Pandasについて
今回もNumpy同様にPythonのライブラリであるPandasについてまとめましたので、
私個人のアウトプットと共に皆さん参考に少しでもなれば幸いでございます。
要点だけまとめておりますのでよろしくお願いします。
Pandasとは
まずPandasの定義として、
「データ分析を容易にする機能を提供するPythonのデータ解析ライブラリ」
となります。
Pandasの特徴としては、データフレーム(Data Frame)などの独自のデータ構造が提供されており、様々な処理が可能です。
特に表形式のSQLまたはRのように操作することが可能であり、かつ高速で処理することが可能です。
Pandasでできること
- CSVやExcel、RDBなどにデータを入出力できる。
- スクレイピングからのデータ抽出も可能。
- データ前処理(NaN / Not a Number、欠損値)。
- データの結合や部分的な取り出しやピボッド(pivot)処理。
- データの集約及びグループ演算。
- データに対しての統計処理及び回帰処。
Pandasインストール
$ pip install pandas
import
上記でインストールしていなければimport errorが出るので注意してください。
一般的にpdに省略しますがどちらでも問題ないですが、
省略した方が後々書きやすいので省略すると思っていただいて問題ないです。
$ import pandas as pd
Series型
シリーズ型では1次元のベクトルを扱います。
$ sr = pd.Series([1, 2, 3])
# 0 1
# 1 2
# 2 3
# 3 4
# 4 5
取得する範囲の指定(Series型)
loc['カラム名':'カラム名']を使うことで取得する範囲の指定が可能です。
今回はカラム名を特に指定していないので、数値になっています。
$ sr.loc[0:2]
# 0 1
# 1 2
# 2 3
index番号で指定するときはiloc[index番号]で取得します。
$ sr.iloc[3:]
# 3 4
# 4 5
# 1つだけ取得したい時
# 今回は3を取得したいとする
$ sr.iloc[2]
# 3
DataFrame型
次にデータフレーム型です。
今後よく出てくる型になると思うので、理解していただければと思います。
$ df = pd.DataFrame([[1, 2, 3], [4, 5, 6], [7, 8, 9], [10, 11, 12], [13, 14, 15], [16, 17, 18]])

上記のようにExcelのような形で表示できれば問題ないです。
CSVやExcelなどの読み込み
今回は実装していませんがそのコードのみ記載しておきます。
# csvの読み込み可能
# 同じディレクトリ内似なければエラーが発生
$ pd.read.csv('')
# スクレイピング
$ pd.read.html('')
# excelも可能
$ pd.read.Excel('')
head()とtail()と部分抽出
head()では先頭の5行の取得が可能です。
$ df.head()
