はじめに
この記事は簡易な実装のDQNで実験を行った結果を記事にしたものです。ガチ研究的な内容ではありませんので、ご了承ください。
「昨今の深層強化学習は、簡易な実装でもここまで性能が出せるんだな~」くらいの軽い気持ちで読んでもらえると幸いです。
概要
ゲーム開発においてゲームバランスを調整する際、必ずテストプレイを行います。ゲームの攻略方法は大変複雑なため、テストプレイを自動化するのは難しく、多くの場合は人の手でテストを行います。ゲームによってはルールベースのAIを作成して自動化できる場合もありますが、そのようなAIは通常、一つのゲーム専用のAIとして作成され、他のゲームのテストプレイに流用することは難しいです1。もしもゲームの種類を問わずテストプレイを自動で行えるAIがあれば、ゲームバランス調整作業が格段に効率化されるはずです。
このようなAIを作成できる可能性のある機械学習手法の一つが**(深層)強化学習です。強化学習は行動を学習することに長けた手法です。ゲームに当てはめると、ゲームを攻略するための最適な行動を学習する**ことが可能です。あらゆるゲームを汎用的に学習することは難しいですが、強化学習が得意とするジャンルに絞ることで、現在の強化学習の学習能力でも十分なテストプレイを行える可能性があります。
そこで、強化学習を用いてターン制RPGの戦闘を自動で学習し、テストプレイを行うことができるか、実験・検証してみました。
ソースコード
GitHub
学習アプリの使用例(Google Colaboratoryで動作確認できます)
学習対象のゲーム
初代ドラゴンクエスト(以下DQ1)の1対1戦闘を模したゲームを学習対象とします。
DQ1の戦闘もそれなりに複雑なので、今回はDQ1の戦闘をさらにシンプルにしたものに対して学習を行います。
今回学習対象としたゲームのルールは以下の通りです。強化学習が学習を行うために必要な「報酬を得る条件」も併せて記載しています。
ゲームのルール
ランダムに現れるモンスターと10回戦闘を行い、より多くの戦闘に勝利しつつ、10回の戦闘を生き残ることを目指す(逃走も可能)。
報酬を得る条件
- 戦闘に勝利する:+1
- 10回の戦闘を生き残る:+10
- 戦闘に敗北する:-20
この条件は、RPGにおいて「町から出て、敵と戦いながら次の町にたどり着けること」を模しています。RPGでは、戦闘に勝利することで「所持金が増える」「経験値を得られる」等の小さなメリットがあります。また、新しい町にたどり着くことで、シナリオを進めたり強力な武器防具を購入できるなど、大きなメリットが得られます(今回は10回戦闘すると次の町にたどり着くと想定しました)。一方、戦闘に敗北した場合は「所持金が半分になる」「セーブ地点からやり直す」など、非常に大きなデメリットを被ることがほとんどです。こうしたRPGの特徴を得点として表したのが上記ルールです。
このルールのポイントは「一般的なRPGのルール」のみを表現しており、ゲーム固有のルールや攻略のコツなどは表現していないことです。
例えば今回のゲームは「呪文を使う敵は、呪文を封じてから戦う」という攻略方法があるため、「呪文を封じたら報酬+1」のような報酬条件を設定することも可能です。しかしそのような条件を設定してしまうと、呪文を封じる手段がないゲームや、そもそも呪文という概念がないゲームにAIを適用することができなくなります。さらに言えば、「呪文を封じる」のような攻略法を報酬に設定して学習させるのであれば、初めからルールベースで行動するAIを作ればよく、強化学習を使う意味がなくなります。
今回設定した「戦闘に勝利する」「戦闘を生き残る」といったルールはRPGにおける一般的なルールであるため、この報酬設定で学習に成功すれば、他の多くのRPGに対しても学習可能なAIになります。
なお、通常のRPGでは敵を倒すことで主人公がレベルアップして強くなったり、到達したい町によって敵の強さや敵に遭遇する回数も変わります。しかし今回は簡単のため、主人公の強さや出現する敵の種類は固定とします。
行動パターン
1対1の戦闘では行動手段がある程度充実していないとゲーム内容が単調になり、難易度も低くなります。そこで今回は以下のとおり5種類の行動を可能とし、AIが各行動を適切に選択するよう学習できるか実験します。
