前回の備忘録
前回のあらすじ
前回のコード
#include <thread>
#include <iostream>
const int COUNT_MAX = 10000;
int main(void)
{
int ret = 0;
//マルチスレッド
std::thread thread1([&]() {
for (int c = 0; c < COUNT_MAX; c++)
{
++ret;
std::cout << "thread1" << ret << std::endl;
}
});
//マルチスレッド
std::thread thread2([&]() {
for (int c = 0; c < COUNT_MAX; c++)
{
++ret;
std::cout << "thread2" << ret << std::endl;
}
});
//スレッド1,2終了まで待つ
thread1.join();
thread2.join();
std::cout << "return" << ret << std::endl;
return 0;
}
前回は
「変数retが非スレッドセーフなため、結果の整合性が取れない」
「そもそも加算処理自体が非スレッドセーフ」
なので、これらをスレッドセーフにしたい
というところで終了しました。
スレッドセーフの実現
現在、複数のスレッドが一つの変数(メモリ)に対して、同時に処理しているため
結果の整合性が取れていないという状態になっています。
理想は、1つのスレッドの作業中は、もう一つのスレッドは待機状態にする。
つまり、排他制御です。
スレッドセーフの実現には、排他制御を適切に行わなければなりません。
std::atomic
スレッドセーフ実現のための最も基本的な方法として
std::atomicを使用する方法があります。
std::atomicを使用するためには、<atomic>をインクルードする必要があります。
今回のコードでは、既にiostream及びthread内でインクルードされているのか
やらなくても通ります。
#include <thread>
#include <atomic>
#include <iostream>
const int COUNT_MAX = 10000;
//メインスレッド
int main(void)
{
std::atomic<int> ret = 0;
//サブスレッド1
std::thread thread1([&]() {
for (int c = 0; c < COUNT_MAX; c++)
{
++ret;
std::cout << "thread1:" << ret << std::endl;
}
});
//サブスレッド2
std::thread thread2([&]() {
for (int c = 0; c < COUNT_MAX; c++)
{
++ret;
std::cout << "thread2:" << ret << std::endl;
}
});
//スレッド1,2終了まで待つ
thread1.join();
thread2.join();
//結果
std::cout << "return" << ret << std::endl;
return 0;
}
std::atomicで宣言した変数をアトミック変数と呼びます。
この変数への読込、書込は、別スレッドに割り込まれることがありません。
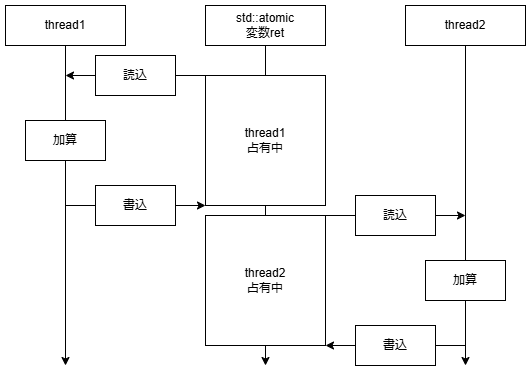
つまり、これで「変数retがスレッドセーフ」になります。
アトミック操作(不可分操作とも)と呼ばれているそうです。
注意点
組み込み型(int,floatなど)は特殊化が提供されていますが、
任意の型の場合、特殊化が提供されていないため、やや特殊な記述が必要になります。
任意の型の場合の実装例1
#include <atomic>
const int COUNT = 1;
/// <summary>
/// 自作構造体(クラス)
/// </summary>
struct Vector2
{
int x;
int y;
Vector2(void)
:x(0), y(0) {};
void Add(void)
{
x += COUNT;
y += COUNT;
}
};
int main(void)
{
std::atomic<Vector2> vec = Vector2();
//数値の読込
Vector2 retVec = vec.load();
retVec.Add();
//数値の書込
vec.store(retVec);
////これは書き込まれない
//vec.load().Add();
return 0;
}
任意の型の場合の実装例2(ポインタ型)
#include <atomic>
const int COUNT = 1;
/// <summary>
/// 自作構造体(クラス)
/// </summary>
struct Vector2
{
int x;
int y;
Vector2(void)
:x(0), y(0) {};
void Add(void)
{
x += COUNT;
y += COUNT;
}
};
int main(void)
{
//元の数値
Vector2 vec = Vector2();
std::atomic<Vector2*> vecAtomic = &vec;
//書き込まれ、元の数値も変化する
vecAtomic.load()->Add();