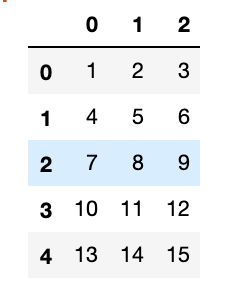
tail()では末尾の5行の取得が可能です。
$ df.tail()

部分抽出することも可能。
今回は0,1のカラムを取り出したいとする。
$ df[[0, 1]]

余談ですが部分抽出時にhead()とtail()の使用も可能です。
$ df[[0, 1]].head()
# 部分抽出と先頭5行取得
$ df[[0, 1]].tail()
# 部分抽出と末尾5行取得
取得する範囲の指定(DataFrame型)
Series型同様にDataFrameにもlocとilocは使用可能です。
dfのデータ内で3行目(3*3)まで取得したいとします。
$ df.loc[0:2]
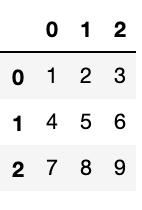
今度は行列で指定した範囲のみ取得したいとします。
その時にiloc[:, 'カラム名':'カラム名']とします。
先程も記述したように今回はカラム名の設定は指定はしていません。
# df.iloc[行, 列]を表示する
# [:]は全てを意味する
$ df.iloc[:, 0:2]

条件抽出と条件分岐
pandasではnumpyのように条件抽出が可能で、
条件を満たしている時はTrue、
条件を満たしていない時はFalseが出力されます。
# 条件抽出
# 条件に満たしている値はTrue
# 条件を満たしていない値はFalse
$ df[2] > 7
# 0 False
# 1 False
# 2 True
# 3 True
# 4 True
# 5 True
$ df[:] > 7
# 全体の条件抽出を行うことができる
条件分岐では条件を満たしているもののみ取得する仕組みです。
# 条件分岐
# 条件に合った値だけ抽出している
$ df[df[2] > 9]
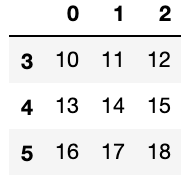
昇順・降順
pandasではsort_valuesを使うことで昇順・降順に並べ替えることが可能です。
$ df.sort_values(by=0)
numpy同様の機能
# shapeで行列の確認が可能。
$ df.shape
# (6, 3)
# meanで各列ごとの平均を確認することが可能
$ df.mean
# 0 8.5
# 1 9.5
# 2 10.5
# stdで各列ごとの標準偏差を確認することが可能
$ df.std()
# 0 5.612486
# 1 5.612486
# 2 5.612486
describeを使うと平均や標準偏差、最大値や最小値など様々な値を一度に確認することが可能
$ df.describe()
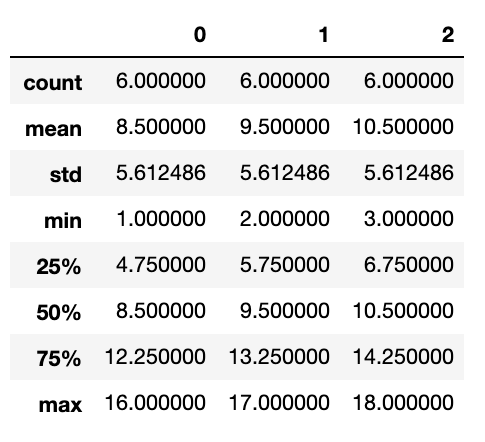
Numpy型に変換
$ df.values
# array([[ 1, 2, 3],
# [ 4, 5, 6],
# [ 7, 8, 9],
# [10, 11, 12],
# [13, 14, 15],
# [16, 17, 18]])
# データ数と型の確認
$ df.info