| 行動 | 消費MP | 説明 |
|---|---|---|
| 攻撃 | 0 | 通常攻撃 |
| 逃げる | 0 | 敵を倒さずに戦闘を終了できるが、失敗することもある。 相手より自分の素早さが高いほど成功率が上がる。 |
| 治療 | 4 | 自分のHPを回復する。 |
| 火の玉 | 3 | 敵に防御力無視のダメージを与える。 |
| 封印 | 2 | 敵の呪文(MPを消費する行動)を封じる。 戦闘が終了すると解除される(戦闘中は解除されない)。 |
※攻撃と呪文はすべて必中
上記行動が可能となることで、以下のような戦略が生まれます。
- 防御力の高い敵には「攻撃」より「火の玉」が有効になる
- 呪文を使う敵には「封印」が有効な反面、呪文を使わない敵に対して「封印」は無駄行動になる
- ピンチの時(HPやMPが少ない時)や強敵と出くわしたときには「逃げる」を選択することで敗北を回避できる
- MPが切れると呪文が使えなくなるため、効率よくMPを使うコマンド戦略が求められる
敵の種類
遭遇する敵は以下の5種類とします。
| 名前 | 特徴 | 行動 パターン |
攻略方法 |
|---|---|---|---|
| 魔法コウモリ | 呪文を使う HPが低い |
攻撃 火の玉 |
攻撃でOK 封印も有効だが 費用対効果が薄い |
| 食人植物 | 特になし | 攻撃 | 攻撃でOK |
| 魔法幽霊 | 呪文を使う | 攻撃 火の玉 |
攻撃でOKだが、封印も有効 |
| 鉄のザリガニ | 防御力が高い HPが低い |
攻撃 | 火の玉が有効 |
| コウモリーマ | 呪文を多用する | 攻撃 火の玉 治療 |
火の玉の呪文を特によく使う 初めに呪文を封印するのがベスト |
以上がゲームの大まかなルールです。詳細な仕様を確認したい方は以下をクリックしてください。
ゲームの詳細仕様を見る(クリックして展開)
主人公のステータス
| ステータス | 値 |
|---|---|
| 最大HP | 40 |
| 最大MP | 26 |
| 攻撃力 | 33 |
| 守備力 | 22 |
| 素早さ | 17 |
※プログラム上は武器・防具の概念を実装していますが、現時点ではあまり意味が無いので、武器・防具を合わせた数値のみ表記しています。
敵の種類とステータス(詳細)
| 名前 | 最大HP | 最大MP | 攻撃力 | 守備力 | 素早さ | 行動パターン |
|---|---|---|---|---|---|---|
| 魔法コウモリ | 15 | 8 | 13 | 13 | 8 | 攻撃:50% 火の玉:50% |
| 食人植物 | 22 | 0 | 20 | 15 | 11 | 攻撃 |
| 魔法幽霊 | 26 | 10 | 18 | 20 | 14 | 攻撃:50% 火の玉:50% |
| 鉄のザリガニ | 15 | 0 | 26 | 50 | 8 | 攻撃 |
| コウモリーマ | 20 | 14 | 20 | 26 | 18 | 攻撃:25% 火の玉:50% 治療:25% |
ダメージ/回復 計算
| コマンド | 計算式 |
|---|---|
| 攻撃 | (攻撃力 - (防御力/2)) / (2 + (0~2)) |
| 火の玉(プレイヤー) | 7~12 |
| 火の玉(敵) | 3~10 |
| 治療(プレイヤー) | 18~25 |
| 治療(敵) | 10~16 |
逃げるコマンドの成功確率
- プレイヤーの素早さ×4 / ((プレイヤーの素早さ*4) + 敵の素早さ)
先攻/後攻の条件
以下の確率でプレイヤーが先制攻撃する
- プレイヤーの素早さ×4 / ((プレイヤーの素早さ*4) + 敵の素早さ)
先攻・後攻の決定後は、プレイヤーと敵が交互に行動を行う(2回連続で行動することは無い)。
敵の初期HP
出現時のHPは、最大HPの75%~100%の間でランダムに決定する。
エージェント(AIプレイヤー)に与える情報
深層強化学習の研究では、エージェント(学習を行うAIプレイヤー)にゲーム画面を情報として与えて学習させることが多いです。しかしゲーム画面を元にして学習するのは非常に難易度が高いうえ、学習に時間もかかるため、「テストプレイを自動化する」という要件を満たせない可能性が高いです。今回は強化学習の性能を追求する目的ではないので、実用的な性能を出しやすいよう、学習に必要な各種戦闘パラメータをエージェントに直接与えて学習を行います。
