はじめに
Amazon Bedrock(以下Bedrock)使って画像生成するアプリを作ろうとしてます。(画像生成AI好きなので趣味として)
以前「Stable Diffusion XL 1.0のAPIを叩く->作成された画像をS3に格納する」部分をAWS Lambda(以下Lambda)で作ったので、今回は与えたキーワードをもとにプロンプトを生成する部分のコードを書きたいと思います。
前回の記事はこちら
Amazon Bedrockで画像生成&S3保存するPythonコードを書く
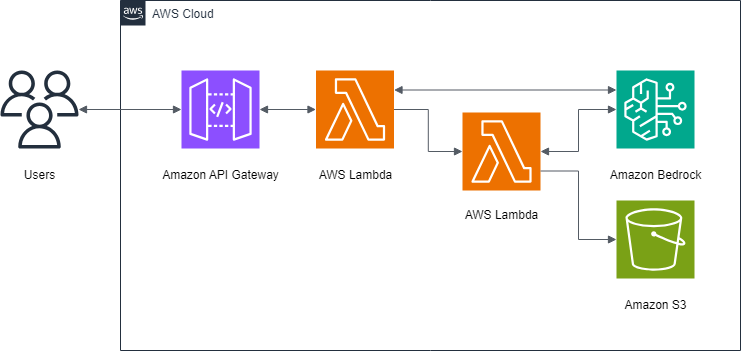
1. 構成
今回はキーワードからTitan Text G1 - Expressに画像生成用のプロンプトを作ってもらいます。返却されたプロンプトを引数に、Stable Diffusion XL 1.0のAPIを叩くLambdaを呼び出します。
今Amazon API Gateway - Lambda間の連携はしていませんが、イメージとしてはこんな感じです。
2. 画像生成のプロンプトを作ってもらうプロンプト
AWSのマネジメントコンソールのPlaygroundで、画像生成のプロンプトを作ってもらうプロンプトを試してみました。
Temperatureは回答のランダム性を調整します。
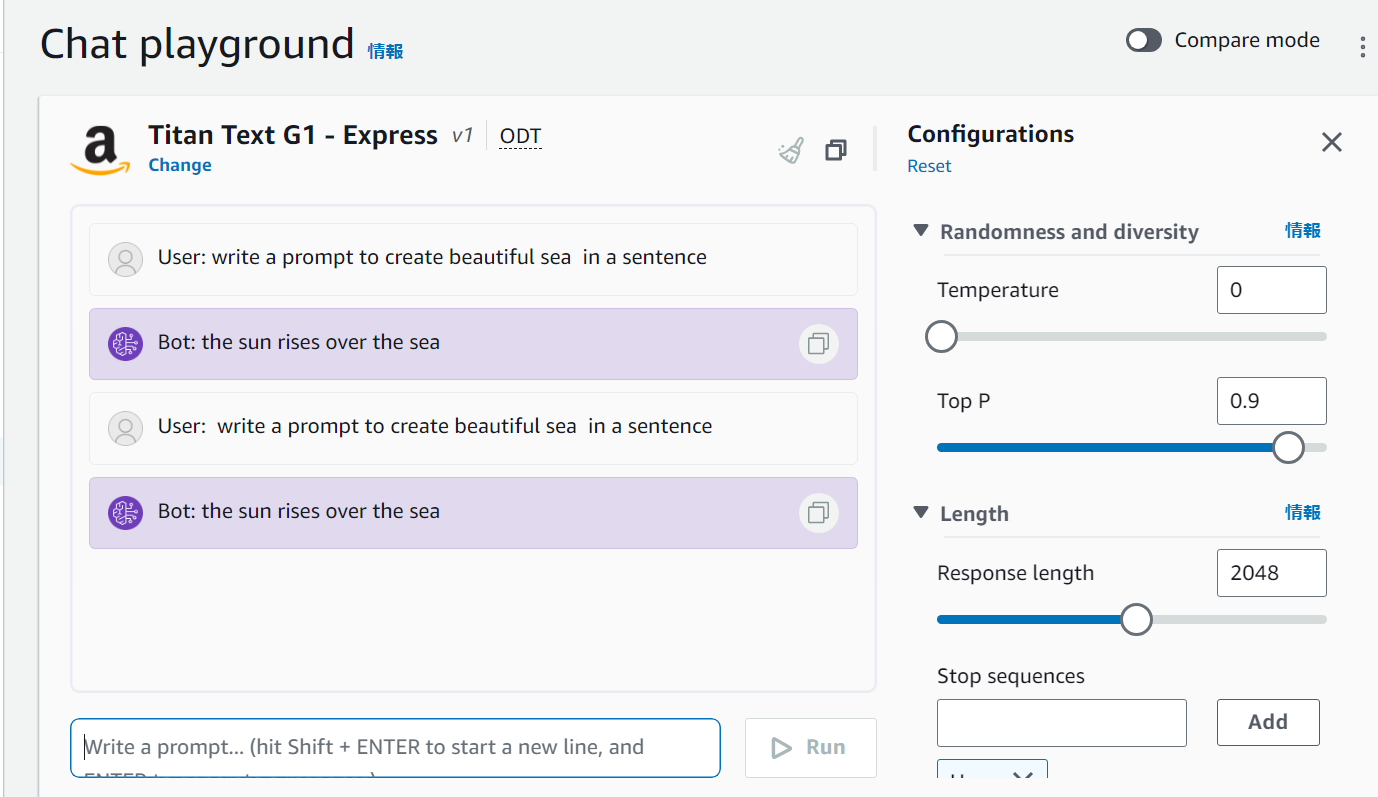
色々なプロンプト試してみたいので、コードではTemperatureをMaxの1に設定してみます。
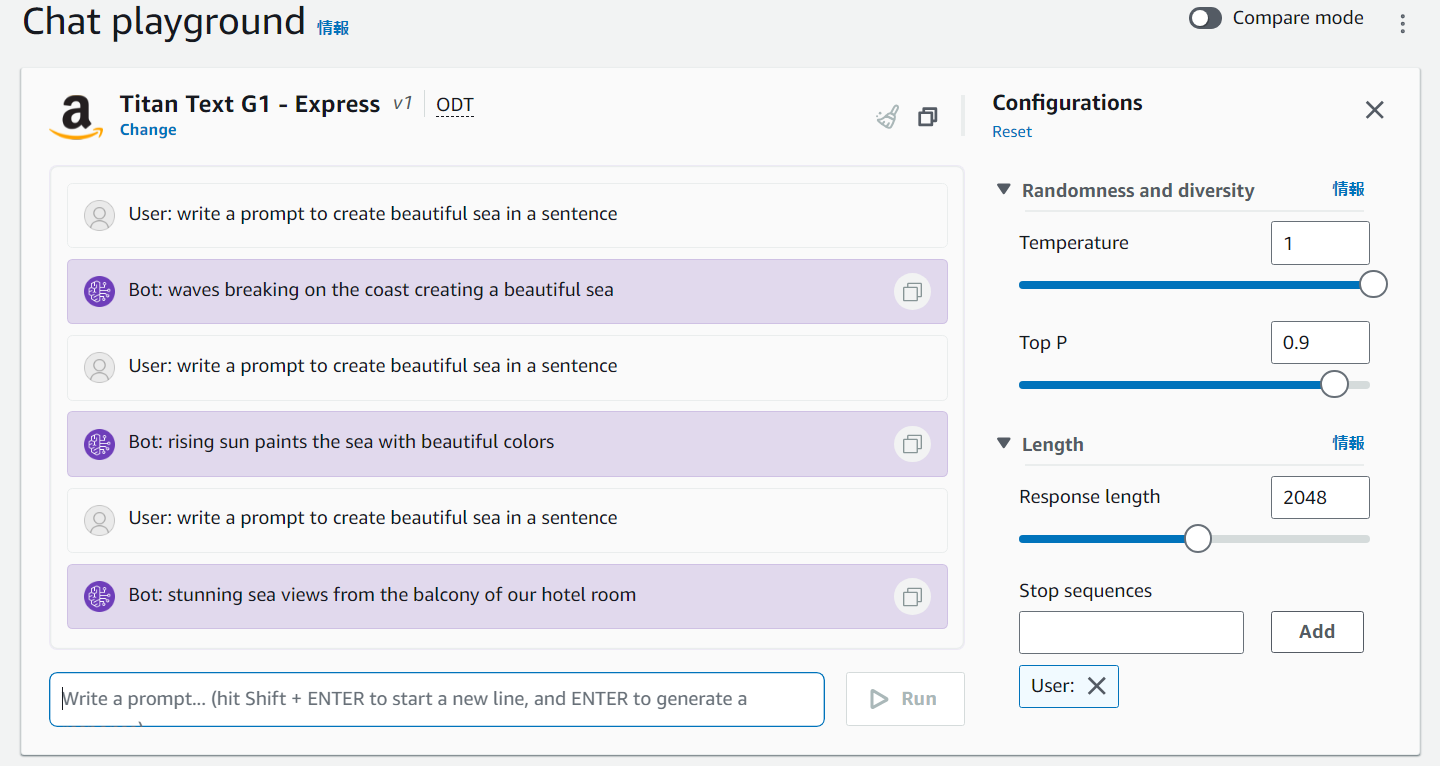
