sklearn.preprocessing.MinMaxScalerを使用した正規化
MinMaxScalerによる正規化とは
以下の式による 0 から 1 の範囲への変換
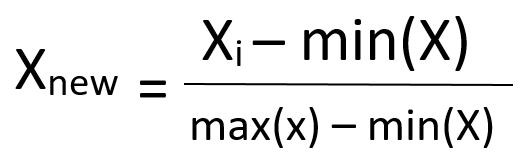
コード例
緯度と経度などあらかじめ最小・最大値が決まっている場合の使用例
サンプルデータ
import numpy as np
from sklearn.preprocessing import MinMaxScaler
# 東京都内の緯度経度サンプルデータセット
sample = np.array([[35.6712, 139.7665], [35.6812, 139.7671], [35.6580, 139.7016]]) # shape=(3, 2)
=> array([[ 35.6712, 139.7665],
[ 35.6812, 139.7671],
[ 35.658 , 139.7016]])
最小・最大値の定義
# 最小値と最大値を定義
# [緯度, 経度]
min_li = [-90, -180]
max_li = [90, 180]
min_max_li = np.array([min_li, max_li]) # shape=(2, 2)
# 正規化で使用する最小値と最大値を定義
mmscaler = MinMaxScaler(feature_range=(0, 1), copy=True)
mmscaler.fit(min_max_li.astype('float'))
# mmscaler.fit(sample) とした場合は、サンプルデータの各列に対して最小値と最大値を自動で定義
正規化
正規化するデータは、最小・最大値を定義する際に使用したデータと同じ列数でなければいけない
今回は緯度と経度の2列
# サンプルデータに対して正規化
scaled_sample = mmscaler.transform(sample)
=> array([[0.69817333, 0.88824028],
[0.69822889, 0.88824194],
[0.6981 , 0.88806 ]])
非正規化(正規化前に戻す)
# サンプルデータを非正規化
mmscaler.inverse_transform(scaled_sample)
=> array([[ 35.6712, 139.7665],
[ 35.6812, 139.7671],
[ 35.658 , 139.7016]])