具体的にエージェントに与えるパラメータは以下の通りです。
-
主人公のパラメータ
パラメータ 補足 最大HP 現在HP 現在MP 今回のゲームではMPの回復手段が無いので
最大MPの情報は不要攻撃力 力 + 武器 防御力 体力 + 防具 素早さ 封印状態 -
敵のパラメータ
パラメータ 補足 最大HP 攻撃力 防御力 素早さ 封印状態 敵に与えた総ダメージ量 与えたダメージ - 回復されたHP 各コマンドの使用可否 -
その他
パラメータ 補足 残り戦闘回数
エージェントに与えるパラメータ情報は、原則として人間のプレイヤーが得られる情報と同等です。ただし、学習に不要なパラメータ(最大MPや、力(武器を除いた攻撃力)など)は除外しています。
例外として敵の固定パラメータはエージェントに直接与えます。通常のRPGでは敵のパラメータを(特殊な魔法等を使用しない限りは)知ることはできず、名前やグラフィックからステータスを予想したり、何度も戦って敵の能力を判断して戦います。本来であればAIにも敵の名前や画像データを与えて学習させるべきですが、前述のとおり画像等のデータから学習を行うことは難しいですし、敵ステータスの学習は今回の研究の本質ではないので、直接パラメータを与えることとします。
学習成功の判断条件
今回は以下の3条件を満たした場合に、学習が成功したと判断します。
- 9割程度の確率で10回の戦闘を生き残る
- 逃げる回数が0~2回程度である
- コマンドを使い分けできる
上記3条件を選んだ理由は以下の通りです。
9割程度の確率で10回の戦闘を生き残る
ゲームの難易度を簡単にするとAIが学習しているかの判断が難しくなるため、今回のゲームは難易度を少し高めに設定しています。したがって9割程度の確率で10回の戦闘を生き残ることができれば、学習が成功していると判断します。
逃げる回数が0~2回程度である
このゲームでは「逃げる」の成功率が高いため、逃げるを多数選択すれば比較的簡単に10回の戦闘を生き残れます。しかし「なるべく多くの戦闘に勝利すること」がゲームの目的の一つなので、逃げる回数は最低限であることをもって、学習が成功していると判断します。
コマンドを使い分けできる
強化学習の面白いところは、「目的」を伝えるだけで「手段」を自動で獲得するところにあります。今回のゲームにおける「手段」は「コマンドの使い分け」に該当するので、この使い分けが上手くできていることも、学習成功の判断基準の一つとします。
なお、コマンドの適切な使い分けについては敵の種類を参照ください。
深層強化学習の手法とパラメータ
深層強化学習の手法にはDQNを利用します。
今回はガチ研究ではなく、手軽に試せる範囲で実験したいというモチベーションなので、Google Colaboratoryで数十分程度で学習が完了する程度のモデルサイズ、かつ手軽に試せるDQNを採用しました。深層学習のモデルが小さいので、普通のPC(CPU:core i5, メモリ:8GB 程度)でも学習可能です。
各種パラメータは以下の通りです。
深層学習部
| パラメータ | 値 |
|---|---|
| 層数 | 3(すべて全結合層) |
| 隠れ層のユニット数 | 100 |
| 活性化関数 | LeRU |
強化学習部
| パラメータ | 値 |
|---|---|
| 経験再生メモリ数 | 10000 |
| 経験再生バッチサイズ | 128 |
| γ | 0.99 |
| ε | 0.9→0.05まで、4000ステップで線形減少 |
| DQNのアップデート頻度 | 10エピソード |
| 学習エピソード回数 | 6000 |
結果
学習状況の推移
まずは学習状況の推移を確認します。
以下のグラフの青線は各エピソードの獲得報酬、オレンジの線は直近100エピソードの獲得報酬の平均値です。
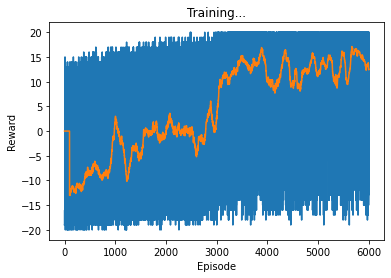
学習初期は平均獲得報酬が低く、運よく生き残っても獲得報酬が(最大値である)20に達することはありません。