Top Pは可能性の低い回答を無視したいとき -> 低い値を設定するとよいようです。色々試してみましたが、値が大きいと思ってたのと違う画像が出てくることが多かったのでコードでは0にしています。
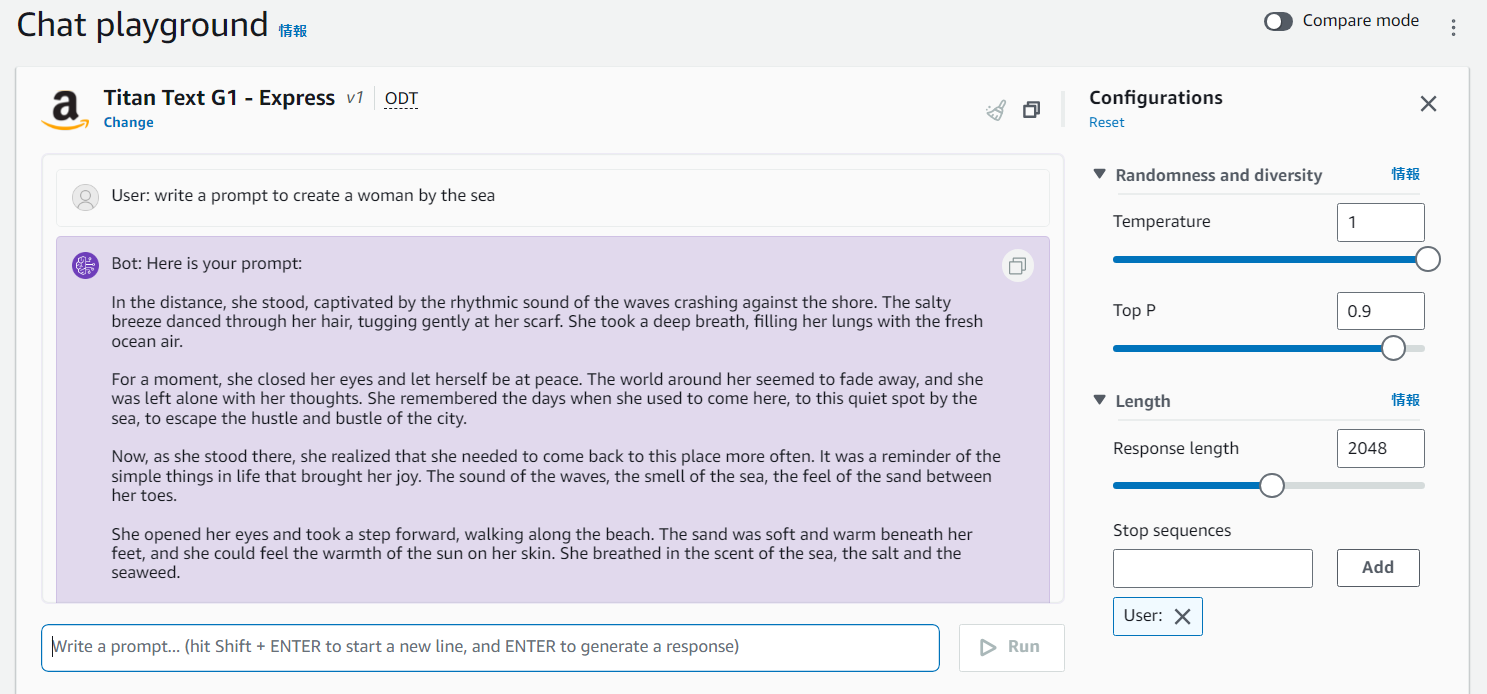
また、入れるキーワードによっては穴埋め形式だったり物語形式だったりで長々と返してくるので、1行で返して(in a sentence)もつけることにします。
"in a sentence"をつけなかった場合(Response lengthの値を初期値の2048のままにしてたのもあるけど、長い……)
3. コード
引数keywordに生成したい画像のざっくりとしたキーワードを入れて実行します。
import boto3
import json
def lambda_handler(event, context):
bedrock_runtime = boto3.client(service_name="bedrock-runtime")
keyword = event['keyword']
prompt = "write a prompt to create" + keyword + "in a sentence"
body = json.dumps({
"inputText": prompt,
"textGenerationConfig":{
"temperature": 1,
"topP": 0.1,
"maxTokenCount": 100,
"stopSequences": []
}
})
#Titan Text G1 - Expressを呼び出し
response = bedrock_runtime.invoke_model(