return 0;
}
c++20以降
生ポインタに抵抗がある方は、<memory>をインクルードすることで、
std::shared_ptr、std::weak_ptrに対する特殊化が提供されるため、ご参考までに。
std::mutex
ここでは、「加算処理そのものをスレッドセーフにする」方法の一つとして、
std::mutexを使用します。
std::mutexを使用するためには、<mutex>をインクルードする必要があります。
前準備として
メンバに変数retとstd::mutexを宣言された変数mutex_(以降mutex)を持ち、
加算処理を行うCountクラスを作成しています。
Countクラス
/// <summary>
/// 加算処理を行うクラス
/// </summary>
class Count
{
public:
void AddRet(const char* threadName )
{
for (int c = 0; c < COUNT_MAX; c++)
{
//ロック
mutex_.lock();
++ret;
std::cout << threadName << ret << std::endl;
//ロック解除
mutex_.unlock();
}
}
}
private:
const int COUNT_MAX = 10000;
int ret = 0;
std::mutex mutex_;
};
main.cpp
#include <thread>
#include <iostream>
#include <mutex>
#include <functional>
//メインスレッド
int main(void)
{
//加算処理を行うクラス
Count counter;
//サブスレッド1
std::thread thread1([&]() {
counter.AddRet("thread1:");
});
//サブスレッド2
std::thread thread2([&]() {
counter.AddRet("thread2:");
});
//スレッド1,2終了まで待つ
thread1.join();
thread2.join();
//結果
counter.PrintRet();
return 0;
}
ここで重点となるのは、Count::AddRet関数内になります。
void AddRet(const char* threadName )
{
for (int c = 0; c < COUNT_MAX; c++)
{
//ロック
mutex_.lock();
++ret;
std::cout << threadName << ret << std::endl;
//ロック解除
mutex_.unlock();
}
}
mutex_.lock()とmutex_.unlock()という記述が存在しています。
std::mutexでは、
1つのスレッドがlock関数を実行すると、unlock関数が実行されるまで、
その処理を占有します。
この時、別のスレッドがAddRetを実行しても、その処理はlock関数で待ち状態になります。
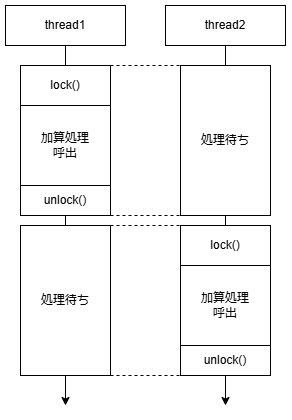
よって、別スレッドと同時に実行されることが無くなり、
変数retの整合性も保たれているため、スレッドセーフになります。
ロックに関係しているクラス
<mutex>内には、ロック管理に関するクラスも存在しています。
基本的に、std::mutexのlock関数、及びunlock関数は
こちらから呼び出すことになります。
std::lock_guard
std::lock_guardを使用することで、
ロック、ロック解除を確実に行うことが出来ます。
コンストラクタでmutexを渡さなければならないことに注意してください。
void AddRet(const char* threadName )
{
for (int c = 0; c < COUNT_MAX; c++)
{
//lock_guardのコンストラクタでロック
std::lock_guard<std::mutex> lock(mutex_);
++ret;
std::cout << threadName << ret << std::endl;
//lock_guardのデストラクタでロック解除
}
}
スコープの先頭で、所有しているmutexのlock関数を行い、
スコープを抜ける際に、デストラクタでmutexのunlock関数を行っています。
std::unique_lock
https://cpprefjp.github.io/reference/mutex/unique_lock.html
「ロックとロック解除を確実に行う」という点では、
std::lock_guardと同じですが、
こちらの方が、より高度な操作が可能になっています。
具体的には、
・コンストラクタではなく、後からロックを取得する(遅延ロック)
・mutexの所有権に関する操作
・任意のタイミングでのmutexのロック操作
・try_lockの存在
などがあります。
最後に
std::timed_mutexなどは、まだ勉強中です。
間違っている部分、理解が浅い部分等は、指摘して頂けると大変助かります。
余談
メモリバリアまたはメモリフェンスなる方法もあるそうです。
std::atomicはこれと組み合わせるべきものなんでしょうか...
次回の備忘録
マルチスレッドを利用した簡易的な衝突判定(特殊な指摘などが無ければ)