統計のなかの検定で一番ハードなのは分散分析かなと思います(あくまで統計検定2級とかの話)
お作法としては淡々としてたり、統計検定では1から全て求めるみたいなことはありません。
しかし、その影響か「なんとなく」の理解で終わってしまっている方(=私)も多いのかなと思います。
そこで、理解の深化も兼ねて分散分析を(個人的主観で)丁寧に扱っていこうと思います。
いろんな知識が必要であるため一度に理解するのは大変ですが、頑張っていきましょう。
前提として何を言いたいのか?
まずは分散分析をする目的を知りましょう。
分散が絡んでくることには間違いないのですが、目的は
「3つ以上の母集団のうち、それぞれの平均に差があるのかどうか?」
ということを知りたいときに分散分析が用いられます。
(※分散分析においては母集団を「級」と呼びます。のちに出てきます)
例えば
- A, B, C高校の数学のテストの平均点に差があるのか?
- 自動車のA, B, C社が作る燃料効率には差がありますか?
というときは分散分析を使います。
大抵の検定は1つの統計量が本当に起こりうるのか?ということを重視し、等分散性でも2つの母集団のみで比べましたが、分散分析は3つ以上を対象とします。
実際に見ていく
では、順番に流れを追っていきます
前提のデータ
まずm個の母集団があり、各母集団から$n
_1, n_2, ・・・, n_m$個の標本をとってきます。
(第i母集団: $n_i$)
そして、これらのm個の母集団の要素はそれぞれ正規分布N($μ_i$, σ)に従うものとしています
注意点としてそれぞれの母集団の分散は全てσであり、共通しているという前提があります
(これを事前に確かめるには、以前書いた等分散性をつかって検定しておきます。
今回はすでに分散には差がないことは確認済みであるとして進めます)
以下はそれぞれに得られる統計量を書き表したもの。
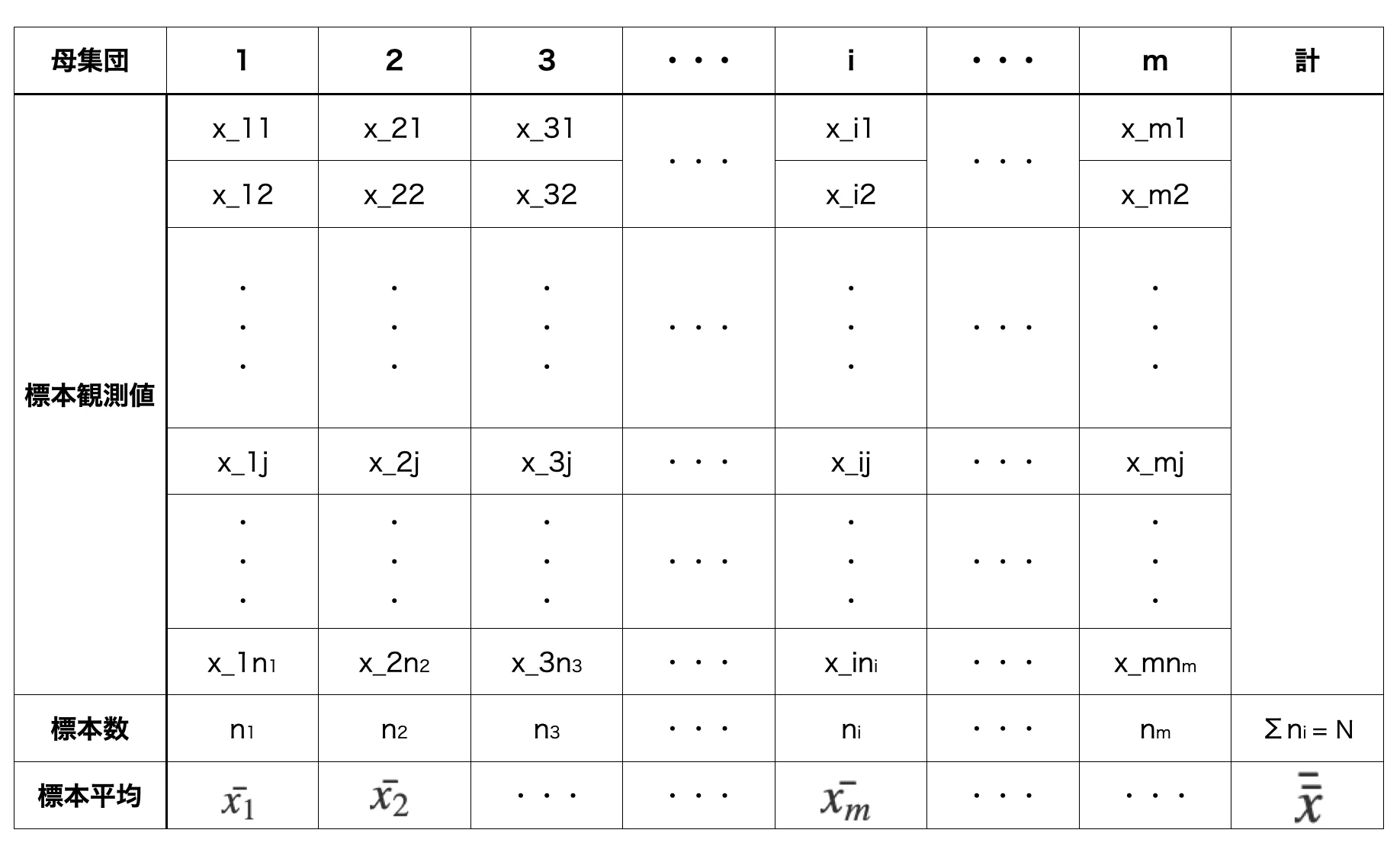
総標本数はNとしています。
帰無仮説
今回は平均の差がないことを言いたいので、
$H_0$: それぞれの母集団において平均$μ_i$には差がない
とします。
少し言い換えると、
$$μ = \frac{\sum n_i μ_i}{N}$$
という全体平均を考えると、それぞれの母平均$μ_i$は
$$μ_i = μ + α$$
と表現できるため、帰無仮説を言い換えて
任意のiでα=0である
を示すことにもなります。
対立仮説
対立仮説としては
- 少なくとも一つのiで差がある
- 少なくとも一つのiでα ≠ 1 となる
と設定します
検定
では、順に分散分析の流れを体験していきます。
