自己紹介
はじめまして。プログラミング初心者の大学生がKaggleのHousePriceをしてみたいと思います。
必要なライブラリをインポート
まずは分析に必要なライブラリをインストール。
import numpy as np
import pandas as pd
from pandas import Series, DataFrame
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
データ確認
trainデータとtestデータのサイズを確認
print(train.shape)
print(test.shape)
# 出力結果
(1460, 81)
(1459, 80)
特徴量を確認
train.columns
# 出力結果
Index(['Id', 'MSSubClass', 'MSZoning', 'LotFrontage', 'LotArea', 'Street',
'Alley', 'LotShape', 'LandContour', 'Utilities', 'LotConfig',
'LandSlope', 'Neighborhood', 'Condition1', 'Condition2', 'BldgType',
'HouseStyle', 'OverallQual', 'OverallCond', 'YearBuilt', 'YearRemodAdd',
'RoofStyle', 'RoofMatl', 'Exterior1st', 'Exterior2nd', 'MasVnrType',
'MasVnrArea', 'ExterQual', 'ExterCond', 'Foundation', 'BsmtQual',
'BsmtCond', 'BsmtExposure', 'BsmtFinType1', 'BsmtFinSF1',
'BsmtFinType2', 'BsmtFinSF2', 'BsmtUnfSF', 'TotalBsmtSF', 'Heating',
'HeatingQC', 'CentralAir', 'Electrical', '1stFlrSF', '2ndFlrSF',
'LowQualFinSF', 'GrLivArea', 'BsmtFullBath', 'BsmtHalfBath', 'FullBath',
'HalfBath', 'BedroomAbvGr', 'KitchenAbvGr', 'KitchenQual',
'TotRmsAbvGrd', 'Functional', 'Fireplaces', 'FireplaceQu', 'GarageType',
'GarageYrBlt', 'GarageFinish', 'GarageCars', 'GarageArea', 'GarageQual',
'GarageCond', 'PavedDrive', 'WoodDeckSF', 'OpenPorchSF',
'EnclosedPorch', '3SsnPorch', 'ScreenPorch', 'PoolArea', 'PoolQC',
'Fence', 'MiscFeature', 'MiscVal', 'MoSold', 'YrSold', 'SaleType',
'SaleCondition', 'SalePrice'],
dtype='object')
必要のない特徴量Idをひとまず削除
train=train.drop(['Id'],axis=1)
test=test.drop(['Id'],axis=1)
目的変数の確認
sns.distplot(train.SalePrice, bins = 25)
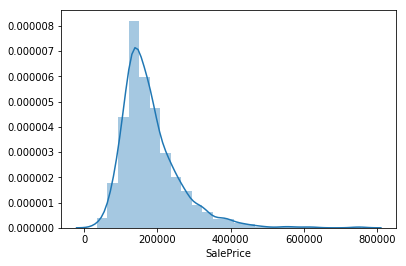
低所得者が多く、グラフ全体が左に寄っており、経済的不平等が起こっている。
欠損値処理
まずは欠損値の数を確認
# trainデータ
train.isnull().sum()[train.isnull().sum()>0]
# 出力結果
LotFrontage 259
Alley 1369
MasVnrType 8
MasVnrArea 8
BsmtQual 37
BsmtCond 37
BsmtExposure 38
BsmtFinType1 37
BsmtFinType2 38
Electrical 1
FireplaceQu 690
GarageType 81
GarageYrBlt 81
GarageFinish 81
GarageQual 81
GarageCond 81
PoolQC 1453
Fence 1179
MiscFeature 1406
dtype: int64
# testデータ
train.isnull().sum()[train.isnull().sum()>0]
# 出力結果
MSZoning 4
LotFrontage 227
Alley 1352
Utilities 2
Exterior1st 1
Exterior2nd 1
MasVnrType 16