# 0 1 2 3
# 1 4 5 6
# 2 7 8 9
# 3 10 11 12
# 4 13 14 15
# 5 16 17 18
# ユニークな値の数を確認
# 被ってない値がないか確認
# 下記では6種類の値があるとかくにんできる
$ df.nunique()
# 0 6
# 1 6
# 2 6
# 欠損値の確認
# Falseなら欠損値がない状態
# NanもしくはTrueの表示は欠損値がある
$ df.isnull()
欠損値の確認

データの追加・削除と四則演算
Pandasでは先程作成したdfにカラム名と共に追加することが可能です。
また追加する値を四則演算を利用して値を決めることも可能です。
# データの追加
# 同時に四則演算も可能
# 今回はわかりやすくカラム名を'new_column'にします
# 'new_column'の値はdf[1]とdf[2]を足し算します
$ df['new_column'] = df[1] + df[2]
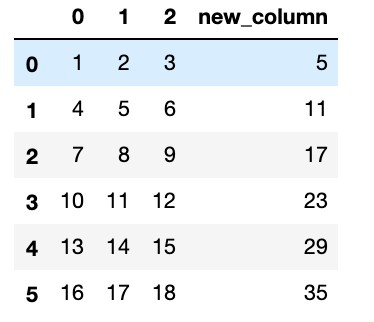
次は引き算します。
$ df['new_column'] = df[1] - df[2]
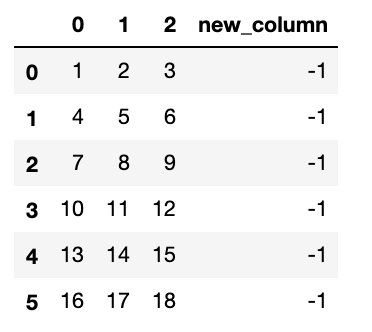
次は行列積します。
$ df['new_column'] = df[1] @ df[2]
# もしくは
$ df['new_column'] = df[1].dot(df[2])
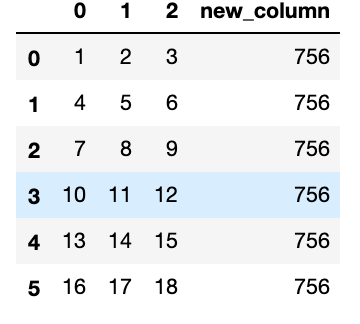
次にスカラー計算します。
$ df['new_column'] = df[1] * df[2]
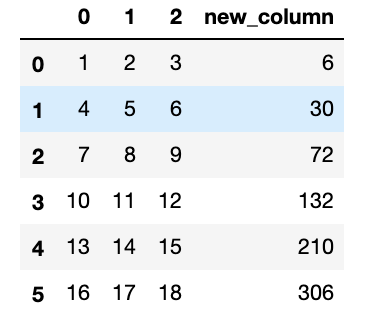
最後に[2]のカラムを削除します。
# columns=['カラム名']
$ df.drop(columns=[2])
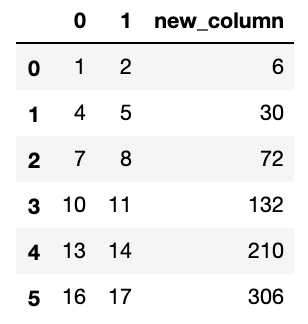
カテゴリカルデータの操作
Pandasではdict型での作成も可能です。
# {key('カラム名') : value}
$ df_1 = pd.DataFrame({'C1' : ['A', 'S', 'D', 'F', 'G', 'H', 'J'],
'C2' : [1, 2, 3, 4, 5, 6, 7],
'C3' : [100, 200, 300, 400, 500, 600, 700]})
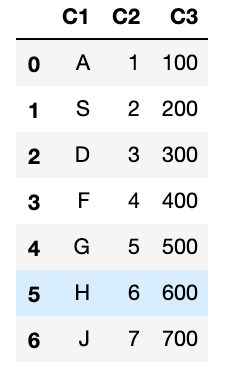
カテゴリとデータの確認
$ df_1.value_counts()
# C1 C2 C3
# A 1 100 1
# D 3 300 1
# F 4 400 1
# G 5 500 1
# H 6 600 1
# J 7 700 1
# S 2 200 1
# 勿論カラム指定しての確認も可能
df_1['C1'].value_counts()
# A 1
# F 1
# G 1
# S 1
# H 1
# D 1
# J 1
特定のカテゴリのデータを取り出す
$ df_1[df_1['C1'] == 'D']