まず全てのサンプルを使って平均$\bar{\bar{x}}$を求めると、
$$\bar{\bar{x}} = \frac{1}{N} \sum_{i=1}^{m} \sum_{j=1}^{n_i} x_{ij}$$
それぞれの母集団iに対しての標本平均を$\bar{x_i}$とすると
$$\bar{x_i} = \frac{1}{n_i} \sum_{j=1}^{n_i}x_{ij}$$
ここで平均に対しての差を知りたいため、全体に対する偏差平方和Vを考えます
\begin{align}
V &= \sum_{i=1}^{m} \sum_{j=1}^{n_i} (x_{ij} - \bar{\bar{x}})^2 \\
&= \sum_{i=1}^{m} \sum_{j=1}^{n_i} (x_{ij} - \bar{x_i} + \bar{x_i} - \bar{\bar{x}})^2 \\
&= \sum_{i=1}^{m} \sum_{j=1}^{n_i} (x_{ij} - \bar{x_i})^2 + \sum_{i=1}^{m} \sum_{j=1}^{n_i} (\bar{x_i} - \bar{\bar{x}})^2 + 2\sum_{i=1}^{m} \sum_{j=1}^{n_i} (x_{ij} - \bar{x_i})(\bar{x_i} - \bar{\bar{x}}) \\
&= \sum_{i=1}^{m} \sum_{j=1}^{n_i} (x_{ij} - \bar{x_i})^2 + \sum_{i=1}^{m} \sum_{j=1}^{n_i} (\bar{x_i} - \bar{\bar{x}})^2 + 2\sum_{i=1}^{m} (\bar{x_i} - \bar{\bar{x}})\sum_{j=1}^{n_i} (x_{ij} - \bar{x_i}) \\
&= \sum_{i=1}^{m} \sum_{j=1}^{n_i} (x_{ij} - \bar{x_i})^2 + \sum_{i=1}^{m} \sum_{j=1}^{n_i} (\bar{x_i} - \bar{\bar{x}})^2 + 2\sum_{i=1}^{m} (\bar{x_i} - \bar{\bar{x}})(n_i * \bar{x_i} - n_i * \bar{x_i}) \\
&= \sum_{i=1}^{m} \sum_{j=1}^{n_i} (x_{ij} - \bar{x_i})^2 + \sum_{i=1}^{m} \sum_{j=1}^{n_i} (\bar{x_i} - \bar{\bar{x}})^2 \\