MasVnrArea 15
BsmtQual 44
BsmtCond 45
BsmtExposure 44
BsmtFinType1 42
BsmtFinSF1 1
BsmtFinType2 42
BsmtFinSF2 1
BsmtUnfSF 1
TotalBsmtSF 1
BsmtFullBath 2
BsmtHalfBath 2
KitchenQual 1
Functional 2
FireplaceQu 730
GarageType 76
GarageYrBlt 78
GarageFinish 78
GarageCars 1
GarageArea 1
GarageQual 78
GarageCond 78
PoolQC 1456
Fence 1169
MiscFeature 1408
SaleType 1
dtype: int64
データの数に対して欠損値の数が極端に多い変数がいくつかあるので、内容を確認してみる。
train['FireplaceQu'].value_counts()
# 出力結果
Gd 380
TA 313
Fa 33
Ex 24
Po 20
Name: FireplaceQu, dtype: int64
Kaggleのページでダウンロードできるdata_descriptionには
FireplaceQu: Fireplace quality
Ex : Excellent - Exceptional Masonry Fireplace
Gd : Good - Masonry Fireplace in main level
TA : Average - Prefabricated Fireplace in main living area or Masonry Fireplace in basement
Fa : Fair - Prefabricated Fireplace in basement
Po : Poor - Ben Franklin Stove
NA : No Fireplace
とあるので、Na:No Fireplaceも欠損値扱いされてしまっている。
そのような特徴量の欠損値を'None'で補完
fillnaNone_list = ['Alley','BsmtCond','BsmtQual','BsmtExposure','BsmtFinType1', 'BsmtFinType2','FireplaceQu','GarageType', 'GarageFinish','GarageQual', 'GarageCond','PoolQC','Fence','MiscFeature']
for i in fillnaNone_list:
train[i].fillna('None',inplace=True)
test[i].fillna('None',inplace=True)
同様に、値が数値の特徴量の欠損値を0で補完(ただし、'GarageYrBlt'だけは0としてしまっては後々築年数に変換した時に面倒なので0で補完しない)
zero_list=['LotFrontage','MasVnrArea','BsmtFinSF1','BsmtFinSF2','BsmtUnfSF','TotalBsmtSF','BsmtFullBath','BsmtHalfBath','GarageCars','GarageArea']
for i in zero_list:
train[i].fillna(0,inplace=True)
test[i].fillna(0,inplace=True)
YearBuiltでGarageYrBltを補完するのが一番思いつきやすいため、補完して良いか確認するため関係を可視化
plt.plot(test.YearBuilt, test.GarageYrBlt,'.', alpha=0.5)

補完して良さそうなのでYearBuiltで補完
train['GarageYrBlt'].fillna(train.YearBuilt,inplace=True)
test['GarageYrBlt'].fillna(test.YearBuilt,inplace=True)
ここで一旦残っている欠損値を確認
# trainデータ
train.isnull().sum()[train.isnull().sum()>0]
# 出力結果
MasVnrType 8
Electrical 1
dtype: int64
# testデータ
test.isnull().sum()[test.isnull().sum()>0]
# 出力結果
MSZoning 4
Utilities 2
Exterior1st 1
Exterior2nd 1
MasVnrType 16
KitchenQual 1
Functional 2
SaleType 1
dtype: int64
平均値で処理すると外れ値に影響を受けやすく、カテゴリー変数に対応できないので最頻値で補完