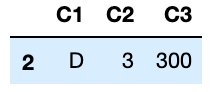
欠損値の確認も可能です。
# 全体の確認
# 今回は無い
$ df_1.fillna(df_1.mode)
# 一部を確認したい時
# 確認したい列の['カラム名']と[index番号]を追加するのみ
$ df_1['C1'].fillna(df_1['C1'].mode([0]))
全体のみ載せておきます。
一部の確認をしたい方は実際にやってみてください。
割合を計算する
$ round(df_1.value_counts()/len(df_1))
# C1 C2 C3
# A 1 100 0.0
# D 3 300 0.0
# F 4 400 0.0
# G 5 500 0.0
# H 6 600 0.0
# J 7 700 0.0
# S 2 200 0.0
グループ化して各種統計量を計算する
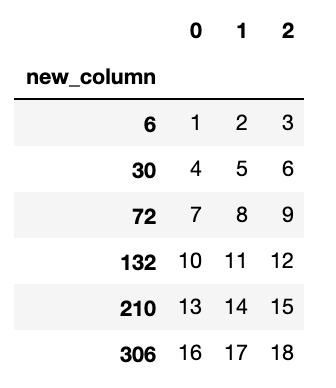
$ df.groupby('new_column').sum()
データの結合
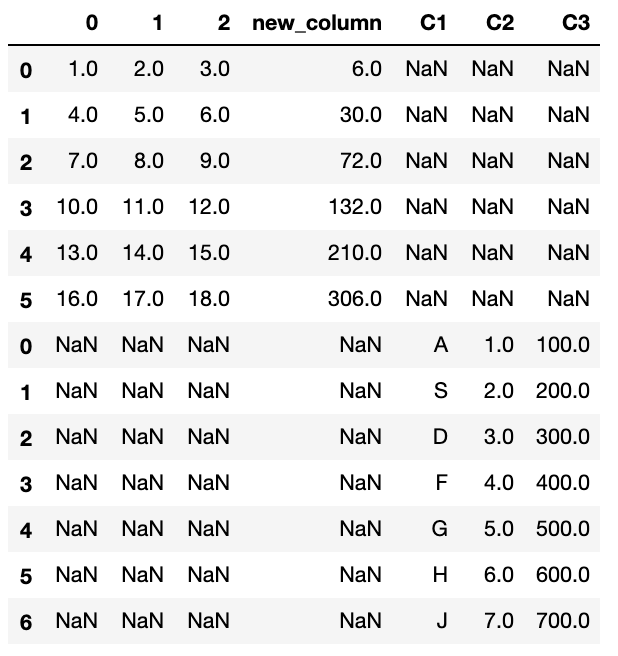
先程作成したdfとdf_1を結合したいと思います。
少し汚くなると思うので、皆さんは綺麗に作成することおすすめします。
$ data = pd.concat([df, df_1])
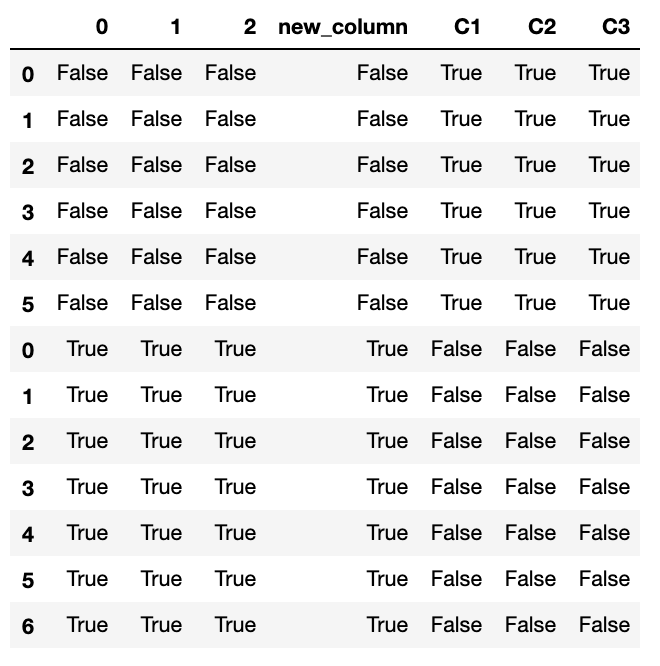
ちなみに欠損値を確認してみると、
$ data.isnull()
関数の定義と適用
まず簡単に関数を定義します。
$ def add(x, y):
return x + y
# 定義した関数の引数に計算したい行列(index番号)を設定
add(data[1], data['new_column'])
# 0 8.0
# 1 35.0
# 2 80.0
# 3 143.0
# 4 224.0
# 5 323.0
# 0 NaN
# 1 NaN
# 2 NaN
# 3 NaN
# 4 NaN
# 5 NaN
一部欠損値が出ているので綺麗に整理して実行してみてください。
関数定義時に戻り値が複数ある場合
最後に戻り値が複数ある場合に行列を追加することも可能です。
$ def square_and_cube(x):
return pd.Series([x**2, x**3])
data[['new', 'column']] = data[1].apply(square_and_cube)
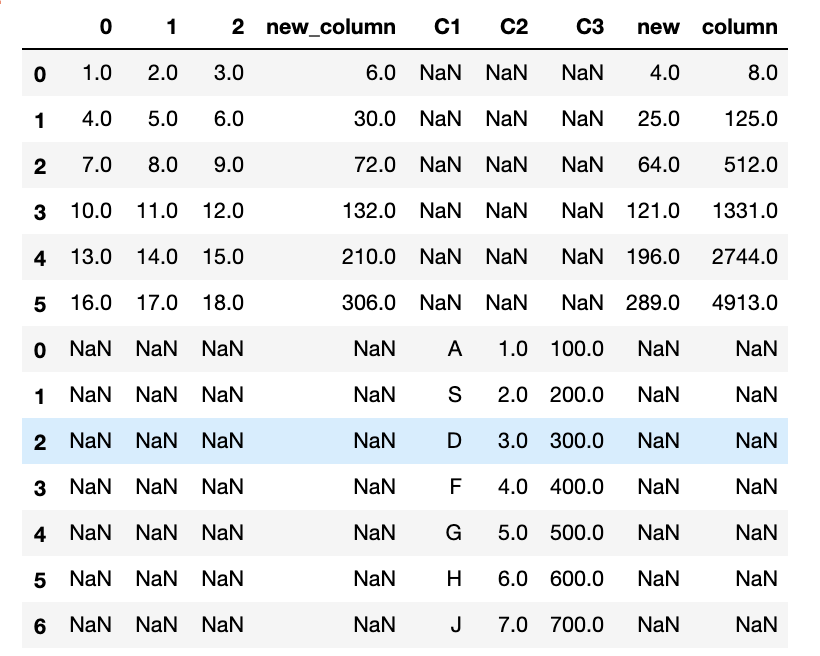
はい!新しくカラムが追加されたと思います!
'new'のカラムにはdata[1]の値にxを2乗した値が出力されており、
'column'のカラムにはdata[1]の値にxに3乗した値が出力されていることが確認できます。
何度もいいますが今回作成したのは少し汚いので綺麗に作成していただければいいと思います。
最後に
今回はPandasについてまとめてみました。
今後も今回のようなまとめを登場していきたいと思います。
次回はmatplotlibについてまとめていきます。