しかし3000エピソード頃から急激に獲得報酬量が増加し、4000~6000エピソードくらいになると、多少ブレがあるものの10~15程度の報酬を獲得できるようになっています。
学習結果の確認
次に学習完了後のエージェントにて100エピソード分ゲームを行い、結果を確認します。
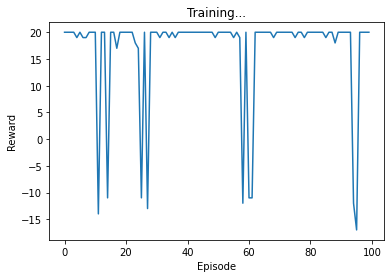
上記結果を学習成功の判断条件に当てはめて確認してみましょう。
9割程度の確率で10回の戦闘を生き残る
戦闘に敗北すると獲得報酬が0未満になるので、この結果では9回戦闘不能になっています。
100エピソード中91回は生き残っているので、約9割の確率で生き残っており、学習は成功したと判断できそうです。
逃げる回数が0~2回程度である
戦闘にすべて勝利した場合の獲得報酬は20、2回逃げて8回勝利した場合の獲得報酬は18となります。
上記グラフのうち、生き残った戦闘のほとんどは18以上の報酬を獲得しており、この点においても学習は成功していそうです。
コマンドを使い分けできる
この条件を達成しているか判断するには、実際にエージェントが選択した行動を確認する必要があります。
以下に1エピソード攻略した際の結果を記載します。長いので、見たい人だけクリックして表示してください。
1エピソードの攻略例(クリックして展開)
あなた は 封印 の呪文を唱えた! コウモリーマ は呪文が使えなくなった!
コウモリーマ は 治療 の呪文を唱えた! しかし呪文は封じられている!
あなたのステータス
HP:40, MP:24
モンスター:コウモリーマ
あなた の攻撃! コウモリーマ に 5 のダメージを与えた!
コウモリーマ は 火の玉 の呪文を唱えた! しかし呪文は封じられている!
あなたのステータス
HP:40, MP:24
モンスター:コウモリーマ
あなた の攻撃! コウモリーマ に 7 のダメージを与えた!
コウモリーマ の攻撃! あなた は 3 のダメージを受けた!
あなたのステータス
HP:37, MP:24
モンスター:コウモリーマ
あなた の攻撃! コウモリーマ に 7 のダメージを与えた!
コウモリーマ は 倒れた!
コウモリーマ を倒した!
残り戦闘回数: 9 回
新たに 魔法コウモリ が出現しました。コマンドを選択してください。
あなたのステータス
HP:37, MP:24
モンスター:魔法コウモリ
あなた の攻撃! 魔法コウモリ に 8 のダメージを与えた!
魔法コウモリ の攻撃! あなた は 0 のダメージを受けた!
あなたのステータス
HP:37, MP:24
モンスター:魔法コウモリ
あなた の攻撃! 魔法コウモリ に 7 のダメージを与えた!
魔法コウモリ は 倒れた!
魔法コウモリ を倒した!
残り戦闘回数: 8 回
新たに 食人植物 が出現しました。コマンドを選択してください。
あなたのステータス
HP:37, MP:24
モンスター:食人植物
あなた の攻撃! 食人植物 に 7 のダメージを与えた!
食人植物 の攻撃! あなた は 3 のダメージを受けた!
あなたのステータス
HP:34, MP:24
モンスター:食人植物
あなた の攻撃! 食人植物 に 9 のダメージを与えた!
食人植物 の攻撃! あなた は 2 のダメージを受けた!
あなたのステータス
HP:32, MP:24
モンスター:食人植物
あなた の攻撃! 食人植物 に 12 のダメージを与えた!
食人植物 は 倒れた!
食人植物 を倒した!
残り戦闘回数: 7 回
新たに 魔法コウモリ が出現しました。コマンドを選択してください。
あなたのステータス
HP:32, MP:24
モンスター:魔法コウモリ
あなた の攻撃! 魔法コウモリ に 7 のダメージを与えた!
魔法コウモリ は 火の玉 の呪文を唱えた! あなた は 3 のダメージを受けた!
あなたのステータス
HP:29, MP:24
モンスター:魔法コウモリ
あなた の攻撃! 魔法コウモリ に 11 のダメージを与えた!
魔法コウモリ は 倒れた!
魔法コウモリ を倒した!
残り戦闘回数: 6 回
新たに コウモリーマ が出現しました。コマンドを選択してください。
あなたのステータス
HP:29, MP:24
モンスター:コウモリーマ
あなた は 封印 の呪文を唱えた! コウモリーマ は呪文が使えなくなった!
