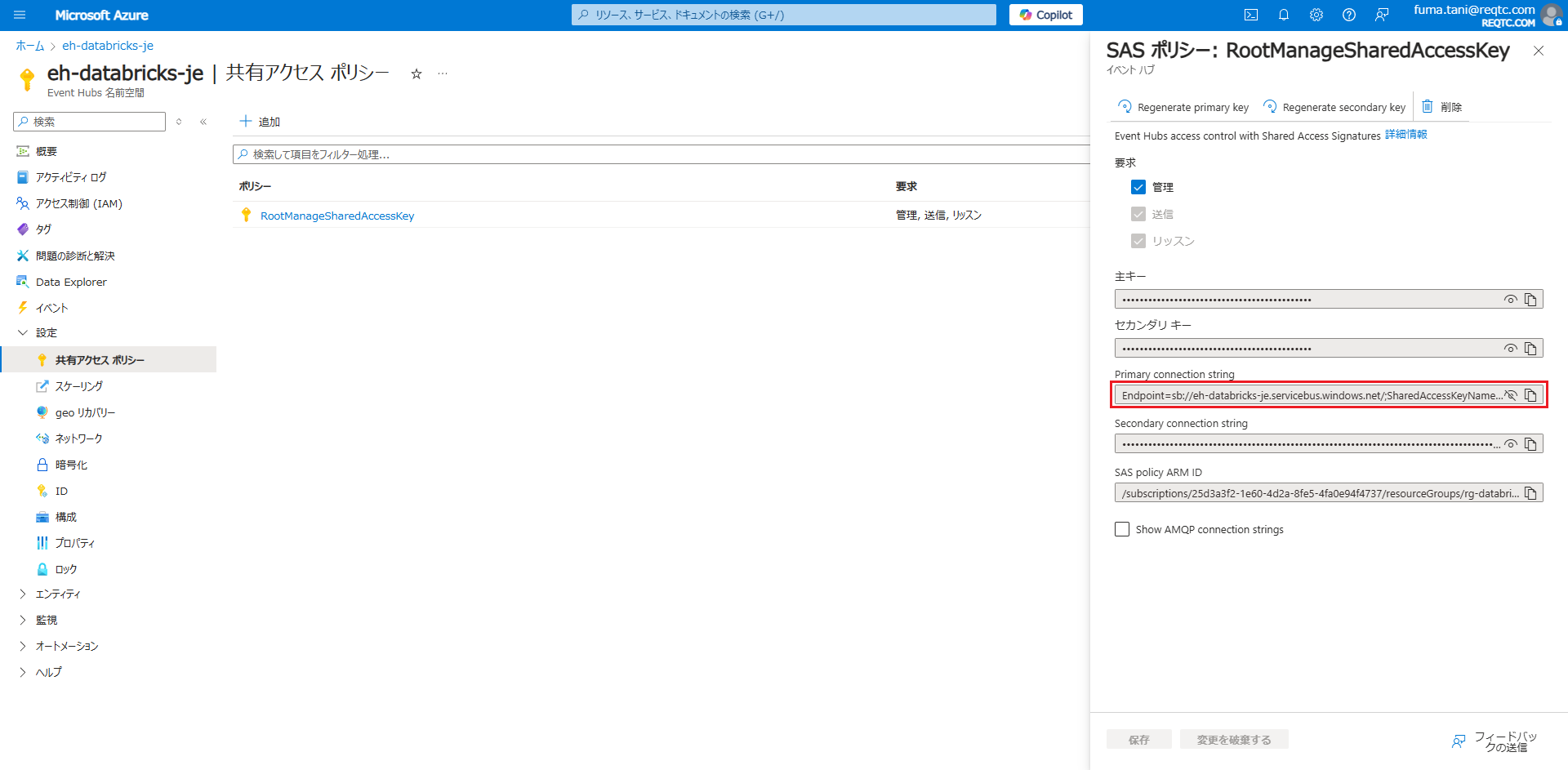
接続文字列は Event Hubs 名前空間の「設定」→「共有アクセスポリシー」→「RootManageSharedAccessKey」の「Primary connection string」の文字列です。
3. パイプライン作成
Databricks に戻り、ノートブックを開きます。
以下の Python コードをノートブックにコピー&ペーストし、設定情報部分を書き換えます。
import dlt
from pyspark.sql.functions import *
from pyspark.sql.types import *
# 設定情報
# ------------------------------
event_hubs_namespace = "<Event Hubs 名前空間>"
event_hubs_topic = "<Event Hubs トピック名>"
connection_string = "<接続文字列>"
# ------------------------------
kafka_options = {
"kafka.bootstrap.servers": f"{event_hubs_namespace}.servicebus.windows.net:9093",
"kafka.sasl.jaas.config": f"kafkashaded.org.apache.kafka.common.security.plain.PlainLoginModule required username='$ConnectionString' password='{connection_string}';",