n_list=['Electrical', 'MasVnrType', 'MSZoning', 'Functional', 'Utilities','Exterior1st', 'Exterior2nd', 'KitchenQual', 'SaleType']
for i in n_list:
train[i].fillna(train[i].mode()[0],inplace=True)
test[i].fillna(test[i].mode()[0],inplace=True)
これで欠損値が無くなった。
特徴量
普段家を購入するとき、築年数を気にするので、西暦で書かれている特徴量を経過した年数に変換する。
# 築年数、改修からの年数、売り出されてからの年数に変更する。
train['elapsed']=2018-train['YearBuilt']
train['remod_elapsed']=2018-train['YearRemodAdd']
train['sold_elapsed']=2018-train['YrSold']
train['garage_elapsed']=2018-train['GarageYrBlt']
test['elapsed']=2018-test['YearBuilt']
test['remod_elapsed']=2018-test['YearRemodAdd']
test['sold_elapsed']=2018-test['YrSold']
test['garage_elapsed']=2018-test['GarageYrBlt']
# 必要なくなった列をカラムを指定して削除
drop_columns=['YearBuilt','YearRemodAdd','YrSold','GarageYrBlt']
train=train.drop(drop_columns,axis=1)
test=test.drop(drop_columns,axis=1)
家を購入するとき最も気にするのは何と言っても広さなので、広さを表す特徴量を作る
# 部屋サイズ
train['TotalSF']= train['TotalBsmtSF']+ train['1stFlrSF']+train['2ndFlrSF']
test['TotalSF']= test['TotalBsmtSF']+ test['1stFlrSF']+ test['2ndFlrSF']
# ベランダサイズ
train['Porch']= train['EnclosedPorch']+ train['3SsnPorch']+ train['ScreenPorch']
+ train['WoodDeckSF']+ train['OpenPorchSF']
test['Porch']= test['EnclosedPorch']+ test['3SsnPorch']+ test['ScreenPorch']
+ test['WoodDeckSF']+ test['OpenPorchSF']
drop_columnsSF=['TotalBsmtSF','1stFlrSF','2ndFlrSF','EnclosedPorch','3SsnPorch','ScreenPorch','WoodDeckSF','OpenPorchSF']
train = train(drop_columnsSF,axis=1)
test= test(drop_columnsSF,axis=1)
特徴量が正規分布に従っていた方が精度が良くなるので歪度の高いものは偏りをなくす
# 数値の偏りをなくす為に、数値データを取り出す
numerical_features = train.select_dtypes(exclude = ["object"]).columns
train_num = train[numerical_features]
# 歪度を計算
from scipy.stats import skew
skewness = train_num.apply(lambda x: skew(x))
skew_features = skewness[abs(skewness)>0.5]
# 基本的に左に寄っていることを確認
for i in skew_features.index:
sns.distplot(train[i],bins = 25)
plt.xlabel(i)
plt.show()
e.g.)elapsed
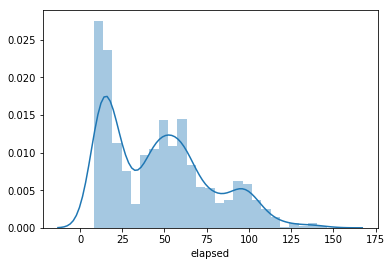
可視化して確かめると、全ての特徴量が上のelapsedのように左に寄っていることがわかった。従って、対数変換をしたいが、値が0未満だとlogを取れないので0未満の値がないかを確認。
print('train')
for i in skew_features.index:
print(train[train[i]<0].index)
print('test')
for i in skew_features.index.drop('SalePrice'):
print(test[test[i]<0].index)
# 出力結果
train