body=body,
modelId="amazon.titan-text-express-v1",
accept="application/json",
contentType="application/json"
)
#レスポンスを整形
response_body = json.loads(response.get('body').read())
outputText = response_body.get('results')[0].get('outputText')
text = outputText[outputText.index('\n')+1:]
image_prompt = text.strip('.')
#画像生成のLambdaに渡す引数
input_event = {
"input": image_prompt
}
payload = json.dumps(input_event)
#画像生成のLambdaをキック
response = boto3.client('lambda').invoke(
#<function_name>には画像生成のLambda名を入れる
FunctionName = '<function_name>',
InvocationType='RequestResponse',
Payload = payload
)
参考サイト
LambdaからLambdaを呼び出す方法
Amazon Titanのパラメータについて
Amazon Titanのレスポンスの整形の部分を参考にさせていただきました。
コードでは消していますが、printで整形中のレスポンスをログに吐いてみました。
outputTextは最初と最後に\nが入ってるので本文だけ抽出します。
画像生成のプロンプトを生成された画像のファイル名にしているのでピリオドも消してます。(ピリオド残しておくと画像のファイル名が"hoge..png"になってちょっと気持ち悪い)

3. 動かしてみる
"beautiful sea"をkeywordに入れて実行してみましょう。
返ってきたプロンプトを引数に画像生成のLambdaをキックしてくれます。
こんな感じで引数が渡ってます。
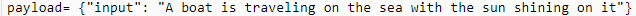
画像ができました

こんな感じ。きれい。

ちなみにkeywordによっては回答に余計な文がくっついてきます。
keywordに"in"を含めると起こりやすい気がします。(in a sentenceのところ上手く汲んでくれなくなるのかな…)
keywordにfortess in the skyを入れて実行するとこんな感じ。(Here is a prompt to~が邪魔)

ただ"Here is a prompt to~"がくっついてても画像はいい感じに生成されます。

keywordにsky fortessを入れて実行してみます。"Here is a prompt to~"はついてません。

これもいい感じに画像が生成されました。

おわりに
とりあえず動くようになったレベルですが、プロンプトを作って画像生成するコードはできました。
今はLambdaのテストから実行しているので、Amplifyでホストしたアプリからコードを実行できるようにしたりとか、プロンプトや画像の精度を高めるためのチューニングとか、エラー処理だとかアプリとしての体裁を整えていきたいです。