概要
Pythonを勉強しています。休日予定が入っていなくて今日は一日中コードが書けるなと思っていたらひょんなきっかけで自分用簡易辞書をつくっていました。
その軌跡を追います。
なぜ作った?
英語のニュアンスを知りたいときあるけどコード書いてたら一々辞書に手を出すのもなーってときのために作りました。
既存辞書の問題点
私が思うに辞書アプリの不満点がいくつかあった。
- 英語と日本語同時に知りたいよね
- 例文とかも勉強になるけど、そうではなく意味ベースだけでシンプルに短く見たいよね
- 出てくる数選べるといいよね(1個でいいときもあれば、たくさん知りたいときもある)
どうやらこのあたりをかゆいところに手が届くようにしていけばよさそう。
元データどっから持ってきた?
Glosbe API ってやつがあるらしいとどこかで見た。
こいつから今回は取得していこう。
Usage
下記コマンドで動くように実装しました。
>>> python translate.py -p 検索したい文字列
するとどうなるか?
→こうなる

注.筆者はFish 派です。ちなみに先日プロンプトを可愛くしようと思い魚のAAチックなものを描画するようにしましたがあまり可愛くありません。。
さて、コマンドを打つと出力数を入力するようにプロンプトに言われました。
当然のごとくfishの意味は知りたいところなのでfishの意味を調べます。
魚と出てくるのはわかりきっているので、今回は3つ日本語の意味を検索します。
するとどうなるか?
→こうなる
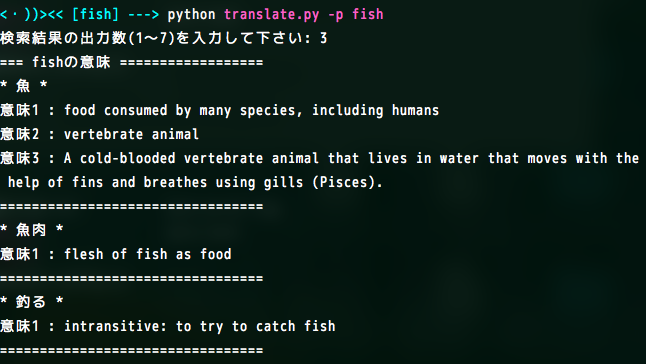
なるほど。
魚の意味は当然だけれども、魚肉と釣る(動詞)の意味もあるのね。
さらに英語の意味も読むと色々とニュアンスがわかる。
これにて目標達成であります。
実際はpythonのヘルプを使ったときにコマンド叩いてニュアンスがわかるように使おうと思っておる。
今回使ったPythonバージョンとライブラリ
Pythonは3.7.0を利用しています。
- urllib
- 今回はurlopenを使ってGlosbe APIからとってきた。
- json
- HttpResponseから返ってきたものをjsonで取りました。
- re
- 正規表現につかった。
- click
- Pythonだとargparseでコマンドが作れるけどclickだともっと便利です。
クラスつくった
class Meaning:
def __init__(self, phrase, japanese, english=None):
"""初期化
:param phrase: str
検索文字
:param japanese: str
日本語訳
:param english: str
英語訳
"""
self.phrase = phrase
self.japanese = japanese
self.english = english
def look_up(self):
print("* " + self.japanese + ' *')
if self.english:
self._extract_mean()
else:
print("適切な英語の説明がありませんでした。")
def _extract_mean(self):
for i, mean in enumerate(self.english, 1):
text = mean['text']
# e.gという文字とesp.という文字は改行しないようにした
eg_regex = re.search('e.g.', text)
esp_regex = re.search('esp.', text)
if not any([eg_regex, esp_regex]):
text = text.replace('. ', '.\n\t')
else:
text = mean['text']
if mean['language'] == 'ja':
continue
print(f"意味{i} : {text}")
とくにクラスについて言うことはない。。。と思ったらpython3.6以降は文字列連結にNewStyleの書き方があるのでそこを注意くらい
# この部分
print(f"意味{i} : {text}")
Clickは超便利でした
今回Clickを初めて使ってみた。
import click
# 中略
# オプションはこう書く(デフォはpythonにしてみた)
@click.command()
@click.option('--phrase', '-p', default='python', help='検索したい文字列が必要です')
def cmd(phrase):
# プロンプトに渡したいときはこう書く(デフォだとstrだが型指定できる)
num = click.prompt('検索結果の出力数(1〜7)を入力して下さい', type=int)
if num == 0: raise click.BadParameter("出力数は1以上にしてください")
if num > 7: raise click.BadParameter("そんなに出力できません。")
# 中略
def main():
cmd()
if __name__ == '__main__':
main()
argparseを少し触ったことある人ならこっちの理解はほぼ即座にできるんじゃないだろうか。
便利ですね。
最後に全体のコードをまとめて貼っておく。
from urllib.request import urlopen
import json
import click
import re
BASE_URL = "https://glosbe.com/gapi/translate"
class Meaning:
def __init__(self, phrase, japanese, english=None):
self.phrase = phrase
self.japanese = japanese
self.english = english
def look_up(self):
print("* " + self.japanese + ' *')
if self.english:
self._extract_mean()
else:
print("適切な英語の説明がありませんでした。")
def _extract_mean(self):
for i, mean in enumerate(self.english, 1):
text = mean['text']
eg_regex = re.search('e.g.', text)
esp_regex = re.search('esp.', text)
if not any([eg_regex, esp_regex]):
text = text.replace('. ', '.\n\t')
else:
text = mean['text']
if mean['language'] == 'ja':
continue
print(f"意味{i} : {text}")
def get_url(phrase):
"""Glosbe API により、引数に与えられた単語の翻訳を取得
:param phrase:
"""
tarnslated_ja = "?from=en&dest=ja"
phrase_arg = f"&phrase={phrase}"
url = f"{BASE_URL}{tarnslated_ja}&format=json{phrase_arg}&pretty=true"
return url
def load_json(json_data):
loaded = json.loads(json_data)['tuc']
if not loaded:
raise click.exceptions.BadParameter("検索した結果,見つかりませんでした")
for json_dict in loaded:
yield json_dict
@click.command()
@click.option('--phrase', '-p', default='python', help='検索したい文字列が必要です')
def cmd(phrase):
num = click.prompt('検索結果の出力数(1〜7)を入力して下さい', type=int)
if num == 0: raise click.BadParameter("出力数は1以上にしてください")
if num > 7: raise click.BadParameter("そんなに出力できません。")
url = get_url(phrase)
response = urlopen(url)
json_data = response.read().decode("utf-8")
data = load_json(json_data)
for counter, mean_pair in enumerate(data):
if counter == 0: print(f'=== {phrase}の意味 ==================')
if counter > num - 1: break
try:
japanese = mean_pair['phrase']['text']
except:
raise click.BadParameter("見つかりませんでした")
english = mean_pair['meanings'] if 'meanings' in mean_pair else None
mean = Meaning(phrase, japanese, english)
mean.look_up()
print("=================================")
def main():
cmd()
if __name__ == '__main__':
main()