Int64Index([], dtype='int64')
Int64Index([], dtype='int64')
Int64Index([], dtype='int64')
Int64Index([], dtype='int64')
Int64Index([], dtype='int64')
Int64Index([], dtype='int64')
Int64Index([], dtype='int64')
Int64Index([], dtype='int64')
Int64Index([], dtype='int64')
Int64Index([], dtype='int64')
Int64Index([], dtype='int64')
Int64Index([], dtype='int64')
Int64Index([], dtype='int64')
Int64Index([], dtype='int64')
Int64Index([], dtype='int64')
Int64Index([], dtype='int64')
Int64Index([], dtype='int64')
Int64Index([], dtype='int64')
Int64Index([], dtype='int64')
Int64Index([], dtype='int64')
Int64Index([], dtype='int64')
Int64Index([], dtype='int64')
Int64Index([], dtype='int64')
test
Int64Index([], dtype='int64')
Int64Index([], dtype='int64')
Int64Index([], dtype='int64')
Int64Index([], dtype='int64')
Int64Index([], dtype='int64')
Int64Index([], dtype='int64')
Int64Index([], dtype='int64')
Int64Index([], dtype='int64')
Int64Index([], dtype='int64')
Int64Index([], dtype='int64')
Int64Index([], dtype='int64')
Int64Index([], dtype='int64')
Int64Index([], dtype='int64')
Int64Index([], dtype='int64')
Int64Index([], dtype='int64')
Int64Index([], dtype='int64')
Int64Index([], dtype='int64')
Int64Index([], dtype='int64')
Int64Index([], dtype='int64')
Int64Index([1132], dtype='int64')
Int64Index([], dtype='int64')
Int64Index([], dtype='int64')
garage_elapsedのIndex:1132が0未満だということが判明
test.loc[1132,'garage_elapsed']
# 出力結果
-189.0
経過年数が負の値は明らかにおかしいので、築年数で補完する
test.loc[1132,'garage_elapsed']=test.loc[1132,'elapsed']
これで0未満の値は消えたので、対数log(y+1)をとる。
for x in skew_features.index:
train[x]=np.log1p(train[x])
for y in skew_features.index.drop('SalePrice'):
test[y]=np.log1p(test[y])
次に、カテゴリー変数を数量データに変換する。
One-Hot-encodingでダミー変数化すると、特徴量が多くなりすぎてしまう。そこで、どんな特徴量にも少なからず順序関係があるのでは、と考えた。
例えばNeighborhood
この地域にことを全く知らない私たちには順序が分からないが、グラフで表示してみると
Neighborhood_meanSP = train.groupby('Neighborhood')['SalePrice'].mean()
Neighborhood_meanSP = Neighborhood_meanSP.sort_values()
sns.pointplot(x = train.Neighborhood.values, y = train.SalePrice.values, order =Neighborhood_meanSP.index)
plt.xticks(rotation=45)
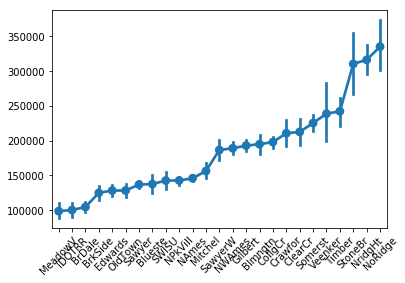
と、上図のように明らかに順序関係があることがわかる。従って、 各変数の順序関係に従って、エンコーディングすれば良いと考えた
