【はじめに】
皆さん、こんにちは。機械学習エンジニアの外人です。今日は少し基本的な話になる感じで行きたいと思います。それが何かというとAIや機械学習そして深層学習についてのお話です。機械学習エンジニアというタイトルを付けて約1年なのに何で今更記事に載せるのと思う方もいらっしゃると思います。はい。まだ自分の中で整理ができていません。なのでこれをきっかけで整理しながら皆さんと情報共有したいです。じゃあ、では行きます。
構造図
まず、今回ご紹介する3つの技術の構成はこんな感じです。

この構成をご存知ではない方はこれを見て【結局全部AIじゃない?】と思われるかもしれません。まぁーこの図だけ見るとそうなりますよね。でも違います。【じゃあ、何が違います?】と言われるとお答え致します。以下にこの3つの説明をします。
AIとは
- AIのウィキペディアから引用します。
人工知能(じんこうちのう、英: artificial intelligence、AI)とは、「「計算(computation)」という概念と「コンピュータ(computer)」という道具を用いて「知能」を研究する計算機科学(computer science)の一分野」を指す語。「言語の理解や推論、問題解決などの知的行動を人間に代わってコンピューターに行わせる技術」、または、「計算機(コンピュータ)による知的な情報処理システムの設計や実現に関する研究分野」ともされる。
計算がなんちゃら…って書いてあるけど一言です。人間の脳をまねしたコンピュータです。もうちょっと説明すると人間の脳で可能な計算能力をコンピュータでもできるように作られたシステムです。この説明だけを読んでわかった方もいると思います。そうAI=ロボットこれは違います。説明した通AIは人間の脳をまねしたシステムです。ロボットだったら昔の【勇者警察ジェイデッカー】の超AIのメモリですかね?ってことは人間から離れても自ら考え、ある問題に関する答えを探すことができるってことです。
ここでAIは2つのAIに分かれて行きます。強いAI、弱いAIこの2つを軽く説明します。
- 強いAI:ある枠を超えて考える人工知能のことで、人間のようにものを考え、認識・理解し、人間のような推論・価値判断のもとに実行をすることができるものを指します。
- 弱いAI:ある枠の範囲で考える人工知能のことで、ある一定の範囲では既に人間のレベルを超えてきています。
機械学習とは
機械学習は別名【マシンラーニング】と呼ばれており、人間が自然に行っている学習能力と同様のことをコンピュータでも実現しようとする技術や手法。簡単に言うとあるデータをコンピュータに学習させて問題の答えとか法則性を導くことです。
いわゆるモノを検知するとか株価の変化を予測するとかが機械学習の一つの分野であり、現在日本で一番流行っている分野じゃないかなと思われます。実際筆者が現場で画像処理や時系列を同時にやったこともあります。(自然言語は今勉強中です。)
そして次にご紹介するのが機械学習の特徴である学習の方法です。教師あり学習、教師ない学習、強化学習一般的に3つです。
- 教師あり学習のウィキペディアから引用します。
教師あり学習(きょうしありがくしゅう, 英: Supervised learning)とは、機械学習の手法の一つである。事前に与えられたデータをいわば「例題(=先生からの助言)」とみなして、それをガイドに学習(=データへの何らかのフィッティング)を行うところからこの名がある。
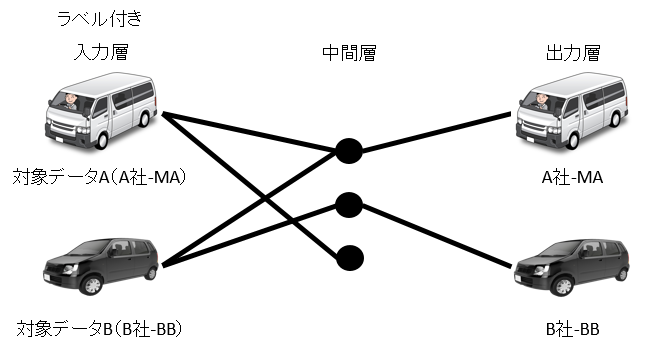
もっと簡単に言うと例えば【車の名前が知りたい】と言ったらその車の画像をデータ(入力層)として入れて名前を正解データ(出力層)で学習させる方法です。
- 教師ない学習のウィキペディアから引用します。
教師なし学習(きょうしなしがくしゅう, 英: Unsupervised Learning)とは、機械学習の手法の一つである。「出力すべきもの」があらかじめ決まっていないという点で教師あり学習とは大きく異なる。データの背後に存在する本質的な構造を抽出するために用いられる。
