概要
ラズパイ4を購入したので、流れ星の電波観測システムをラズパイで作る話をします。
また、毎年12/12~15がふたご座流星群の時期なので、実際に観測できるかやってみました。
原理からの説明になるので話長くなります。
観測原理
流れ星は宇宙を漂う塵が地球大気に飛び込んできて激しく衝突し、プラズマ発光することで出現します。
その時に発生する電離柱というガスが電波を反射する特性があり、その現象を利用することで流星が流れたことを知ることができます。
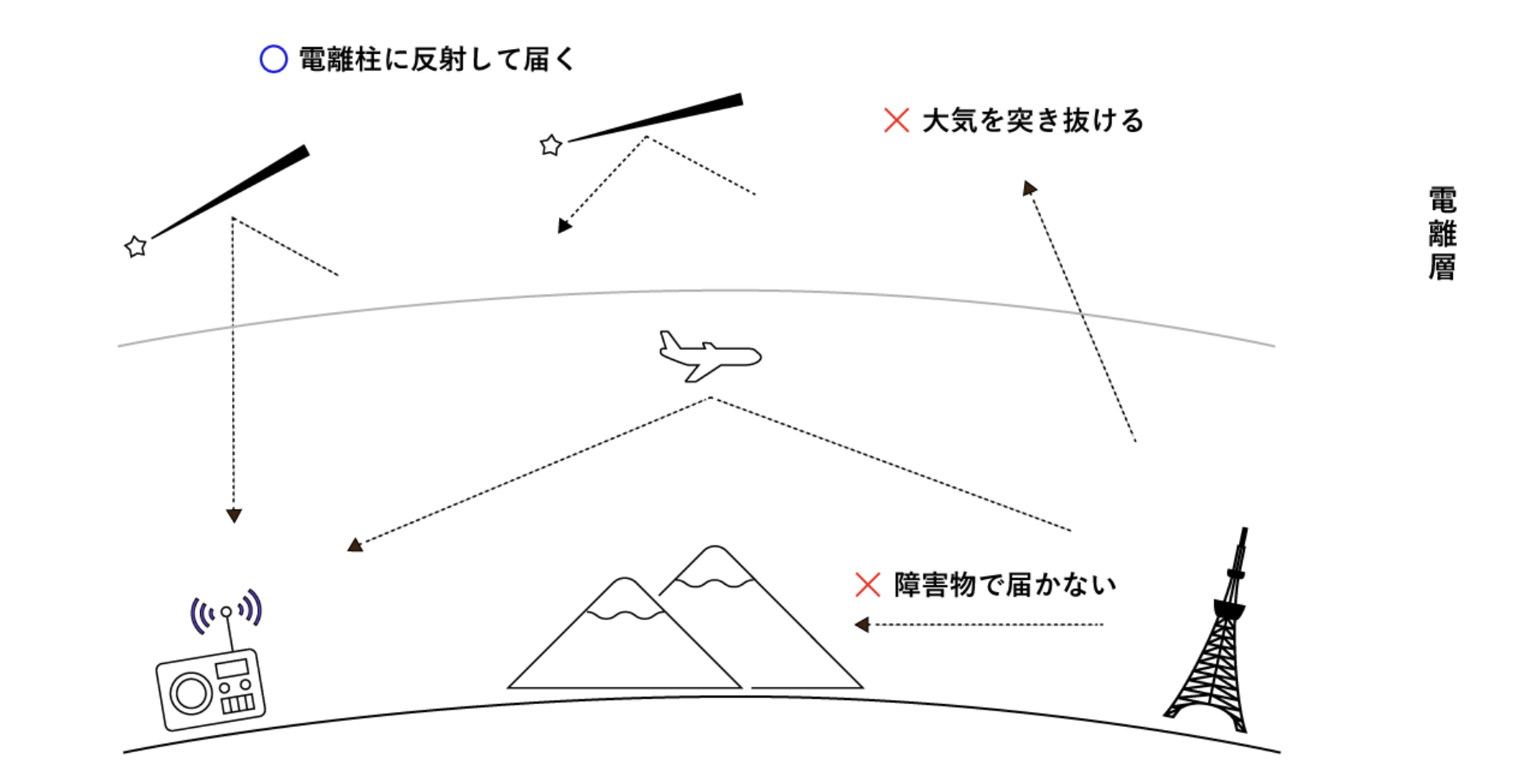
上図のように、普段は物理的に届かない遠方からの電波が流星が流れた瞬間だけ、大気中で反射して届きます。
システム
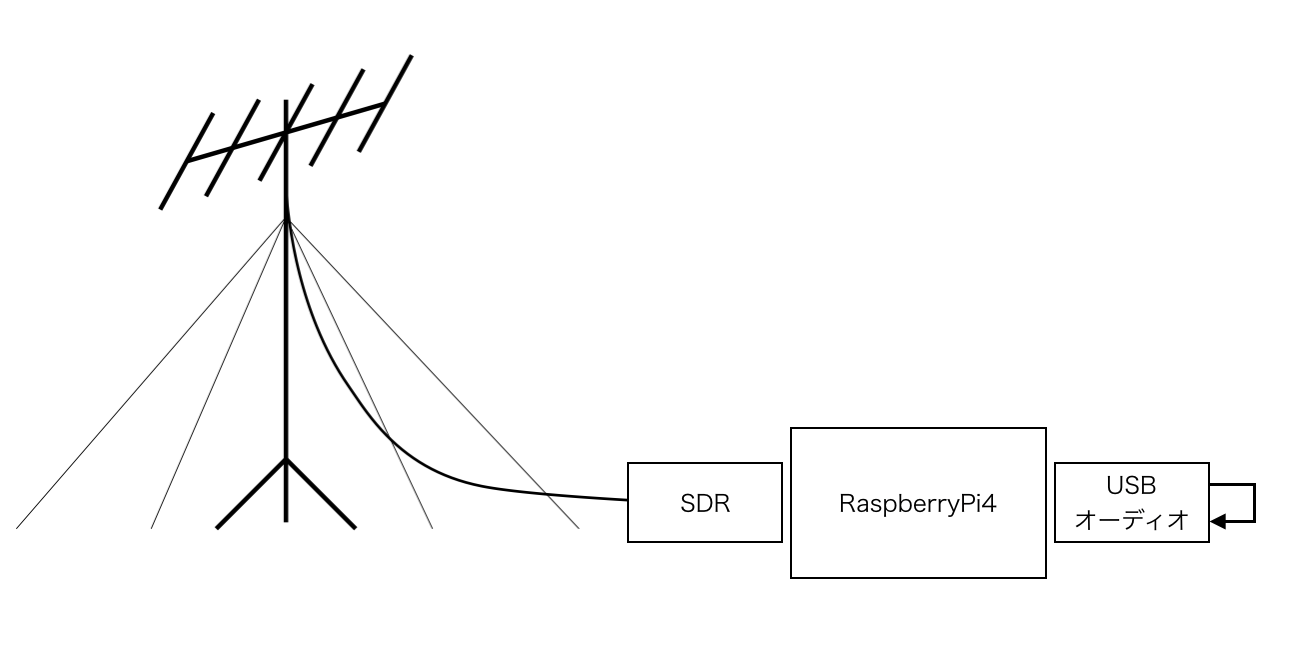
今回は福井県立大から出ている53.755MHzのビーコン波をSDR(ソフトウエアラジオ)で受けます。
アンテナから入ってきた電波が、SDRで音に変換され、その音をUSBオーディオから出力して、さらにそのままマイク入力に入れて、FFTして流星エコーを解析します。