コウモリーマ の攻撃! あなた は 3 のダメージを受けた!
あなたのステータス
HP:26, MP:22
モンスター:コウモリーマ
あなた の攻撃! コウモリーマ に 5 のダメージを与えた!
コウモリーマ の攻撃! あなた は 3 のダメージを受けた!
あなたのステータス
HP:23, MP:22
モンスター:コウモリーマ
あなた の攻撃! コウモリーマ に 8 のダメージを与えた!
コウモリーマ の攻撃! あなた は 2 のダメージを受けた!
あなたのステータス
HP:21, MP:22
モンスター:コウモリーマ
あなた の攻撃! コウモリーマ に 6 のダメージを与えた!
コウモリーマ は 倒れた!
コウモリーマ を倒した!
残り戦闘回数: 5 回
新たに 魔法幽霊 が出現しました。コマンドを選択してください。
あなたのステータス
HP:21, MP:22
モンスター:魔法幽霊
あなた の攻撃! 魔法幽霊 に 8 のダメージを与えた!
魔法幽霊 の攻撃! あなた は 2 のダメージを受けた!
あなたのステータス
HP:19, MP:22
モンスター:魔法幽霊
あなた の攻撃! 魔法幽霊 に 6 のダメージを与えた!
魔法幽霊 の攻撃! あなた は 2 のダメージを受けた!
あなたのステータス
HP:17, MP:22
モンスター:魔法幽霊
あなた の攻撃! 魔法幽霊 に 10 のダメージを与えた!
魔法幽霊 は 倒れた!
魔法幽霊 を倒した!
残り戦闘回数: 4 回
新たに コウモリーマ が出現しました。コマンドを選択してください。
あなたのステータス
HP:17, MP:22
モンスター:コウモリーマ
コウモリーマ は 治療 の呪文を唱えた! コウモリーマ の HP が 2 回復した!
あなた は 封印 の呪文を唱えた! コウモリーマ は呪文が使えなくなった!
あなたのステータス
HP:17, MP:20
モンスター:コウモリーマ
コウモリーマ は 火の玉 の呪文を唱えた! しかし呪文は封じられている!
あなた の攻撃! コウモリーマ に 5 のダメージを与えた!
あなたのステータス
HP:17, MP:20
モンスター:コウモリーマ
コウモリーマ は 火の玉 の呪文を唱えた! しかし呪文は封じられている!
あなた の攻撃! コウモリーマ に 5 のダメージを与えた!
あなたのステータス
HP:17, MP:20
モンスター:コウモリーマ
コウモリーマ の攻撃! あなた は 3 のダメージを受けた!
あなた の攻撃! コウモリーマ に 7 のダメージを与えた!
あなたのステータス
HP:14, MP:20
モンスター:コウモリーマ
コウモリーマ の攻撃! あなた は 2 のダメージを受けた!
あなた の攻撃! コウモリーマ に 6 のダメージを与えた!
コウモリーマ は 倒れた!
コウモリーマ を倒した!
残り戦闘回数: 3 回
新たに 魔法コウモリ が出現しました。コマンドを選択してください。
あなたのステータス
HP:12, MP:20
モンスター:魔法コウモリ
あなた の攻撃! 魔法コウモリ に 10 のダメージを与えた!
魔法コウモリ の攻撃! あなた は 1 のダメージを受けた!
あなたのステータス
HP:11, MP:20
モンスター:魔法コウモリ
あなた の攻撃! 魔法コウモリ に 6 のダメージを与えた!
魔法コウモリ は 倒れた!
魔法コウモリ を倒した!
残り戦闘回数: 2 回
新たに 鉄のザリガニ が出現しました。コマンドを選択してください。
あなたのステータス
HP:11, MP:20
モンスター:鉄のザリガニ
あなた は 火の玉 の呪文を唱えた! 鉄のザリガニ に 8 のダメージを与えた!
鉄のザリガニ の攻撃! あなた は 4 のダメージを受けた!
あなたのステータス
HP:7, MP:17
モンスター:鉄のザリガニ
あなた は 治療 の呪文を唱えた! あなた の HP が 21 回復した!
鉄のザリガニ の攻撃! あなた は 4 のダメージを受けた!
あなたのステータス
HP:24, MP:13
モンスター:鉄のザリガニ
あなた は 火の玉 の呪文を唱えた! 鉄のザリガニ に 7 のダメージを与えた!
鉄のザリガニ は 倒れた!
鉄のザリガニ を倒した!