for i in train.loc[:, train.dtypes == 'object'].columns:
num=-1
mapping={}
for j in train.groupby(i)['SalePrice'].mean().sort_values().index:
num+=1
mapping[j]=num
train[i]= train[i].map(mapping)
test[i]=test[i].map(mapping)
object型の変数が消えたことを確認
# trainデータ
train.dtypes.value_counts()
# 出力結果
int64 50
float64 24
dtype: int64
## testデータ
test.dtypes.value_counts()
# 出力結果
int64 48
float64 25
dtype: int64
これで全て数字になった
外れ値を消す
外れ値を消すために、全て可視化して、目視で外れ値を消していく
for i in train.columns:
plt.scatter(train[i],train['SalePrice'])
plt.xlabel(i)
plt.show()
外れ値を消す
train = train.drop(train[(data_train['TotalSF']>8.7) & (train['SalePrice']<12.3)].index)
train = train.drop(data_train[(train['GrLivArea']>8.3) & (train['SalePrice']<13)].index)
train = train.drop(train[(train train['GarageArea']>1200) & (train['SalePrice']<12.5)].index)
特徴量を工夫
ひとまず説明変数と目的変数に分ける
Y_train=train['SalePrice']
X_train=train.drop('SalePrice',axis=1)
X_test=test
特徴量を減らすため、特徴量の重要度を求める
from sklearn.metrics import accuracy_score
from sklearn.ensemble import RandomForestRegressor
rf = RandomForestRegressor(n_estimators=80)
rf = rf.fit(X_train, Y_train)
ranking = np.argsort(-rf.feature_importances_)
f, ax = plt.subplots(figsize=(11, 9))
sns.barplot(x=rf.feature_importances_[ranking], y=X_train.columns.values[ranking], orient='h')
ax.set_xlabel("feature importance")
plt.tight_layout()
plt.show()

このうち上位30この特徴量を使用
X_train = X_train.iloc[:,ranking[:30]]
X_test = X_test.iloc[:,ranking[:30]]
また、OverallQualとTotalSFが飛び抜けているので、2つの変数を掛け合わせた新しい特徴量を作る。
X_train['QualSF']=X_train['OverallQual']*X_train['TotalSF']
X_test['QualSF']=X_test['OverallQual']*X_test['TotalSF']
正規化
mean = X_train.mean(axis=0)
std = X_train.std(axis=0)
X_train = (X_train - mean) / std
X_test = (X_test - mean) / std
多重共線性をなくすために、相関の強い特徴量を削除する
correlation = X_train.corr()
f , ax = plt.subplots(figsize = (20,20))
sns.heatmap(correlation,square = True, vmax=0.8,annot=True)
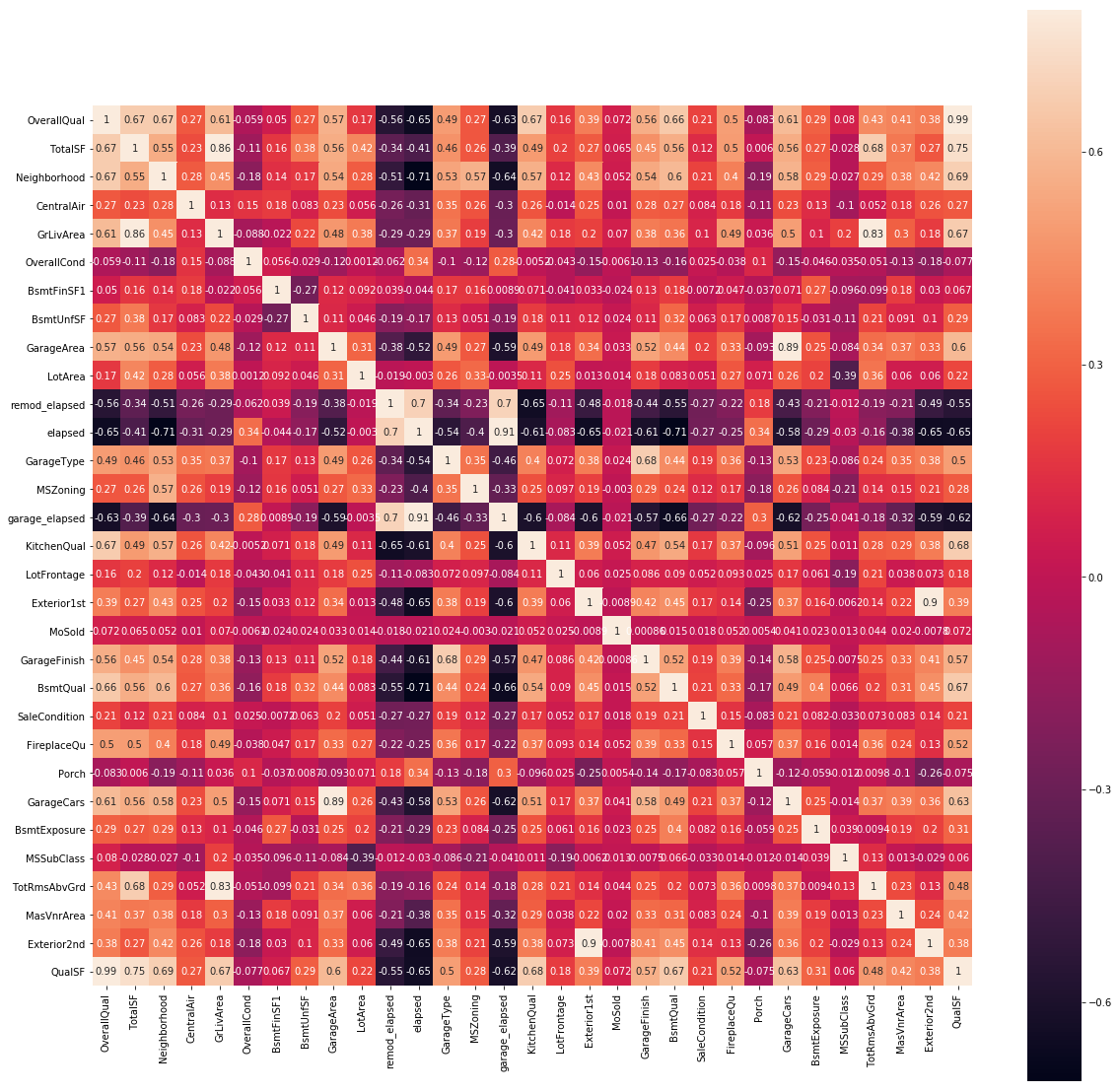
X_train=X_train.drop(['GrLivArea','garage_elapsed','GarageCars','remod_elapsed'],axis=1)
X_test=X_test.drop(['GrLivArea','garage_elapsed','GarageCars','remod_elapsed'],axis=1)
モデリング
データ数が少ないので、交差検証法、グリッドサーチを用い、複数のモデルで検証し、最も結果の良かったものを採用する。