"subscribe": event_hubs_topic,
"kafka.security.protocol": "SASL_SSL",
"kafka.sasl.mechanism": "PLAIN",
"startingOffsets": "earliest"
}
@dlt.table(
comment="Raw Kafka events.",
table_properties={
"pipelines.reset.allowed": "false"
}
)
def kafka_bronze():
return (
spark.readStream
.format("kafka")
.options(**kafka_options)
.load()
)
event_schema = StructType([
StructField("id", StringType(), True),
StructField("name", StringType(), True)
])
@dlt.table(
comment="Real schema for Kafka payload.",
)
def kafka_silver():
return (
dlt.read_stream("kafka_bronze")
.select(col("timestamp"), from_json(col("value").cast("string"), event_schema).alias("event"))
.select("timestamp", "event.*")
)
上記コードでは Azure Event Hubs から受け取った生データを kafkabronze テーブルに格納し、kafkabronze から抽出した実際のペイロードとタイムスタンプを kafka_silver テーブルに格納します。
次に、メニューの「パイプライン」からパイプラインの作成を行います。
パイプラインの設定は以下の通りです。ソースコードの「パス」には先ほど作成したノートブックのパスを指定します。

※今回は簡単のためサーバレスを使用しています。従来通り自分でクラスターの設定を行う形でも問題ありません。
「開始」でパイプラインを起動します。
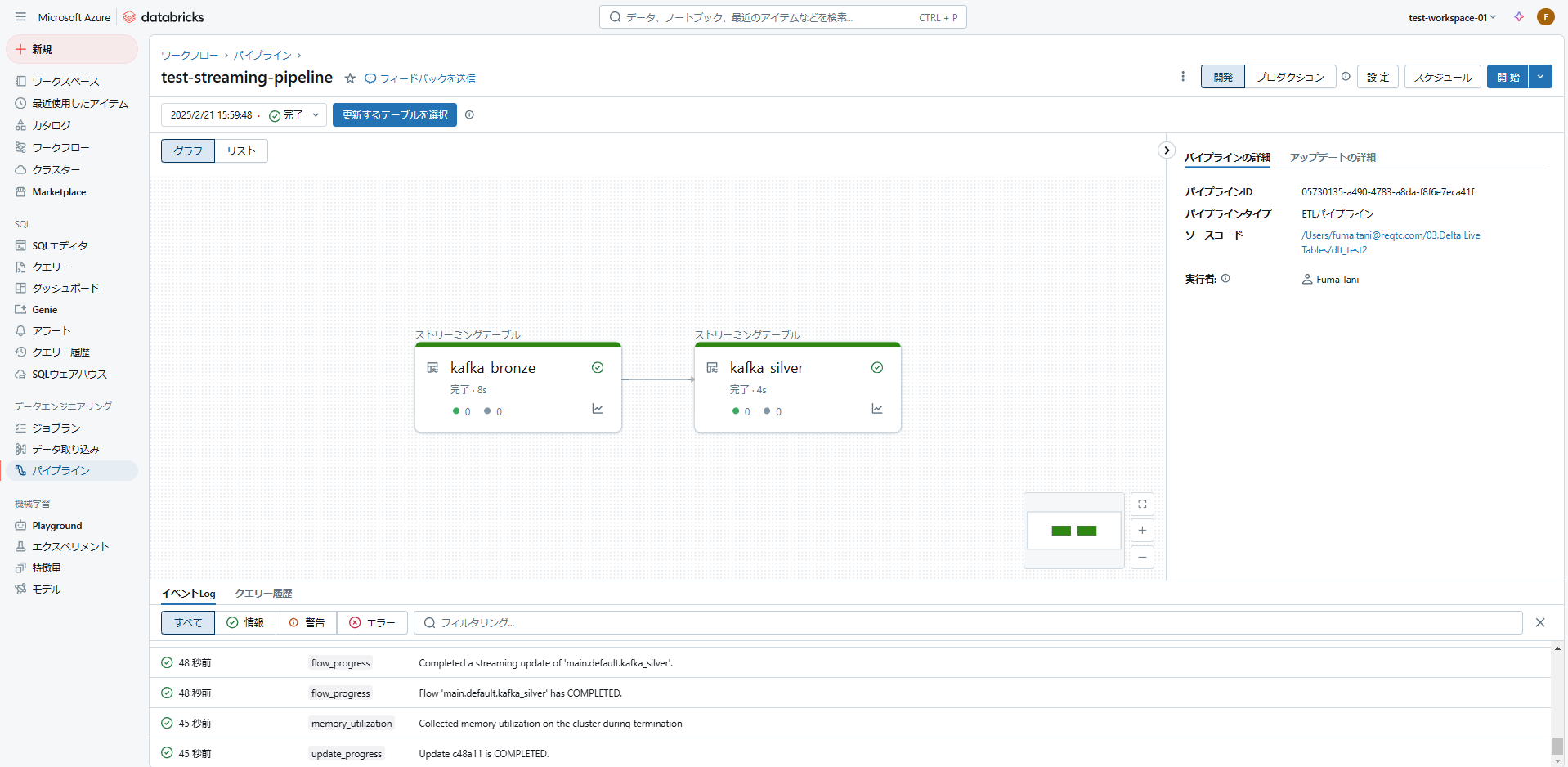
実行が完了すると、画像のようにテーブルの処理を可視化したグラフが表示されます。
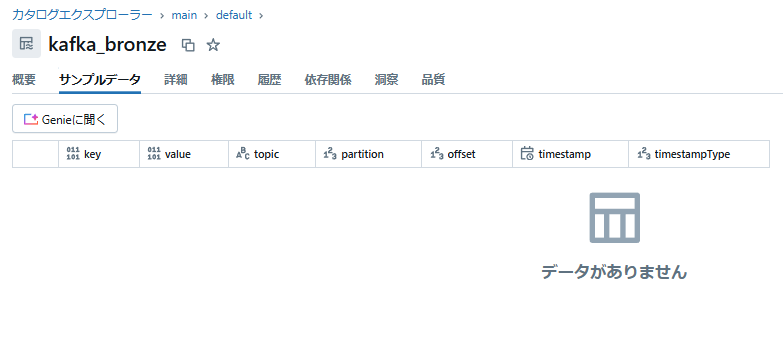
カタログを確認すると、プログラムで定義した2つのテーブルが作成されていることが確認できます。 現時点で対象トピックにはデータを送信していないため、データなしの状態です。
4. 動作確認
Event Hubs のデータ取り込み対象トピックにデータを送信します。

再度、パイプラインを実行します。
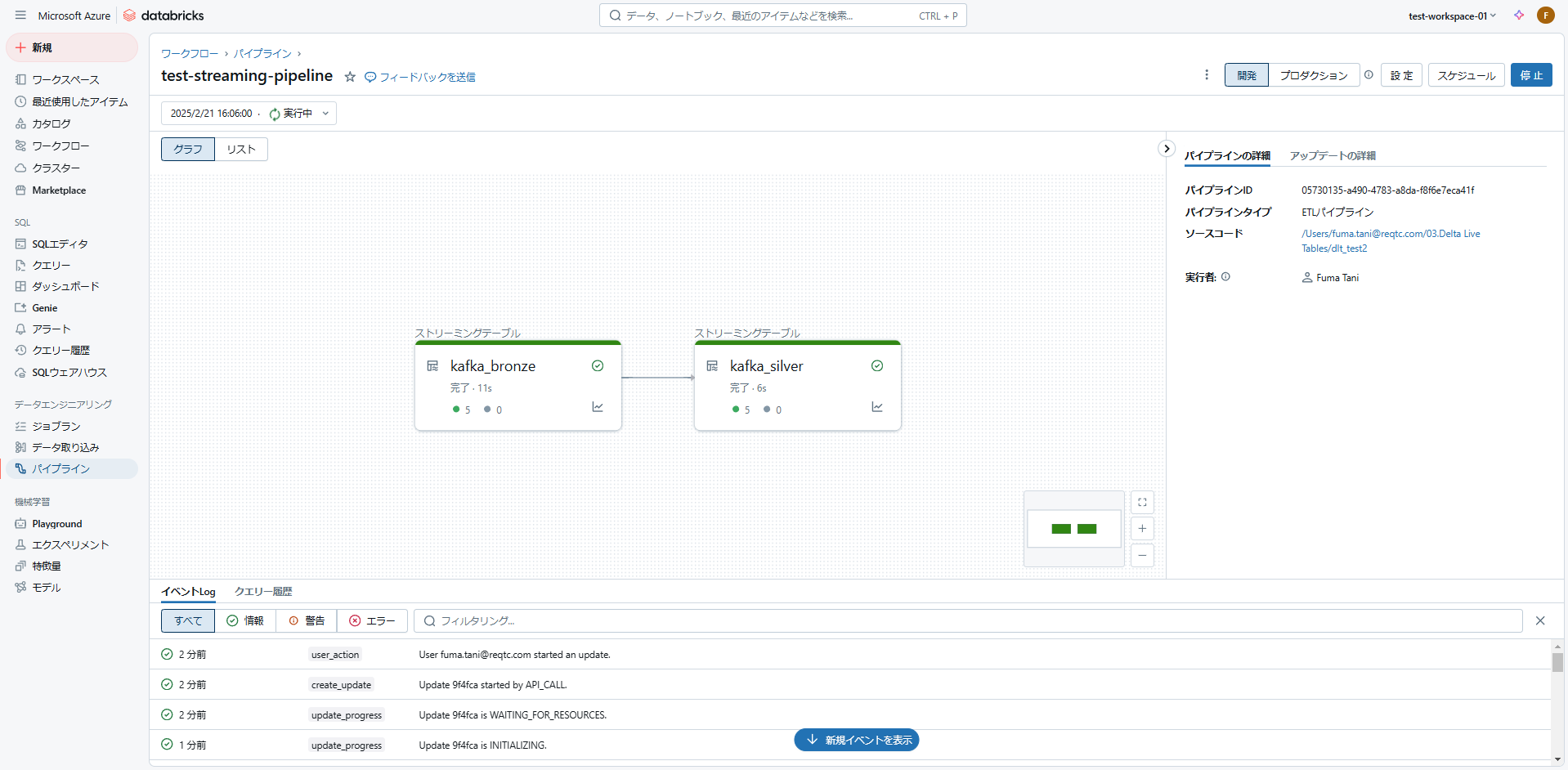
パイプラインの実行が完了しました。

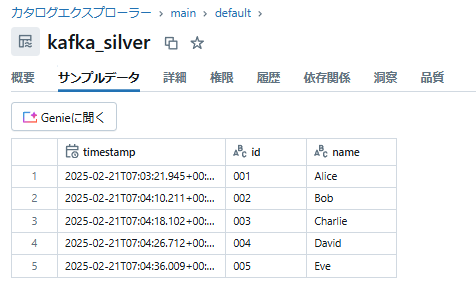
