統計において、母分散の区間を求めたい時などに出てくるχ二乗分布。
χ二乗検定などでクロス表を扱ったりと、ちらほら「χ二乗」には関わることがあります。
実用性において、「χ二乗分布の公式やt分布との関係性を熟知しておく必要がない」と
個人的な意見はありますが、それでも統計検定2級とかでちゃんと出てくる(そして、私は自宅で初見で解いて爆死した)ので、「しっかりと」χ二乗分布についてみていこうと思います。
標本分散とχ二乗分布
標本(不偏)分散
まずは標本(不偏)分散から。
母集団の推測を目的とするため、標本から分散を求めるには「不偏分散」を用いますが、参考書によっては当たり前のように「標本分散」と記載があったりします。
流派があるかもなんですが、ここでの標本から求める分散は以下で定義するものとします
$$ \hat{σ} = \frac{1}{n-1} \sum_{i=1}^{n}(x_i - \bar{x})^2$$
この$\hat{σ^2}$は性質として、平均的に母分散$σ^2$と等しくなる(E[$\hat{σ}^2$] = $σ^2$ これを不偏性と言います)わけですが、もちろん数回だけではバラつきます
修正χ二乗
まず、母分散を求めたいとか区間推定したい、という話の前に、母分散$σ^2$と$\hat{σ^2}$を使って、
$$C^2 = \frac{\hat{σ^2}}{σ^2}$$
を考えます。
この$C^2$というのは修正χ二乗と言われて、平均的には1に落ち着きます
(なぜなら不偏分散の期待値は$σ^2$なので)
しかし、いつも1ではなく、当然1よりも大きな値も小さい値(あくまで非負の範囲)も取りうることになり、これは一般的に自由度(今回ならn-1)により、グラフが変わってきます。
(自分が不慣れにkeynoteで作ったグラフなので、精緻なグラフでもなんでもないですw あくまでイメージ)

しかし、この$C^2$はおそらく普通の参考書とかに出てこないです。
数値として0以上でかつ1のとき完全一致するというわかりやすいんですが、基本的には$χ^2$が使われます
χ二乗
今、母集団(N(μ, $σ^2$))において、n個のサンプル($x_1, x_2,,, x_n$)とすると、$χ^2$は
$$χ^2 = \sum_{i-1}^{n}(\frac{x_i - μ}{σ})^2$$
で表現されます。(μ、σはそれぞれ母数)
これだけ書いても「あ、そーなんですね!」で会話が終わらせられるので、噛み砕いていうと、
「サンプルから平均を引いて標準偏差で割ったものであり、これは標準化そのもの。
つまり、これはN(0, 1)のn個の独立な要素の平方和は$χ^2$分布をする」
って感じです。
ちなみに、母数を使ったこの$χ^2$分布の自由度はnです(xiのどれもμで表したりできないので、そのままn)
この母平均μを標本平均$\bar{x}$に置き換えると、
$$χ^2 = \sum_{i-1}^{n}(\frac{x_i - \bar{x}}{σ})^2 = \frac{(n-1)\hat{σ}^2}{σ^2} = (n-1)C^2$$
となり、一般的な書籍と同じ形になりました。
この$χ^2$分布に関しては、自由度はn-1となります
(たとえば、$x_nはx_1,・・・, x_{n-1}と\bar{x}$で表現できるので、n-1)
つまり、母数を使う場合と標本平均を使う場合とでは、自由度の違う$χ^2$分布になるということです。
χ二乗の性質
確率変数X~$χ^2(n)$のとき、
- 期待値(平均値)は$E[X] = n $
- 分散は$V[X] = 2n$
という性質があります
(導出はχ二乗の確率密度関数の積分とかなので、割愛。
さすがにχ二乗の確率密度関数は覚えるものではないw)
加法性
χ二乗は分散との共通性質もあり、例えば、$χ_1^2: 自由度n_1, χ_2^2: 自由度n_2$であるとき、
$χ^2 = χ_1^2 + χ_2^2の自由度はn_1+n_2$
となります(3つ以上でもOK,χ_i^2は独立)
t分布との関係性
χ二乗もt分布も標本から計算される数値を扱っているため、共通点を持っています。
実際導出まではしないのですが、一般的にt分布と自由度nのχ^2変数を用いて、以下のような等式が成り立つことが知られています。
$$t(n) = \frac{N(0, 1)}{\sqrt{\frac{χ^2(n)}{n}}}$$
(導出はt分布の統計量、標準正規分布の統計量を用いれば、上記で扱ってきたχ^2の組み合わせで算出できます)
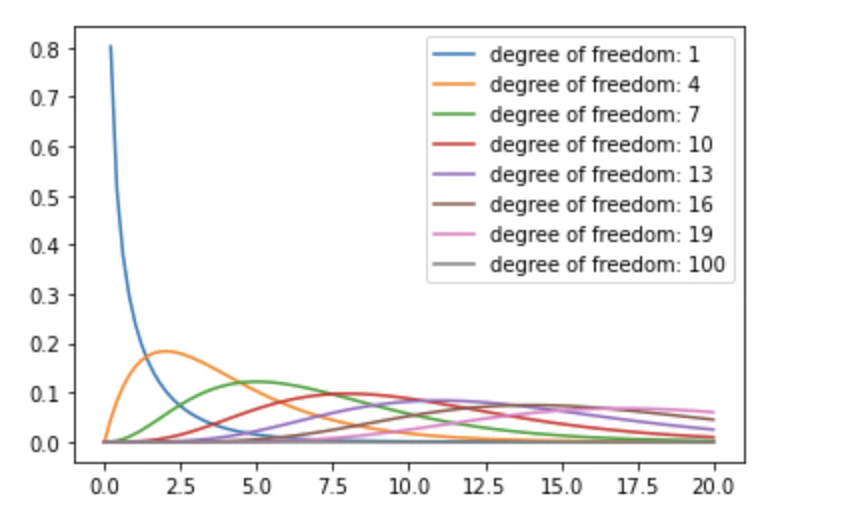
Pythonでχ二乗をプロット
我々は手計算でχ二乗をゴリゴリ計算することはほとんどないので、pythonをつかってχ二乗を扱ってみます。
まずば確率密度関数を見ます
import numpy as np
import matplotlib.pyplot as plt
from scipy import stats
x = np.linspace(0, 20, 100)
for df in range(1, 20, 3):
plt.plot(x, stats.chi2.pdf(x, df), label=f'degree of freedom: {df}')
plt.plot(x, stats.chi2.pdf(x, 100), label='degree of freedom: 100')
plt.legend()
plt.show()
検定をしたい場合はchi2_contigencyメソッドとかがありますが、今回は検定の話ではないので、省略