はじめに
こんにちは、皆さん!@Raphael_de_murlです。今回は機械学習やデータサイエンスの処理でよく使われるライブラリをご紹介したいと思います。
scikit-learnとは

以下はscikit-learn - Wikipediaの定義です。
scikit-learn (旧称:scikits.learn) はPythonのオープンソース機械学習ライブラリである。サポートベクターマシン、ランダムフォレスト、Gradient Boosting、k近傍法、DBSCANなどを含む様々な分類、回帰、クラスタリングアルゴリズムを備えており、Pythonの数値計算ライブラリのNumPyとSciPyとやり取りするよう設計されている。
結構目に慣れたライブラリ名が見えてますね。説明の通りscikit-learnはSVMとかRandom Forestとかk近傍法とか色んな機械学習関連のライブラリとよく使われてますので基本からしっかり身につける必要がありますと思ってます。
scikit-learnの特徴
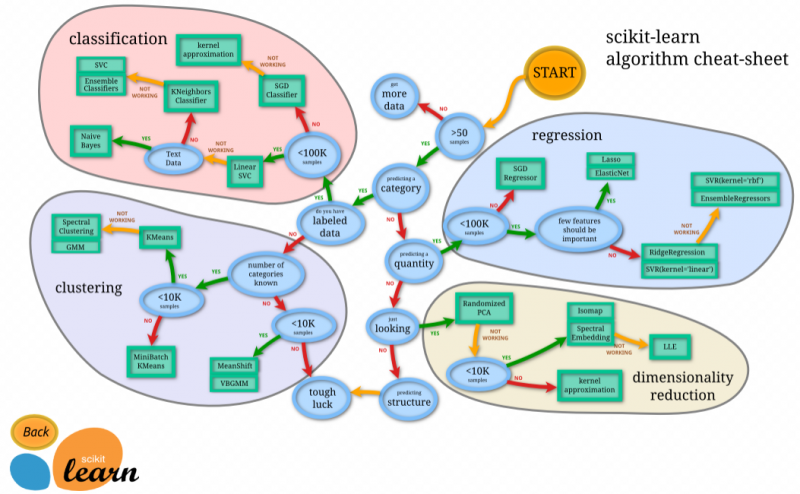 scikit-learn アルゴリズム・チートシート
scikit-learn アルゴリズム・チートシート
上記のの画像はscikit-learnのアルゴリズムチートシートです。多分機械学習を勉強している方や現役で使っている方はよく見た画像だと思います。これらは機械学習を行う際、やりたい処理に対しどのモデルを選んでやるのかをscikit-learnがサポートしてくれるっていう風に理解すれば大丈夫だと思います。この4つの分析を軽く見てみます。
classification(分類)は2つ以上の離散カテゴリへの分類ラベルを予測するモデルとしてクラス分類問題や教師あり学習で使われます。
- SGD classifier
- 大規模のデータの線形のクラス分類手法です。
- Linear SVC
- SGDよりは小さな中小規模のデータの線形のクラス分類手法です。
- KNeighbors Classifier
- こちらはLinear SVCでうまく分類ができてなかった場合に利用する非線形クラス分類手法で中小規模のデータを扱います。
- kernel approximation
- こちらはSGDでうまく分類ができてなかった場合に利用する非線形クラス分類手法で中小規模のデータを扱います。
regression(回帰)は連続ラベルを予測するモデルとして教師あり学習で使われます。
- SGD regressor
- 大規模のデータの線形の回帰分析の手法です。
- Lasso、ElasticNet
- 中小規模で説明変数の一部が重要な場合に使われる、回帰分析の手法です。
- RidgeRegression、SVR(kernel=linear)
- 中小規模で説明変数の全てが重要な場合に使われる、回帰分析の手法です。
- SVR(kernel)、EnsembleRegression
- こちらはRidge回帰やSVR(linear)で分析がうまくできなかった場合に利用する非線形の分析手法です。
clustering(クラスタリング)はデータ内のグループを検出して識別するモデルとしてラベルなしデータのラベルを推定する教師なし学習で使われます。
- KMeans
- いくつのクラスタに分かれるのか、事前に決めることができる場合におすすめな、クラスタリング分析手法です。
- Special Clustering、GMM
- KMeansでうまくクラスタリングが出来なかった場合に利用する非線形の分析手法です。
- Meanshift、VBGMM
- こちらはKMeansとは逆でクラスタに分かれるのか、決める事が出来ない場合に利用するクラスタリンくの分析手法です。
- MiniBatch KMeans
- こちらはデータが大規模の場合に使われるKMeansとしてデータを分けながら学習させる手法です。
dimentionality reduction(次元削減)はより高次元データ内の低次元構造を検出し識別するモデルとしてラベルなしデータの構造を推定する教師なし学習で使われます。
- Randomized PCA
- 多次元のデータから「意味のある特徴量」を特定したり、新たな軸を作る(基底を変換する)ことで、少ない変数でデータを再現します。
- Isomap, Spectral Embedding
- PCAが機能しない非線形な構造を持つデータにおいて、データ数が膨大でない場合に使用されます。
- LLE
- 非線形な構造を持つデータにおいて、Isomapがうまくいかない場合に、LLEが使用されます。
- kernel appoximation
- カーネルトリックを用いて、データを非線形変換した後にPCAを実施する方法です。
まとめに
説明が綺麗ではないんですけれども如何でしたでしょうか?いつも思うんですが大きな目的は皆さんと情報を共有したい!という気持ちでやっていますがまずが自分が勉強するための記事でもありますのでこれをご理解頂ければと思っております。次回は実際scikit-learnを用いた簡単な例をやって行きたいと思います。この記事が少しでも気に入った方はいいねとツイッターのフォロワー宜しくお願い致します。