必要なもの

・RaspberryPi4
・USBオーディオ変換ケーブル
・オーディオケーブル
・AirspyMini (ソフトウエアラジオ)
・50MHz帯アンテナ
・同軸ケーブル
・コネクタ各種
(上記のアンテナの場合、M型コネクタになるのでM-SMA型の変換が必要)
全部で3~4万円くらい。
従来のようにアナログ受信機を使った方法だと、アナログ受信機とPCが必要になる為、SDR+ラズパイになったぶんコスト低め。
流れ星が願い事叶えてくれる夢のシステムだと思えば3万円はそんなに高くないはず。
あとボックスに入れて運用できるので、寒い屋外に放置しても心が痛まない。
設置
基本組み立てて繋ぐだけです。
近所の冷ややかな目線を気にせずとにかくアンテナを高い場所にくくりつけて、目標(福井)の空に向けるのです。

エレメントが短い方が前方向です。
セットアップ
ラズパイのセットアップをしていきます。
1. SDRを使えるようにする
今回はgqrxというSDRのソフトを使ってGUIで動かしていきます。
# gqrx ダウンロード
$wget https://github.com/csete/gqrx/releases/download/v2.6/gqrx-2.6-rpi3-2.tar.xz
# 展開
$tar xvf gqrx-2.6-rpi3-2.tar.xz
$cd gqrx-2.6-rpi3-2/
$./setup_gqrx.sh
# 実行
$sh run_gqrx.sh
最初は下記のようなConfigure画面が出てきます。
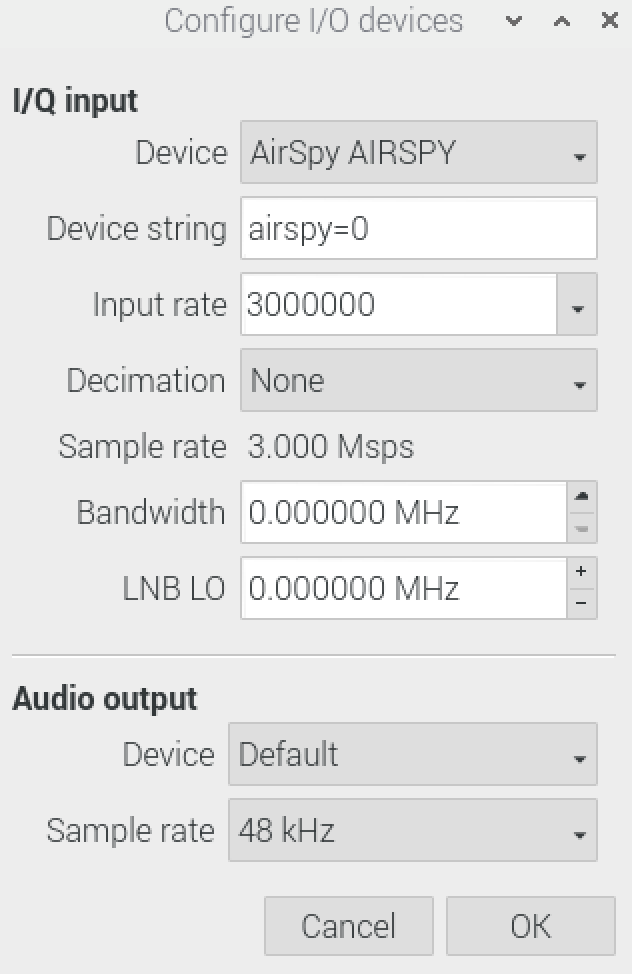
・I/Q inputを『AirSpy AIRSPY』
・Input rateを3000000
にして、あとはデフォルトの設定値で問題ないはずです。
試しにFMラジオの周波数にでもあわせて何か聞こえるか確認してみましょう。
2. 音解析に使うライブラリのインストール
# グラフ描画
$sudo apt install python3-scipy
$sudo pip3 install drawnow
# Audio系
$sudo apt-get install python3-pyaudio