# KFold
from sklearn.model_selection import KFold
kf_3 = KFold(n_splits=6, shuffle=True, random_state=0)
# モデルの呼び出し
from sklearn.linear_model import Lasso
from sklearn.ensemble import RandomForestRegressor
from sklearn.svm import SVR
from sklearn.model_selection import GridSearchCV
from sklearn.linear_model import ElasticNet
from sklearn.linear_model import Ridge
from xgboost import XGBRegressor
# 各モデルのインスタンスを生成
ridge=Ridge()
elastic= ElasticNet()
lasso = Lasso()
rf = RandomForestRegressor()
svr = SVR()
XGB= XGBRegressor()
# グリッドサーチ用パラメータの設定
elasticnet_parameters= {'alpha':[0.1, 0.5, 1],'l1_ratio':[0.3,0.6,0.9]}
lasso_parameters = {'alpha':[0.1, 0.5, 1]}
rf_parameters= {'n_estimators':[100, 500, 2000], 'max_depth':[3, 5, 10]}
svr_parameters = {'C':[1e-1, 1e+1, 1e+3], 'epsilon':[0.05, 0.1, 0.3]}
ridge_parameters = {'alpha':[0.1, 0.5, 1]}
xgb_parameters = {"learning_rate":[0.1,0.3,0.5],"max_depth": [2,3,5,10],"subsample":[0.5,0.8,0.9,1],"colsample_bytree": [0.5,1.0],}
# グリッドサーチ
elastic_gs=GridSearchCV(elastic, elasticnet_parameters,cv=kf_3)
elastic_gs.fit(x_train,y_train)
lasso_gs = GridSearchCV(lasso, lasso_parameters,cv=kf_3)
lasso_gs.fit(x_train,y_train)
rf_gs = GridSearchCV(rf, rf_parameters,cv=kf_3)
rf_gs.fit(x_train,y_train)
svr_gs = GridSearchCV(svr, svr_parameters,cv=kf_3)
svr_gs.fit(x_train,y_train)
ridge_gs=GridSearchCV(ridge, ridge_parameters,cv=kf_3)
ridge_gs.fit(x_train,y_train)
xgb_gs = GridSearchCV(XGB, xgb_parameters, cv = kf_3)
xgb_gs.fit(x_train,y_train)
# 平均二乗誤差を計算
from sklearn.metrics import mean_squared_error
def RMSE(instance, modelname):
Y_pred = instance.predict(x_test)
print("{}でのRMSE:{:.4f}".format(modelname ,np.sqrt(mean_squared_error(y_test, Y_pred))))
RMSE(elastic_gs,'ElasticNet')
RMSE(lasso_gs,'ラッソ回帰')
RMSE(rf_gs,'ランダムフォレスト')
RMSE(svr_gs,'SVR')
RMSE(ridge_gs,'Ridge')
RMSE(xgb_gs,'XGBoost')
# 出力結果
ElasticNetでのRMSE:0.1630
ラッソ回帰でのRMSE:0.1689
ランダムフォレストでのRMSE:0.1349
SVRでのRMSE:0.4008
RidgeでのRMSE:0.1178
XGBoostでのRMSE:0.1272
この結果より、ridgeを採用しました。

順位もぼちぼちでは無いでしょうか(12/30/2018)
Keras
せっかくKerasも習ったのでKerasで多層ニューラルネットモデル(MLP)を作成して回帰分析をしてみました。
numpy.ndarrayに変換
全結合層に入力するためにpandas.DataFrameをnumpy.ndarrayに変換します。
x_train=np.array(x_train)
