Automation Anywhere A2019のOCRアクションを試してみました。
環境
- Automation Anywhere Community Edition A2019.14 (ビルド5322)
OCRアクションの利用
A2019では、以下の4つのアクションを利用できます。これらは無料のCommunity Editionでも利用できます!
この中で「パスで画像をキャプチャ」アクションを利用しました。利用した画像は、国税庁のページにあった以下のバナーです。左側に人の画像が、右側にいくつかのサイズで文字が書かれています。画像サイズは1141x477でした。

Botのアクションリストは以下の通り、OCRアクションで認識した文字列をメッセージボックスで表示するシンプルなものです。今回は、あらかじめ画像ファイルをControl Roomにアップしましたが、デスクトップに置いていてもよいですし、変数指定でループ等を回すことも可能です。

「ロケールを選択」では、英語、日本語、ロシア語を選択できます。ここでは「日本語」を選びます。OCRエンジンは今のところABBYY一択のようです。
実行してみると、初回実行は結構時間がかかりました。650MBくらいのモジュールをロードしてきます。(2回目以降は時間はかかりません)

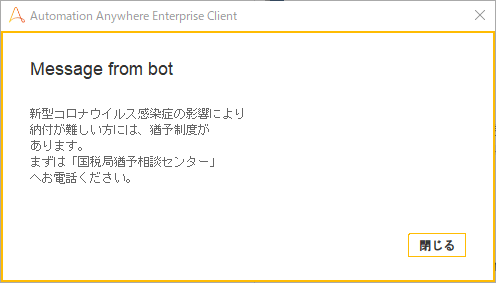
出力結果ですが、画像はうまくよけて文字列だけ正しく認識できていることがわかります。
v11との比較
v11.3.2以降は日本語でOCRが可能でした。OCRエンジンはいくつか選択可能 (ABBYY、MODI、TESSERACT、TOCR) でしたが既定の状態で使えるのはABBYYかTESSERACTの2択でした。(ABBYYには初期設定が必要⇒『Automation Anywhere で日本語OCRエンジンが動作しないときに確認する項目』)
v11はクライアントソフトだったので、オプションダイアログボックスで画像や結果のプレビューができたのは便利でした。
手元にあるv11.3.3で試したところ、ABBYYの場合、文字列は正しく認識できましたが、人の画像の一部を文字として認識してしまっているのか、2か所にゴミが入っています(赤枠)。そういう意味では、A2019の方がトリミングの精度は向上しているようです。
ABBYY

OSSのTESSERACTの場合は、人の画像の部分を読み込んでしまいゴミの部分が多くなっているのと、画数が多い漢字2字 (「響」⇒「璽」、「電」⇒「雷」)が間違っているのと、センターの長音記号が数字の「一」になってしまっており、コンテキストによる修正が効いていないようです。
TESSERACT

ちなみに、OCRに読み込ませる画像の解像度は200 DPI程度以上が必要です。パソコンの画面の解像度は通常96DPI程度なので、パソコンに表示される文字は2倍以上に拡大した状態でないとうまく認識されません。このバナーくらいの文字の大きさが必要ということになります。