$sudo apt-get install lame
SDRを実行する
SDRのチューニングはちょっと細かい設定が必要です。
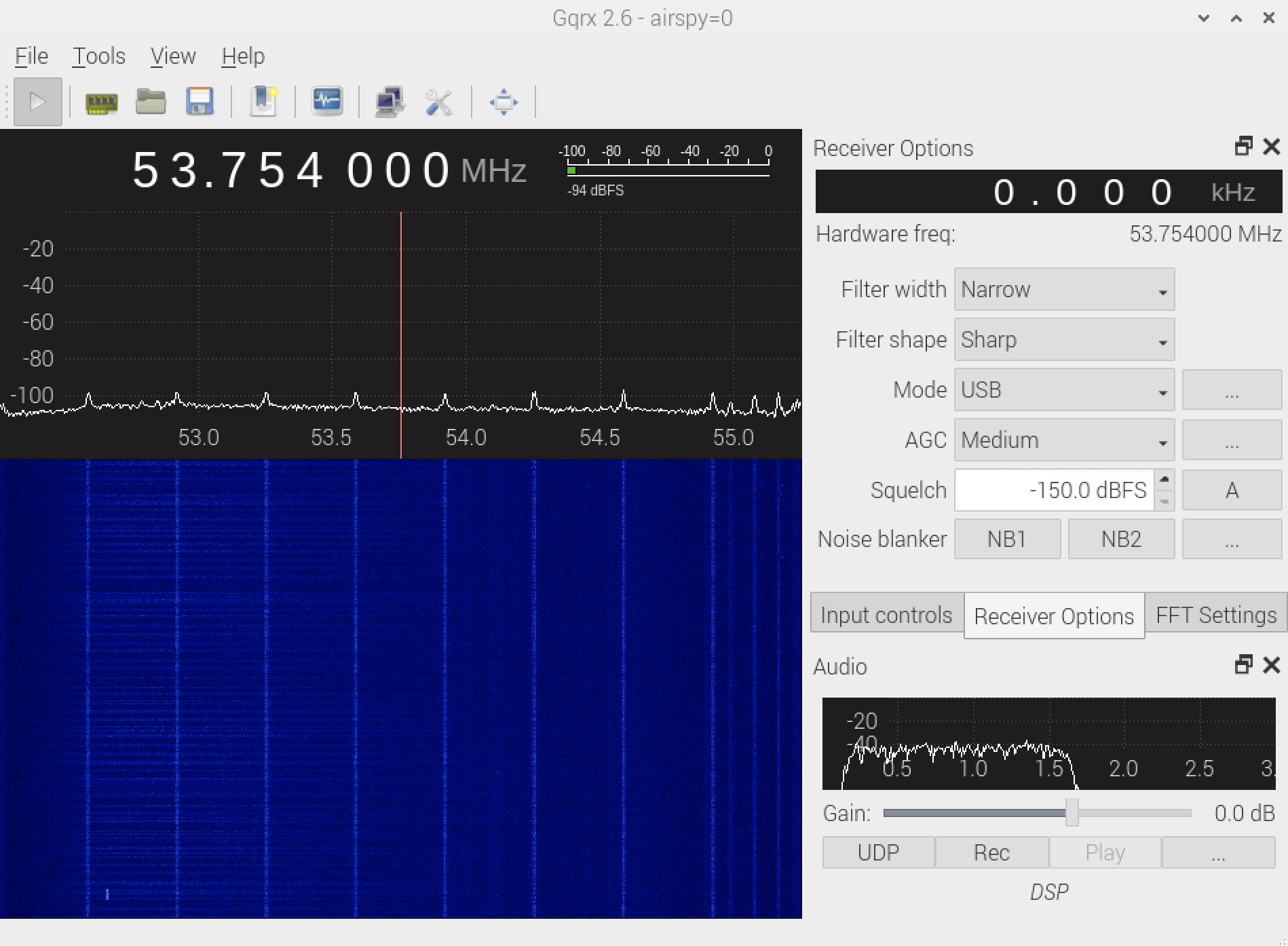
右側の設定画面からReceiverOptionsを開き、
・Filter widthをNarrow
・Filter shapeをSharp
・ModeをUSB
にします。
ModeはUSB変調方式のことを指していて、受信で設定した周波数よりも低い周波数成分をカットして変調します。
次に左上の周波数の指定ですが、音を出すためには受信周波数を送信周波数から少しずらして合わせる必要があります。
送信側周波数の53.755MHzよりも1000Hz低い53.754MHz周波数で合わせると
1000Hzの音が出るようになります。
【 送信周波数-受信周波数=音の周波数 】
流星エコーを解析する
SDRが正しく動作すれば、流星が流れた時にはフォーン♪と1000Hzくらいの高い音が出るようになります。電波の反射が長い時には30秒以上音がなり続けたりします。
↓こんな感じ。音量注意!