残り戦闘回数: 1 回
新たに 魔法コウモリ が出現しました。コマンドを選択してください。
あなたのステータス
HP:24, MP:10
モンスター:魔法コウモリ
あなた の攻撃! 魔法コウモリ に 7 のダメージを与えた!
魔法コウモリ は 火の玉 の呪文を唱えた! あなた は 8 のダメージを受けた!
あなたのステータス
HP:16, MP:10
モンスター:魔法コウモリ
あなた の攻撃! 魔法コウモリ に 10 のダメージを与えた!
魔法コウモリ は 倒れた!
魔法コウモリ を倒した!
敵を 10 体倒しました! シミュレーションを終了します。
獲得報酬は20です。
([20], 0)
上記から、AIの学習結果を以下の通り読み取ることができます。
- 鉄のザリガニには「火の玉」の呪文、その他の敵には通常攻撃を選択しており、攻撃方法を使い分けている。
- HPが低くなると「治療」の呪文を使って自身のHPを回復している。
- 相手に応じて「封印」の呪文を使い分けている。呪文が特に強力なコウモリーマには封印の呪文を利用する一方、魔法コウモリや魔法幽霊には封印の呪文を使っていない。
いずれの行動も適切に使い分けており、この点においても上手く学習できていると判断できます。
学習は大成功・・・・・・?
ここまでの結果から、学習は大成功! ・・・と言いたいところですが、実は一つ大きな問題があります。それは、毎回このような学習結果になるわけではなく、学習をやり直すたびに結果が大きくブレることです。
今回のように6000エピソード程度で良く学習することもあれば、学習が足りないこともあります。記事中の結果は比較的良い結果をピックアップしており、悪い結果だと7割くらいしか生き残れない場合もあります。学習が足りないからと言ってエピソード数を増やしすぎると、今度は過学習しているのか、学習結果が悪化してしまいます。結構いい感じに学習してくれる場合があることは間違いないのですが、実運用への適用を考えると、学習結果をもっと安定させないと使い物にならないです。
ただし今回はかなり簡易な実装になっているので、深層学習部分のモデルを改良したり最新の深層強化学習手法を適用することで、もっと安定させられる可能性は高いです。
実験結果のまとめ
- 上手く学習すると、以下のような性能を出せる場合がある
- 攻撃や各種呪文を上手く使い分けできるようになる
- 生存率は9割程度で、事前の想定に対して十分な学習を行える
- 学習結果が大きくブレるため、実運用へ適用するには学習を安定させることが課題。
感想
今回の実験を行う前、私が最後に強化学習に触れたのは2012年でした。
それから約9年。当時の強化学習ではとても考えられないほど圧倒的に高い性能をたたき出してくれたので、個人的にはとても感動しました。実運用に耐えるほどの性能ではないものの、実験中は実際にAIの学習結果を見ながらゲームバランスを調整していました。ゲーム開発をしていると、開発者はゲームを熟知しているが故に、ゲーム知識の浅い一般プレイヤーを想定したテストプレイを行うのは難しいケースが多いと思います。しかし今回の結果では熟練者(≒開発者)より少し劣ったプレイ内容になるため、AIがまさに一般プレイヤー相当のテストプレイをしてくれていると感じられました。将来的に深層強化学習がRPGのテストプレイに活用されることも夢ではないと思います。
今回は簡単な実装なのでこの程度の性能で終わりましたが、深層強化学習に精通した人が作れば、ドラクエ1程度の難易度であれば優秀なテストプレイAIを作れるのではないでしょうか。
ちなみに、コーディングに関してはAIの実装よりも学習対象のRPGを作るほうが大変でした(笑)。PyTorchは本当に便利なので、AIに興味のある方は是非PyTorchを使ってみてください。
最後に実験の今後について。この実験は他に「アイテムを使う」「ザコ戦~ボス戦のシナリオを学習する」「多対多のバトルを学習させる」などの構想はあるのですが、今回の結果に割と満足してしまったので、今後この構想が実現するかはわかりません。先に述べたように学習対象のゲームを作るのも地味に大変ですし(笑)。
今後技術が進めば今より手軽に優秀なAIを作れるようになるかもしれないので、気が向いた時にまた実験の続きに挑戦してみたいと思います。
AI作成の参考URL
Chainer Tutorial
PyTorch 1.5 Tutorials : 強化学習 : 強化学習 (DQN) チュートリアル
【秒速で無料GPUを使う】深層学習実践Tips on Colaboratory