教師なし学習は教師あり学習は異なりラベル(正解データ)を付けずにそのまま学習させる方法です。普段はコンピュータにデータを読み込ませて特徴量を求めてそれに従って分類したり法則とかを解析させたりします。ここで教師なし学習の手法であるクラスタリングについて少しご説明します。
クラスタリング
色々なモノの似たもの同士集めてクループすることです。またクラスタリングは大量のデータを元にカテゴライズするのに適してます。
- K-means(k平均法)
k平均法のドキュメントから引用します。
k平均法(kへいきんほう、英: k-means clustering)は、非階層型クラスタリングのアルゴリズム。クラスタの平均を用い、与えられたクラスタ数k個に分類することから、MacQueen がこのように命名した。k-平均法(k-means)、c-平均法(c-means)とも呼ばれる。
k平均法に関してはこちらの記事が理解やすいと思うので参照してください。
結果一言で言うと各クラスタごとに分けて分類することですよね。
じゃあ、【そうしたら教師あり学習も、教師無し学習も同じ分類作業なのに何が違うの?】という疑問が生まれます。前も話した通り学習の方法が違います。簡単な例題で見てみましょう。
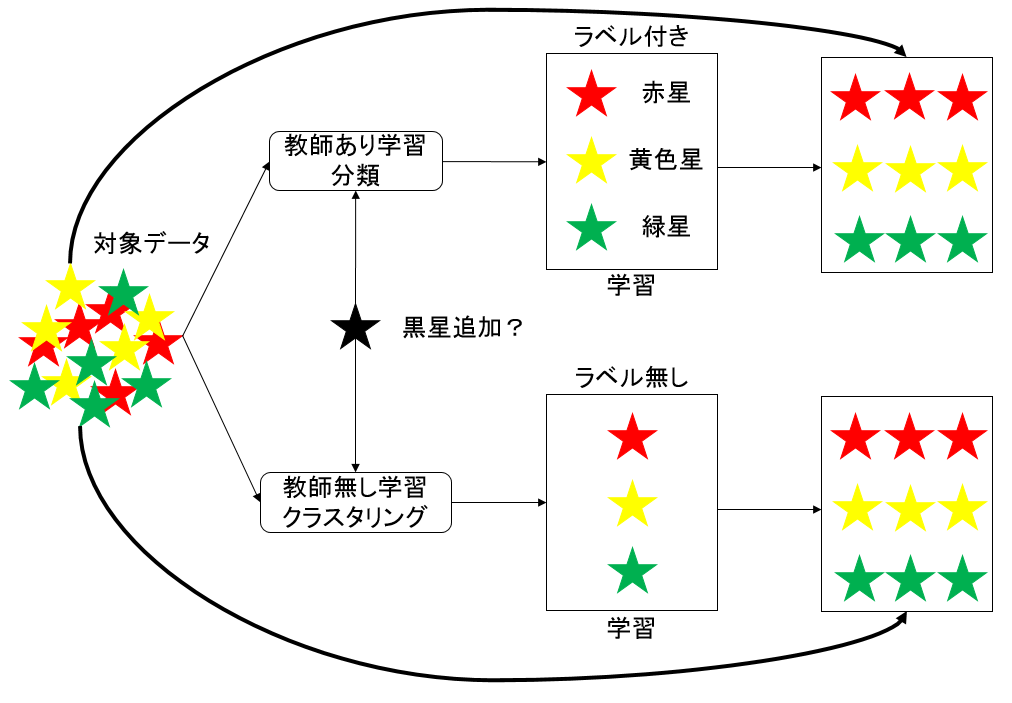
まず、3つの色の星のデータを準備します。
- 教師あり学習の分類の場合は各星の色のラベルを付けます。そして学習させます。
- 教師無し学習のクラスタリングの場合はからベルを付けずに学習させます。
ここで分類手法は付けられたラベルを元で学習させてその答えに導いてます。
逆にクラスタリング手法はラベルではなく、色に特徴量を元で色ごとに分けて分類して行きます。
こうなった場合写真の通り黒色の星を追加するとクラスタリングはその色の特徴量を抽出し、クラスを分けますが、分類の場合はラベルを付けないとあのデータの正解データが何かがわかりません。
深層学習とは
- 深層学習のウィキペディアから引用します。
ディープラーニングまたは深層学習(しんそうがくしゅう、英: deep learning)とは、(狭義には4層以上の)多層のニューラルネットワーク(ディープニューラルネットワーク、英: deep neural network)による機械学習手法である。深層学習登場以前、4層以上の深層ニューラルネットは、局所最適解や勾配消失などの技術的な問題によって十分学習させられず、性能も芳しくなかった。しかし、近年、ヒントンらによる多層ニューラルネットワークの学習の研究や、学習に必要な計算機の能力向上、および、Webの発達による訓練データ調達の容易化によって、十分学習させられるようになった。その結果、音声・画像・自然言語を対象とする問題に対し、他の手法を圧倒する高い性能を示し、2010年代に普及した。
【それで何が違うの?】というと機械学習は人がデータを入力すると機械自身が学習しますが、深層学習(ディープラーニング)は人の脳神経をまねして作られたコンピュータが自らデータを見て特に人の指示かなくてもどんどん学習させて行きます。
- ニューラルネットワーク図
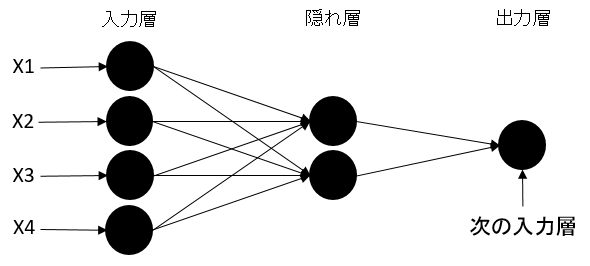
一番左層(入力層)にデータが入って中間の隠れ層を経由して一番右層(出力層)に行きます。そう行った出力層はまた次のニューロンの入力層になります。
【まとめ】
これだけでも長くなりますよね。できれば理解した内容を全部載せたいけどそうするととんでもなく長くなるので技術の概念ぐらいで載せます。もしこの記事を見ていた方々には説明が足りないところ申し訳ございません。ここでは概念だけわかった上で他の記事とかで深く勉強してみて下さい。そして筆者の記事に間違えた情報があればコメントを残して下さればとっても嬉しいです。
PS.この記事に関してはどんどん更新する予定です。