https://soundcloud.com/user-395229817/20191218-175747a
この音をPythonで解析していきます。
# -*- coding: utf-8 -*-
from subprocess import getoutput
import argparse
from scipy.fftpack import fft
import numpy as np
import itertools
import matplotlib
matplotlib.use("TkAgg")
import matplotlib.pyplot as plt
import pyaudio
import wave
from datetime import datetime, timedelta
# 解析する周波数(Hz)
FREQ_LOW = 800
FREQ_HIGH = 1200
# ボリュームの最大値
VOL_LIMIT = 2800
# 検知 閾値 0~255
THRESHOLD = 70
# 検知時の録音時間(s)
RECORD_SECONDS = 30
# 録音データ保存先
SAVE_PATH = '/PATHtoSAVE/'
def str2bool(v):
if v.lower() in ('true', 't', 'y', '1'):
return True
elif v.lower() in ('false', 'f', 'n', '0'):
return False
else:
raise argparse.ArgumentTypeError('Boolean value expected.')
# グラフ出すか否か
dataplot = False
parser = argparse.ArgumentParser(description="data plot enable")
parser.add_argument("-p",
metavar="--p",
type=str2bool,
nargs="+",
help="data plot enable"
)
# 流星検知時にMP3保存するか否か
datasave = False
parser.add_argument("-s",
metavar="--s",
type=str2bool,
nargs="+",
help="MP3 Save"
)
args = parser.parse_args()
dataplot = bool(args.p[0])
datasave = bool(args.s[0])
print("data plot enable : " + str(dataplot))
print("MP3 Save : " + str(datasave))
class SpectrumAnalyzer:
FORMAT = pyaudio.paInt16
CHANNELS = 1
RATE = 44100
CHUNK = 22050
N = 22050
# 検知 フラグ
detect = False
# 録音 フラグ
isRecording = False
data = []
frames = []
y = []
maxVol = 0
startTime = datetime.now()
endTime = startTime + timedelta(seconds=RECORD_SECONDS)
filename = startTime.strftime("%Y%m%d_%H%M%S")
def __init__(self):
self.audio = pyaudio.PyAudio()
DEVICE_IDX = 0
for i in range(self.audio.get_device_count()):
