この記事は?
Jupyter Notebook 上で CSV を読み込み、列と行を加工して、加工した CSV を出力する方法を記載します。Excel でやればいいとか、Jupyter Notebook 上でやるなら Pandas (Python) でやればいいとかそういう声もあると思います。ただ Jupyter Notebook 上で CSV を加工しながら最終結果を出力したい、かつ Python ではなく使いなれた Ruby でそれを行いたいということもあるかもしれません。
はじめに
Jupyter Notebook のインストール方法、ならびに Jupyter Notebook 上で Ruby を動かす方法については説明を省きます。後者は SciRuby/iruby の README.md が参考になります。
方法
まず Daru をインストールします。Daru は Python における Pandas にあたるデータ分析用のライブラリで、これを使えば CSV を DataFrame という形式で読み込んで加工することができます。
$ gem install daru
ちなみに、これから記載する Ruby コードは全て Jupyter Notebook 上で実行してください。
require 'daru'
今回は例として 男女別人口-全国,都道府県 (大正9年~平成27年) というデータセットの CSV を使います。
CSV は上記のリンク先からダウンロードします。
あるいは次のコードでダウンロードします。
# CSV をダウンロードする。
require 'open-uri'
url = 'https://www.e-stat.go.jp/stat-search/file-download?statInfId=000031524010&fileKind=1'
open(url) do |f|
File.open(File.expand_path('~/Downloads/c01.csv'), 'wb') do |out|
out.write(f.read)
end
end
このままではこの CSV を Daru で扱えません。扱えるようにするには文字コードを変換して、かつ不正な行を取り除きます。
# CSV の文字コードを Shift_JIS から UTF-8 に変換する。また、不正な行を取り除く。
File.open(File.expand_path('~/Downloads/c01.csv'), 'rb:Shift_JIS:UTF-8', undef: :replace) do |f|
CSV.open(File.expand_path('~/Downloads/c01_utf8.csv'),'w') do |csv|
CSV.new(f).each do |row|
# 末尾にコメントが 2 行あるのでそれを取り除く。
next unless row.length == 9
csv << row
end
end
end
これで Daru を使って CSV を読み込むことができます。
df1 = Daru::DataFrame.from_csv(File.expand_path('~/Downloads/c01_utf8.csv'))
Ruby のコードを実行すると、Jupyter Notebook 上に DataFrame の中身が出力されます。
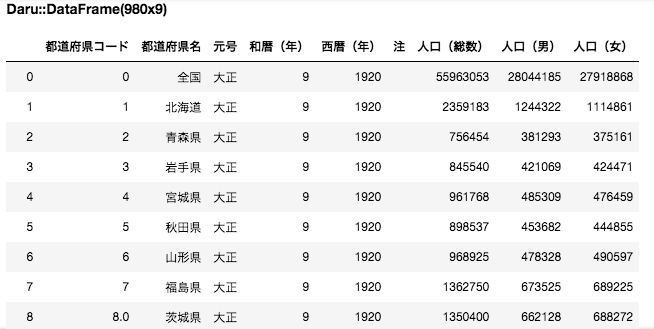
末尾は以下のとおりです。
まず列を加工してみましょう。
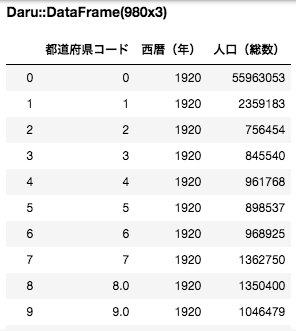
# 列を都道府県コード, '西暦 (年), 人口 (総数) だけに絞り込む。
df2 = df1['都道府県コード', '西暦(年)', '人口(総数)']
次に行を加工してみます。
# 西暦 (年) が 2,000 以上の行だけに絞り込む。
df3 = df2.where(df2['西暦(年)'].gteq(2000))
最後に、加工した DataFrame を CSV に出力します。
df3.write_csv(File.expand_path('~/Downloads/c01_utf8_updated.csv'))
これで完了です ![]()
最後に
もちろん Excel でも CSV の加工は可能ですが、Jupyter Notebook 上で対話的にデータをいじりながら加工できるのは便利です ![]()