y_train=np.array(y_train)
x_test=np.array(x_test)
y_test=np.array(y_test)
X_test=np.array(X_test)
ネットワークの定義
from keras.models import Sequential
model = Sequential()
model.add(Dense(10, input_shape=(x_train.shape[1],), activation='relu'))
model.add(Dense(15))
model.add(Activation('relu'))
model.add(Dense(1))
from keras import optimizers
optimizer = optimizers.Adam(lr=0.001, beta_1=0.9, beta_2=0.999, epsilon=1e-08)
model.compile(loss='mse',
optimizer=optimizer,
metrics=['mae'])
model.summary()
今回は以下の様なネットワークの定義を定義してみました。

EarlyStoppingのインスタンスを生成
過学習を抑えるため、Kerasのearly stoppingを利用しました。
from keras.callbacks import EarlyStopping
early_stop = keras.callbacks.EarlyStopping(monitor='val_loss', patience=20,verbose=0, mode='min')
学習の実行
history = model.fit(x_train, y_train, epochs=500,
validation_data=(x_test,y_test), verbose=1,
callbacks=[early_stop])
損失値(Loss)の遷移のプロット
プロットして損失値の推移を視覚化します。
def plot_history_loss(history):
plt.plot(history.history['mean_absolute_error'],label="loss for training")
plt.plot(history.history['val_mean_absolute_error'],label="loss for validation")
plt.title('model loss')
plt.xlabel('epoch')
plt.ylabel('loss')
plt.legend(loc='best')
plt.show()
plt.ylim([0,2])
plot_history_loss(history)
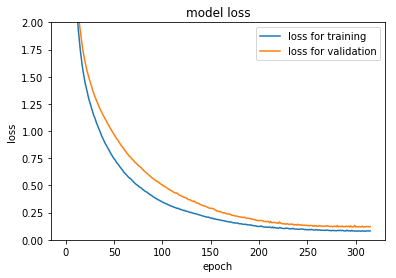
testデータで予測
先ほど定義した関数で、平均二乗誤差(RMSE)を出力します。
Y_pred = model.predict(x_test)
print("{}でのRMSE:{:.4f}".format('MLP' ,np.sqrt(mean_squared_error(y_test, Y_pred))))
# 出力結果
MLPでのRMSE:0.1780
あまり結果は良くありませんでした。今度はもう少し層を深くしてみます
ネットワークの定義②
活性化関数やOptimizers等は変えずに、層を深くし、過学習を抑えるためにDropoutレイヤーを追加しました。
model = Sequential()
model.add(Dense(10, input_shape=(x_train.shape[1],), activation='relu'))
model.add(Dense(15))
model.add(Activation('relu'))
model.add(Dropout(0.50))
model.add(Dense(100))
model.add(Activation('relu'))
model.add(Dropout(0.50))
model.add(Dense(100))
model.add(Activation('relu'))
model.add(Dropout(0.50))
model.add(Dense(100))
model.add(Activation('relu'))
model.add(Dropout(0.50))
model.add(Dense(64))
model.add(Activation('relu'))
model.add(Dense(1))
 あとは先ほどと同じ様に損失値(Loss)の遷移をプロット
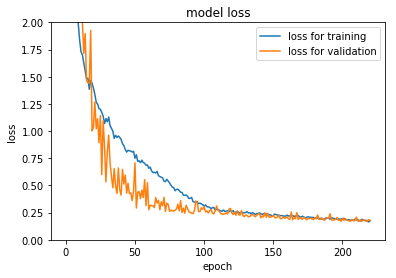
平均二乗誤差を出力すると、
あとは先ほどと同じ様に損失値(Loss)の遷移をプロット

平均二乗誤差を出力すると、
MLPでのRMSE:0.2434
...むしろ悪くなってしまいました。過学習をしてしまったのかもしれません。