dev = self.audio.get_device_info_by_index(i)
if dev['name'].find('USB PnP Sound Device') != -1:
DEVICE_IDX = i
self.stream = self.audio.open(
format = self.FORMAT,
channels = self.CHANNELS,
rate = self.RATE,
input_device_index = DEVICE_IDX,
input = True,
output = False,
frames_per_buffer = self.CHUNK,
stream_callback = self.callback)
self.stream.start_stream()
print('SpectrumAnalyzer init')
def close(self):
self.stream.stop_stream()
self.stream.close()
self.audio.terminate()
print("Quitting...")
def callback(self, in_data, frame_count, time_info, status):
yf = fft(np.frombuffer(in_data, dtype=np.int16)) / self.CHUNK
self.y = np.abs(yf)[1:int(self.CHUNK/2)]
freqRange = self.RATE / self.N
lowIdx = int(FREQ_LOW / freqRange)
highIdx = int(FREQ_HIGH / freqRange)
vol = self.y[lowIdx:highIdx]
self.maxVol = 0
idx = 0
for v in vol:
# ホワイトノイズが5~10%の25以下になるように調整
vol[idx] = v.round()
# VOL_LIMITで切っちゃう
if VOL_LIMIT <= vol[idx]:
vol[idx] = VOL_LIMIT
# 255で正規化
vol[idx] = int(round(vol[idx] / VOL_LIMIT * 255, 0))
# 最大値
if (self.maxVol <= vol[idx]):
self.maxVol = vol[idx]
if (vol[idx] > 255):
vol[idx] = 255
idx = idx + 1
if(dataplot):
self.data = vol.tolist()
self.drawGraph()
# しきい値の比較
if THRESHOLD <= self.maxVol:
self.detect = True
else:
self.detect = False
# 録音開始
if self.isRecording == False and self.detect:
self.isRecording = True
self.startRecording()
# 録音中処理
if self.isRecording:
self.frames.append(in_data)
# 録音終了時処理
if datetime.now() > self.endTime:
self.isRecording = False
self.stopRecording()
return(None, pyaudio.paContinue)
def drawGraph(self):
plt.subplot(1,1,1)
plt.clf()
plt.plot(self.data)
plt.draw()
plt.pause(0.05)
def startRecording(self):