&= \sum_{i=1}^{m} \sum_{j=1}^{n_i} (x_{ij} - \bar{x_i})^2 + \sum_{i=1}^{m} n_i (\bar{x_i} - \bar{\bar{x}})^2 \\
&= V_1 + V_2
\end{align}
導出の過程自体は非常にシンプルな計算で導出できます
これからわかるように、この全ての標本との総平均の差の偏差平方和は
[(各要素(データ)-それぞれの要素が属する母集団の平均)の平方和]
+
[(各母集団の平均 - 全ての平均)の平方和]
に帰着することになります。
今、すべての母集団の分散はσであることから、
各標本と標本平均の偏差平方和と分散の比である$χ^2$を考えると良さそう!ってなります
文章で書くと周りくどいですが、数式としては以下。
$χ^2 = \frac{(n-1)\hat{σ^2}}{σ^2}$
このことから、
$$\sum_{i=1}^{m} \sum_{j=1}^{n_i} (\frac{x_{ij} - \bar{\bar{x}}}{σ})^2 = \frac{V}{σ^2}$$
は自由度N - 1の$χ^2$分布に従います。
そして、$χ^2$の加法性からV1 ~ $χ^2$(N-m), V2 ~ $χ^2$(m-1)に従うことがわかります。
かなり、複合的なアプローチをしているため、十分に理解していないといけない感ありますね。。
※各標本はN(μ, $\frac{σ^2}{n_i^2}$)に従うので、
$$\sum_{i=1}^{m} n_i (\frac{\bar{x_i} - \bar{\bar{x}}}{σ})^2 = \sum_{i=1}^{m} (\frac{\bar{x_i} - \bar{\bar{x}}}{\frac{σ}{\sqrt{n_i}}})^2 = \frac{V_2}{σ^2}$$
今、$V_1, V_2$それぞれの$χ^2$分布の自由度がわかったのでF値を計算できるようになりました
$$F_0 = \frac{\frac{V_2}{m-1}}{\frac{V_1}{N-m}}$$
つまり、このF値はF(m-1, N-m)の分布に従うため、あとは付表などで参照し、有意水準に達するかどうかを見ていきます。
そもそも帰無仮説は平均に差がないということなので、$F_0$は1に近いと想定されるはずですが、差があるとそれだけ数値は大きくなります。
用語の確認
なんの気無しに使ってきた$V_1, V_2$ですが、ちゃんと用語があります。
もう一度$V_1, V_2$がどういうものかおさらいしておくと