2つのテーブルに意図した通りデータが入っていることが確認できます。
オブジェクトストレージからのデータ取り込み
今度はオブジェクトストレージから、Auto Loader を利用してデータ取り込みを行ってみます。
Auto Loader はクラウドストレージ上にあるデータの増分取り込みを行うための機能です。指定されたフォルダ配下のファイル追加を自動的に検出し、新規到着分のデータのみを取り込みます。
1. パイプライン作成
以下の Python プログラムをノートブックにコピー&ペーストします。
import dlt
# 入力ファイルパス
path = "dbfs:/FileStore/tables/comments/"
@dlt.table(
comment="Raw comment data."
)
def comments_bronze():
return (
spark.readStream.format("cloudFiles")
.option("cloudFiles.format", "json")
.load(path)
)
上記の例では、DBFS の tables/comments フォルダ直下に置いたファイルを対象にデータ取り込み処理を行います。
cloudFiles は Auto Loader 機能を利用する際に指定する設定オプションであり、option() でファイル形式の指定を行います。
パイプラインは Event Hubs からのデータ取り込みの場合と同様に設定します。
2. 動作確認
DBFS の tables/comments に以下の内容のサンプルファイルをアップロードします。
comments_1.txt
{"id": "C0001", "sender": "Alice", "comment": "Hello."}
{"id": "C0002", "sender": "Bob", "comment": "Hi!"}
{"id": "C0003", "sender": "Charlie", "comment": "I'm sleepy."}

パイプラインを実行します。
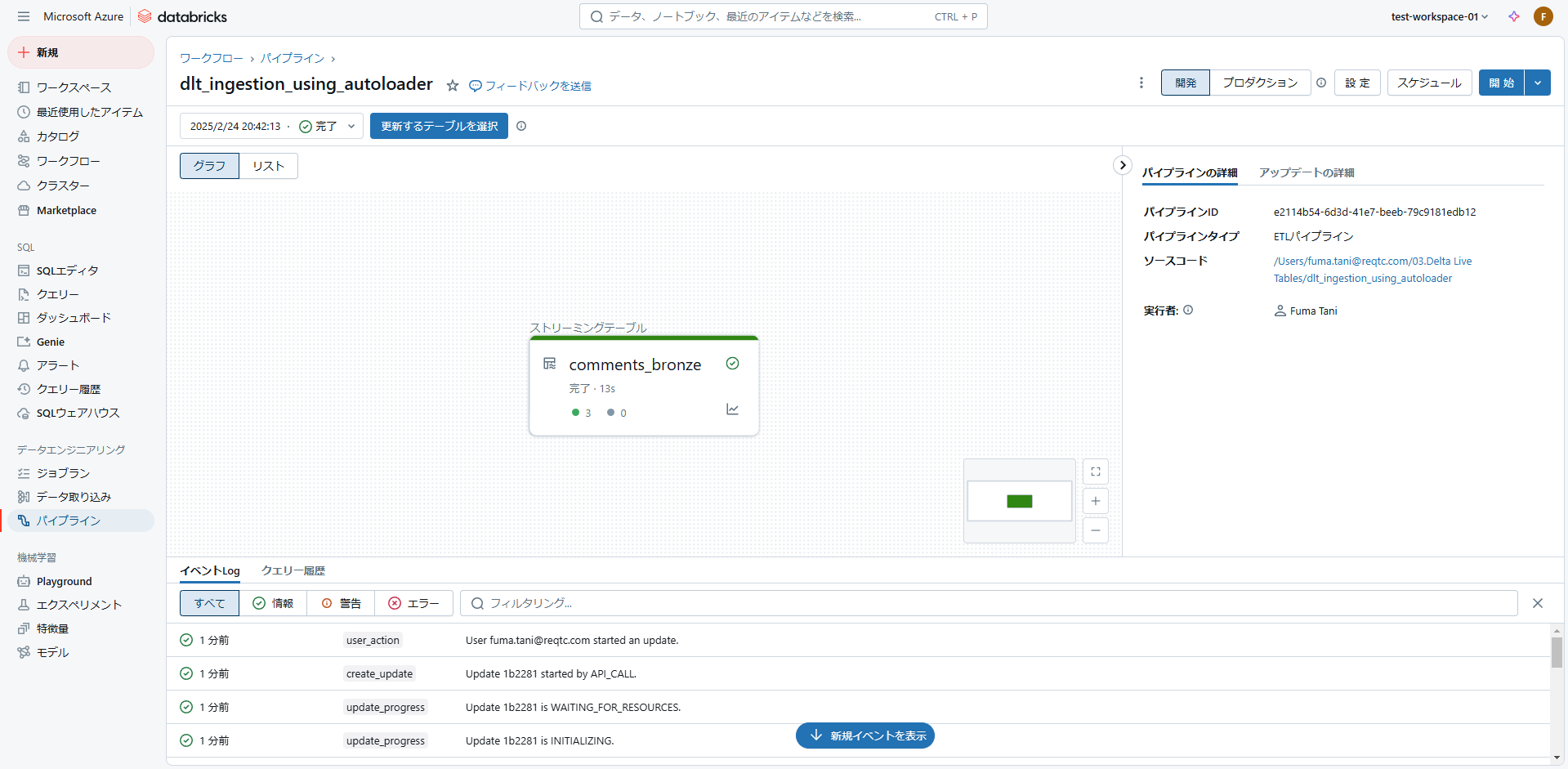
テーブルにファイルと同じ内容のデータが入っていることが確認できます。

次に、以下のファイルをアップロードします。
comments_2.txt
{"id": "C0004", "sender": "David", "comment": "Hello."}
{"id": "C0005", "sender": "Eve", "comment": "I'm so hungry."}
再度パイプラインを実行します。

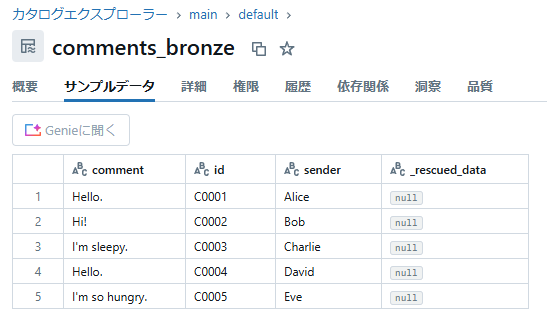
2つ目のファイルの内容が追加されていることが確認できます。
さいごに
ストリーミングテーブルの基本と使い方について、実際の例とともに詳しく見てきました。
いざ Databricks でストリーミングをやってみよう!と思っても基本的な使い方がよくわからず、資料を調べるところから始まる・・・ということは多いかと思いますが、本記事で少しでも具体的なイメージを掴んでいただけたら幸いです。