self.startTime = datetime.now()
self.endTime = self.startTime + timedelta(seconds=RECORD_SECONDS)
self.filename = self.startTime.strftime("%Y%m%d_%H%M%S")
print(self.startTime.strftime("%Y%m%d_%H%M%S") + " Recording Start")
def stopRecording(self):
waveFile = wave.open(SAVE_PATH + self.filename + '.wav', 'wb')
waveFile.setnchannels(self.CHANNELS)
waveFile.setsampwidth(self.audio.get_sample_size(self.FORMAT))
waveFile.setframerate(self.RATE)
waveFile.writeframes(b''.join(self.frames))
waveFile.close()
self.frames = []
print("Recording Stop")
# MP3変換
self.convertMp3()
def convertMp3(self):
checkConvert = getoutput("lame -b 128 " + SAVE_PATH + self.filename + '.wav' + " " + SAVE_PATH + self.filename + '.mp3')
print(checkConvert)
# WAV 削除
srcDel = getoutput("rm -rf " + SAVE_PATH + self.filename + '.wav')
print(srcDel)
def keyInterrupt():
while True:
try:
pass
except KeyboardInterrupt:
spec.close()
return
spec = None
if __name__ == "__main__":
spec = SpectrumAnalyzer()
keyInterrupt()
処理の流れとしては
1. 0.5秒毎にFFT
2. 800~1200Hzのデータを抜き出す
3. 上記範囲のボリュームが閾値を超えたか判定
4. 超えていたら30秒間wavとして保存する
5. wavからmp3に変換
という感じで、流れ星が流れるたびにmp3ファイルが出来上がっていきます。
閾値の調整
流星検知の閾値を調整するためにスペクトログラムを表示します。
# スペクトログラムの描画
# p → True
python3 /home/pi/streamfft.py -p True -s False
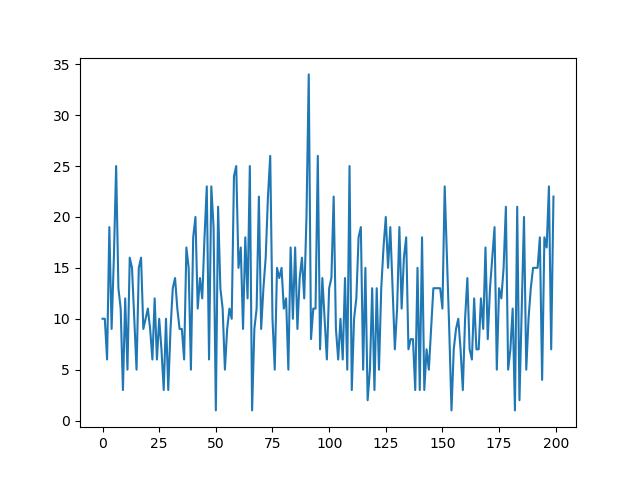
0.5秒毎にFFTしているので、周波数分解能は2Hz。
800~1200Hzの400Hz分の解析をしているため、一回のFFTで得られるデータは200点。
ラベルをつけてないのが不親切で申し訳ないですが、X軸は左端800Hz、右端1200Hzということになります。
Y軸は0~255で正規化された値です。
上図はホワイトノイズのみが入っている状態で、ノイズフロアが255中の10くらいの大きさになるようにボリュームVOL_LIMITを調整しています。
この調整を行ったのちに、検知閾値を超えたら流星だ!というざっくり判定です。
↓流星の電波が入ってくると下図のようにスパイクします。
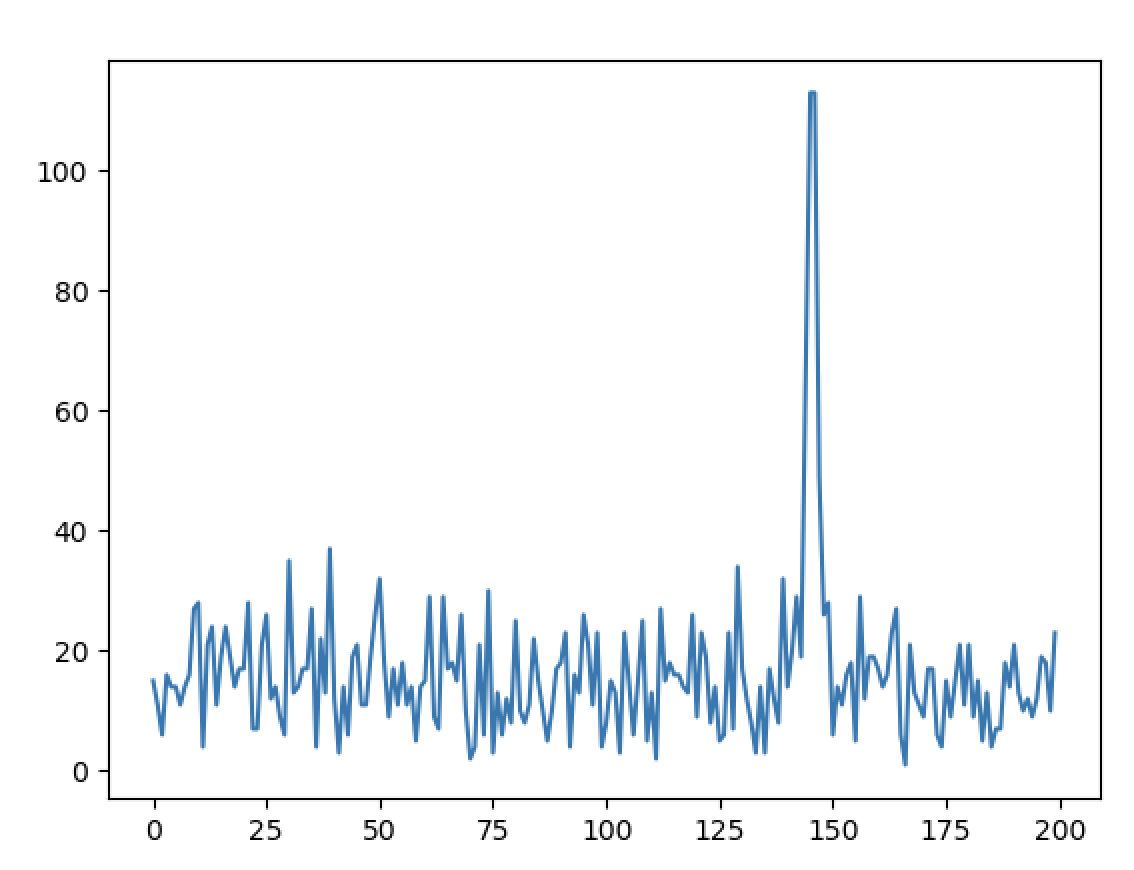
いざ、観測へ!