\begin{align}
V_1 &= \sum_{i=1}^{m} \sum_{j=1}^{n_i} (x_{ij} - \bar{x_i})^2 \\
V_2 &= \sum_{i=1}^{m} n_i (\bar{x_i} - \bar{\bar{x}})^2
\end{align}
でした。
ちょっと最初に準備した標本の欄を見て確認しましょう
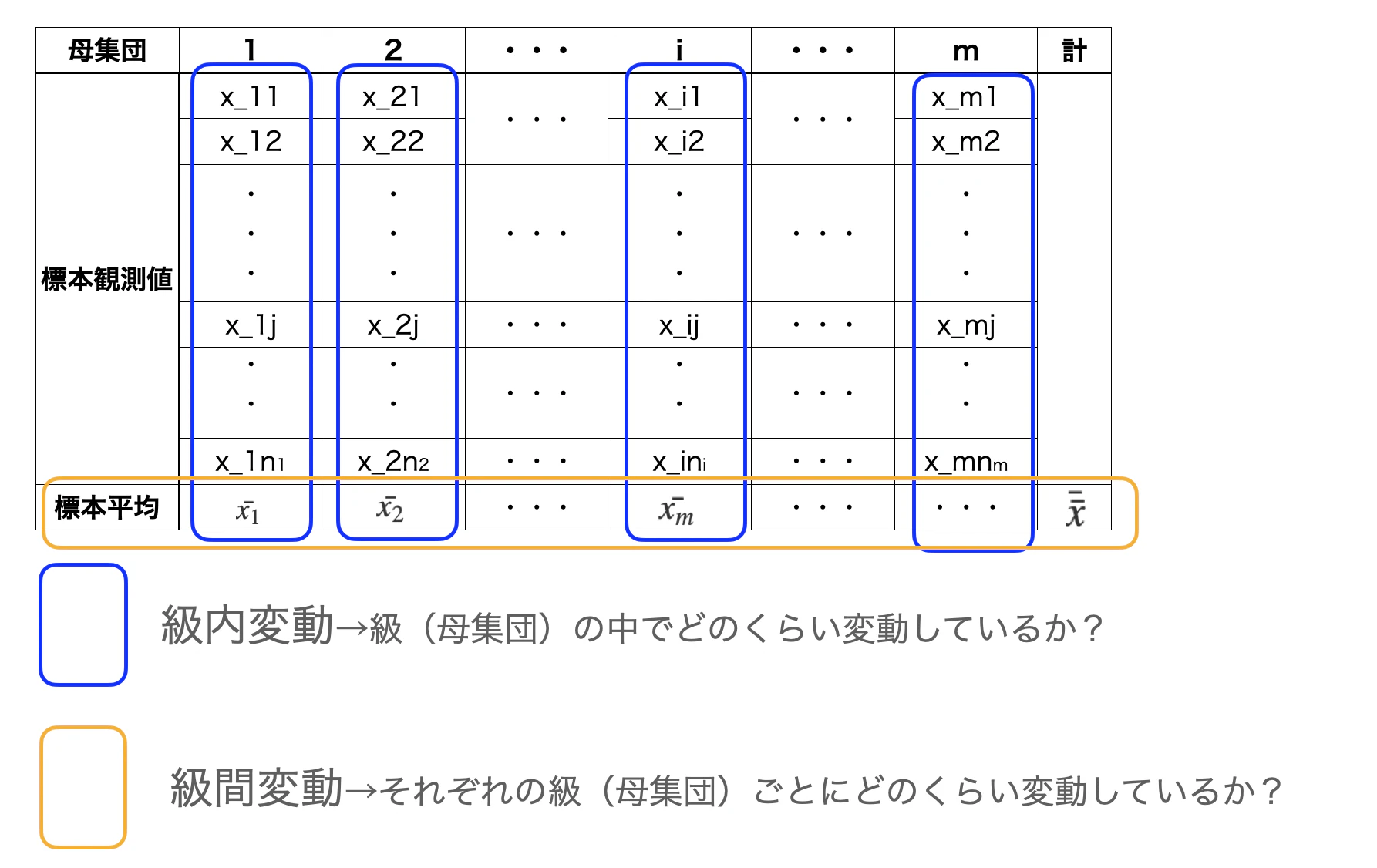
だいたいこれがイメージであり、これが全てといった感じです。
各要素に対して全体を見ているVをブロックに切り分けていく、と思えば十分と思います。
それに上記の図からもそれぞれの自由度もわかると思います(級間変動は要素mなので、m-1となるとか)
それぞれの普遍性
$χ^2$の性質に普遍性として$E[χ^2] = n-1(自由度)$となるため、以下が成り立ちます
\begin{align}
E[\frac{V_2}{σ^2}] &= m- 1 ⇨
E[\frac{V_2}{m- 1}] = σ^2 \\
\\
E[\frac{V_1}{σ^2}] &= N - m ⇨
E[\frac{V_1}{N - m}] = σ^2
\end{align}
分散分析表(よく見る「あの表」)
大抵のテキストに載っている分散分析表を見て理論の部分は締めくくりたいと思います。
といっても、上記の流れを簡略して書いているだけのため、さらっと見て終わりにしようと思います。
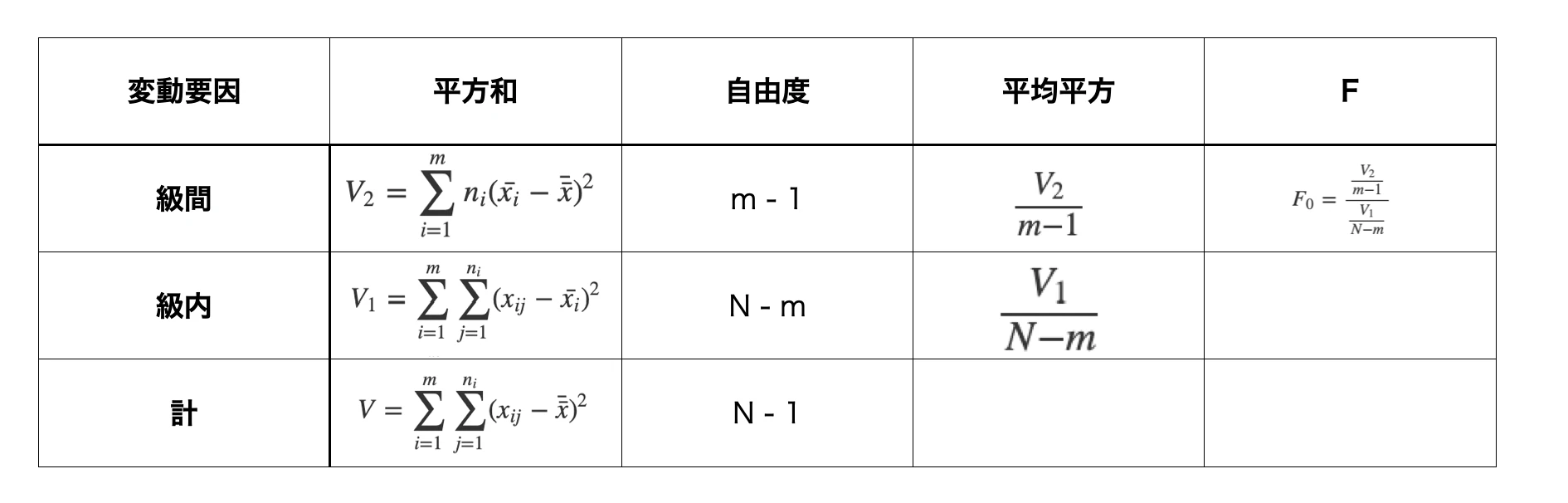
おそらく参考書によっては「分散分析はこの表でドン!」みたいに片付けていると思うのですが、なぜこんなことをしているのか?というと「分散の比が$χ^2$分布に従う」という性質を利用しているから自由度で割ったりしているわけです。
実際にこれらの表の全てを手計算するということは現実問題ほぼないと思いますが、統計検定では部分的に穴埋めすることもあるので、何しているのか?という理解はしておくと便利だと思います。
Pythonで分散分析してみる
では、ラストは実際にデータを用意しながら分散分析をしてみます
いつもながらコードの説明はコメントアウトなどのみで行っていきます。
手動でゴリゴリ
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from scipy import stats
# 各母集団のデータを準備
rng = np.random.default_rng(seed=123)
data1 = rng.integers(4, 10, size=10)
