簡単な流れ
1.pandas.read_csvでcsvファイルを一括読み込み
2.itertuplesメソッドによって得たイテレータをfor文で回し,一行ずつ解析
3.要素の更新にはatまたはiatを利用し個別に操作(replace等を使えばまとめての更新が可能)
4.to_csvで書き込み
サンプル.py
関数として実装すると下記のようになります.
import pandas as pd
def csvEdit(path_csv):
csv = pd.read_csv(path_csv)
for row in csv.itertuples():
csv.at[row[0], 'hoge'] = huga
csv.to_csv(path_csv)
少しだけitertuplesについて説明します.rowに格納されるタプルですが,これには先頭にindex名,そしてその行のデータが格納されています.rowはただのコピーなので代入等の要素操作は元データであるcsvに行ってください.
また,csvファイルの形によってはiterrowsメソッドの使用の検討をおすすめします.インデックスを明記している場合や特別に扱う必要がある場合ですね.
実行例
先ほどの関数内にprintを加えて実行してみます.encoding, indexの指定もしておきます.
実行前
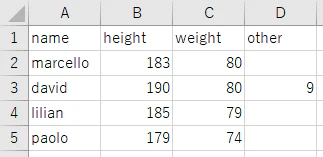
sample.py
import pandas as pd
def csvEdit(path_csv):
csv = pd.read_csv(path_csv, encoding='utf-8')
for row in csv.itertuples():
csv.at[row[0], 'weight'] -= 5
print(row)
csv.to_csv(path_csv, encoding='utf-8', index=False)
if __name__ == '__main__':
_ = csvEdit("sample.csv")
terminal
Pandas(Index=0, name='marcello', height=183, weight=80, other=nan)
Pandas(Index=1, name='david', height=190, weight=80, other=9.0)
Pandas(Index=2, name='lilian', height=185, weight=79, other=nan)
Pandas(Index=3, name='paolo', height=179, weight=74, other=nan)
実行後

全員5キロの減量に成功しました!
次回 第-7回では...
一行ごとのデータ数を増やします.deadlineに細かく時間まで設定できるようにしたり,習慣の場合は曜日指定ができるようにする予定です.