# 観測コマンド
# s → Trueにしてデータを保存する
python3 /home/pi/streamfft.py -p False -s True
2019年 ふたご座流星群の観測結果

12/14深夜2時から観測をはじめて、12/16の10時に観測終了したので56時間くらい。
そのうち12時間くらいは福井のビーコン波が止まってたらしく、その間はデータ取れず。
データとしては400個くらいあり、明らかに別のノイズっぽいものが重なったり流星エコーじゃないものを弾いて、所感としては200個くらいでした。
SDRのAGCの具合と決め打ちの閾値判定があまりうまく噛み合わなかったのか、データ欠損時間があったりして良い感じには取れませんでした。
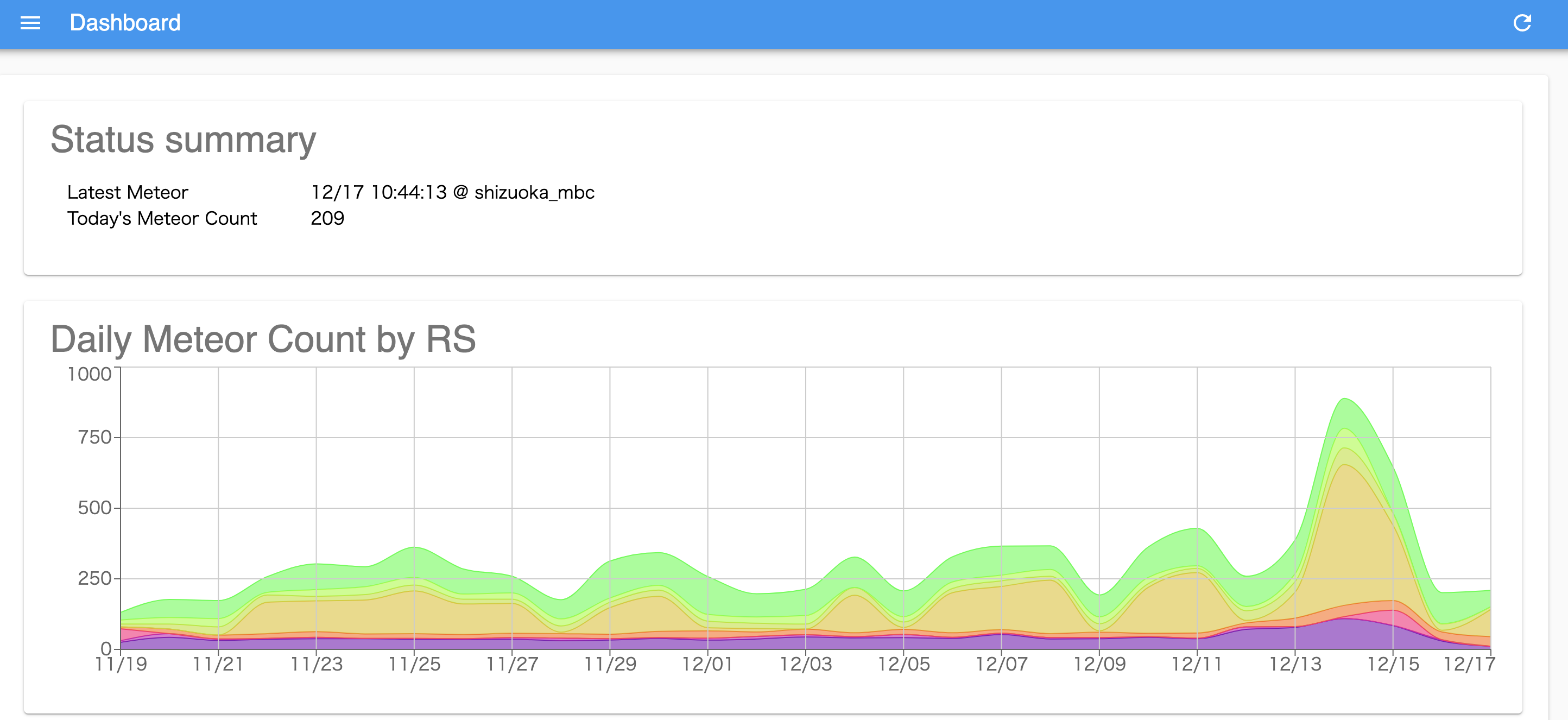
これは一昨年くらいに日本各地に設置した流れ星観測局のデータ。
ラズパイでFFTした値をAWSに送ってサーバーの方でリアルタイムに流星エコー検出しています。
本来であればこのように、12/12くらいから徐々に流星数が伸びていき、12/14-15のピークを境にガツンと下がるのが、ふたご座流星群の特徴。
まとめ
RaspberryPi4で大幅にパフォーマンスが上がり、SDRしながらエコー解析することができるようになりました。
RaspberryPi3だとSDRでいっぱいいっぱい・・・。
また、今回は閾値を超えたかどうかの単純な判定で紹介しましたが、実際に観測するといろいろノイズが入ってくるので、それをはじく高度な判定処理をいれるとさらに面白いか思います。
ex.飛行機で反射してきたエコーはドップラーがかかる。周波数変位で判定してはじく。とかとか