data2 = rng.integers(4, 14, size=8)
data3 = rng.integers(2, 9, size=13)
# それぞれの平均を求め、級内変動・級間変動をみる
mean_1 = np.mean(data1)
mean_2 = np.mean(data2)
mean_3 = np.mean(data3)
mean_all = np.mean([mean_1, mean_2, mean_3])
# 級内変動
V_1_1 = sum((data1 - mean_1)**2)
V_1_2 = sum((data2 - mean_2)**2)
V_1_3 = sum((data3 - mean_3)**2)
V1 = V_1_1 + V_1_2 + V_1_3
# 級間変動
V_2_1 = len(data1) * (mean_1 - mean_all)**2
V_2_2 = len(data2) * (mean_2 - mean_all)**2
V_2_3 = len(data3) * (mean_3 - mean_all)**2
V2 = V_2_1 + V_2_2 + V_2_3
print(f'V1:{V1:.2f}\nV2: {V2:.2f}')
# 自由度
dof_all = len(data1) + len(data2) + len(data3) - 1
dof_V2 = 3 - 1
dof_V1 = dof_all - dof_V2
print(f'級内の自由度: {dof_V2}')
print(f'級間の自由度: {dof_V1}')
# 平均平方
V2_dof = V2 / dof_V2
V1_dof = V1 / dof_V1
# F値
F = V2_dof / V1_dof
print(f'F値: {F:.3f}')
# 分散分析(scipy)
p_value = 1 - stats.f.cdf(F, dfn=dof_V2, dfd=dof_V1)
print(f'分散分析(scipy): {p_value}')

scipyなら一行
stats.f_oneway(data1, data2, data3)

ちなみに、statsmodels.formula.apiのolsでも同様のことが可能ですが、今回意図的にサンプル数を変えた状態なので、もしDataFrameでも試してみたい!って場合はどぞ!
終わり
他のサイトよりはやや深めなアプローチができたかなと思いますが、かなりいろんな知識が必要だったりするので、難しいですね!
ま、全部覚える必要もなく、わからないときに調べて思い出すくらいでちょうど良きかと思います!