【はじめに】
皆さん、こんにちは。いつもの外人の機械学習エンジニアです。今回の記事は実際やってみたスクリプトをご紹介させて頂きます。特に学習させたりモデルを利用してたりことではなく既にあるものを利用しただけなのでご理解お願い致します。では始めます。
処理の流れ
- PDF→IMG(JPEG,PNG)で変換
- IMGファイルをOCR処理に入れて結果をCSVファイルとして保存
- CSVファイルから文字列を読み込んでNLP処理に回す。
実際の作業スクリプト
1. PDF認識
pdf_recognition.py
# coding : utf-8
import cv2
import argparse
import numpy as np
from PIL import Image
from setting import *
from utils import pdf_to_image, utils_zip, create_config
if __name__ == "__main__":
parser = argparse.ArgumentParser(description='PDF To Images Test')
parser.add_argument("pdf_file_path", default=PDF_FILE_PATH+FILE_NAME, nargs='?', help='Input the images')
args = parser.parse_args()
try:
file_name = FILE_NAME.split(".")
file_name = file_name[0]
# 対象のPDFファイルを画像に変換
pdf_to_image.pdf2images(FILE_NAME=file_name, PDF_FILE_PATH=args.pdf_file_path, IMG_FILE_PATH=IMAGE_FILE_PATH)
# IMGで変換されたファイルをZIPファイルとして保存
utils_zip.create_zip(FILE_NAME=file_name, IMAGE_FILE_PATH=IMAGE_FILE_PATH, IMAGE_ZIP_PATH=IMG_ZIP_PATH)
# ファイルの情報をCONFIGファイルとして保存
create_config.create_json(FILE_NAME=file_name, JSON_CONFIG_PATH=JSON_CONFIG_FILE_PATH, IMAGE_ZIP_PATH=IMG_ZIP_PATH, IMAGE_UNZIP_PATH=IMG_UNZIP_PATH)
except Exception as e:
print(e)
処理としては
1. まずIMGで変換したい対象のファイルをparserでパス設定します。
2. そのパスをpdf2images, create_zip, create_jsonの処理に回すと結果は以下になります。
ちなみにCONFIGファイルはこんな形式です。
json_config
{
"read_data": {
"image_zip_path": "C:\\Users\\user\\opencv\\nlp\\images\\images_zip\\",
"image_unzip_path": "C:\\Users\\user\\opencv\\nlp\\images\\images_unzip\\"
},
"file_info": {
"file_name": "sample_pdf"
}
}
2. IMG OCR
image_ocr.py
# coding:UTF-8
import sys
import cv2
import json
import argparse
import sys
import csv
import pyocr
import pyocr.builders
import pandas as pd
from PIL import Image
from setting import *
from utils import utils_zip
if __name__ == "__main__":
# setting OCR Parameter
parser = argparse.ArgumentParser(description='tesseract oct test')
parser.add_argument("image_json_config", default=JSON_CONFIG_FILE_PATH +JSON_CONFIG_FILE_NAME,
nargs='?', help='read image json config file')
args = parser.parse_args()
tools = pyocr.get_available_tools()
try :
# jsonファイルから物体認識された結果のデータを読み込み
with(open(args.image_json_config, 'r')) as json_config:
json_data = json.load(json_config)
# 処理の対象のファイル名
FILE_NAME = json_data["file_info"].get("file_name", "sample")
# ファイルをイメージ化してzip形式に変換したデータ
IMAGE_ZIP_PATH = json_data["read_data"].get("image_zip_path", "sample")
IMAGE_UNZIP_PATH = json_data["read_data"].get("image_unzip_path", "sample")
image_zip_array = []
# イメージのzipファイルを解凍
image_zip_array.append(utils_zip.image_unzip(FILE_NAME=FILE_NAME, IMAGE_ZIP_PATH=IMAGE_ZIP_PATH, IMAGE_UNZIP_PATH=IMAGE_UNZIP_PATH))
# zipファイルが存在しないまま既に画像ファイルが存在する時
# image_unzip_array = ["1"]
if len(image_zip_array) >= 1:
# unzipファイルの中身を確認
image_file_array = utils_zip.image_unzip_file_check(FILE_NAME=FILE_NAME, IMAGE_UNZIP_PATH=IMAGE_UNZIP_PATH)
for item in image_file_array:
if len(tools) == 0:
print("no OCR tool found")
sys.exit(1)
tool = tools[0]
print("Will use tool '%s'" % (tool.get_name()))
langs = tool.get_available_languages()
print("Available languages: %s" % ", ".join(langs))
lang = langs[2]
print("Will use lang '%s'" % (lang))
txt = tool.image_to_string(
Image.open(item),
lang="jpn",
builder=pyocr.builders.TextBuilder(tesseract_layout=6)
)
df = pd.DataFrame([[txt]], columns = ["word"])
df.to_csv(OCR_CSV_FILE_PATH + FILE_NAME + ".csv", encoding="cp932", mode="a", header=False, index=False)
# utils_zip.image_delete(IMAGE_UNZIP_PATH=IMAGE_UNZIP_PATH)
except Exception as e:
print(e)
前のpdf_recognition.pyのスクリプトの結果となる.zipファイル,configファイルがこの処理のINPUTデータとして使われます。この処理を回すとNLP処理に必要なcsvファイルが作られます。
3. NLP(Mecab)
nlp_mecab.py
# coding:UTF-8
import sys
import cv2
import glob
import json
import argparse
import csv
from setting import *
from pipeline import *
if __name__ == "__main__":
# setting OCR Parameter
parser = argparse.ArgumentParser(description='tesseract oct test')
parser.add_argument("ocr_read_file_name", default=OCR_CSV_FILE_PATH,
nargs='?', help='read in ocr_csc_file')
parser.add_argument("image_json_config", default=JSON_CONFIG_FILE_PATH + JSON_CONFIG_FILE_NAME,
nargs='?', help='read image json config file')
args = parser.parse_args()
try :
# jsonファイルから物体認識された結果のデータを読み込み
with(open(args.image_json_config, 'r')) as json_config:
json_data = json.load(json_config)
# 処理の対象のファイル名
FILE_NAME = json_data["file_info"].get("file_name", "sample")
for item in glob.glob(args.ocr_read_file_name + "\\*.csv"):
# csvファイルから文章を読み込み
with(open(item, 'r')) as csv_read_file:
OCR_CSV_FILE_READER = csv_read_file.read()
pipeline_parse = parse(OCR_CSV_FILE_READER)
word = pipeline_parse.sentense_parse()
pipeline_csvfile = csvfile(NLP_RESULT_CSV_FILE_PATH + FILE_NAME + ".csv", word)
pipeline_csvfile.create_csvfile()
# pipeline_parts = parts_of_word(args.ocr_write_file_name, word)
# pipeline_parts.devide_word()
except Exception as e:
print(e)
この全体の流れの結果として得られるのがこちらのCSVファイルです。
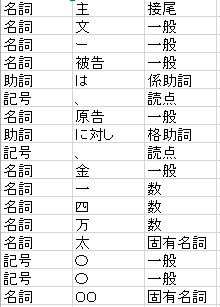
こういう感じで日本語の文書を処理します。精度が高いとは言えないですけど自分が予想したことより高く出たのでそれで満足しています。
【まとめ】
実際このスクリプトを作ったのが結構前で現在はこの処理に学習を追加する作業を行っています。やっぱWindowsではちょっと不便なことがあるのでOSもUbuntuで変更した部分もあります。学習の処理まで終わったらまた更新しますので少々お待ちください。