Level7.深層学習 DAY3
7-1.深層学習全体像の復習
●AlexNet
☆確認テスト☆
・7-1-1 サイズ5×5の入力画像を、サイズ3×3のフィルタで
畳み込んだ時の出力画像のサイズを答えよ。
なおストライドは2、パディングは1とする。
【自分の回答】
3×3の出力画像
OH = (5+21-3)/2+1 = 3
OW = (5+21-3)/2+1 = 3
【解答】
3×3の出力画像
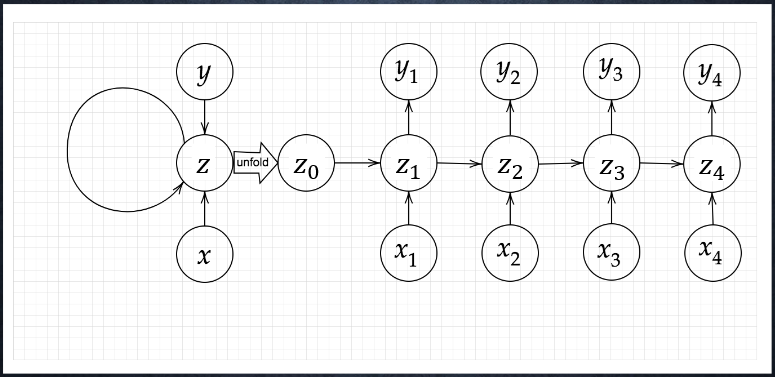
7-2 Section1 再帰型ニューラルネットワークの概念
7-2-1 RNN全体像
●RNNとは
時系列データに対応可能な、ニューラルネットワークである。

●時系列データとは
時間的順序を追って、一定間隔ごとに観察され、
しかも、相互に統計的依存関係が認められるようなデータの系列
・音声データ
・テキストデータ(月ごとの来場者数等) 等
●RNNについて
ポイントは中間層(隠れ層)が非常に重要である。
【RNN】
\begin{align}
&u^t = W_{(in)}x^t + Wz^{t-1} + b\\
&z^t = f(W_{(in)}x^t + Wz^{t-1} + b)\\
&v^t = W_{(out)}z^t + c\\
&y^t = g(W_{(out)}z^t + c)
\end{align}
・u[:,t+1] = np.dot(X, W_in) + np.dot(z[:,t].reshape(1, -1), W)
・z[:,t+1] = functions.sigmoid(u[:,t+1])
・np.dot(z[:,t+1].reshape(1, -1), W_out)
・y[:,t] = functions.sigmoid(np.dot(z[:,t+1].reshape(1, -1), W_out))
☆確認テスト☆
・7-2-1-1 RNNのネットワークには大きくわけて3つの重みがある。
1つは入力から現在の中間層を定義する際にかけられる重み、
1つは中間層から出力を定義する際にかけられる重みである。
残り1つの重みについて説明せよ。
【自分の回答】
中間層から中間層への重み。
【解答】
中間層から中間層への重み。(W)
入力層から中間層への重み(W(in))
中間層からの出力層への重み(W(out))
●RNNの特徴とは
時系列モデルを扱うには、初期の状態と過去の
時間t-1の状態を保持し、そこから次の時間でのtを
再帰的に求める再帰構造が必要になる。
●ソース演習
バイナリ加算(2進数の値を予測する)




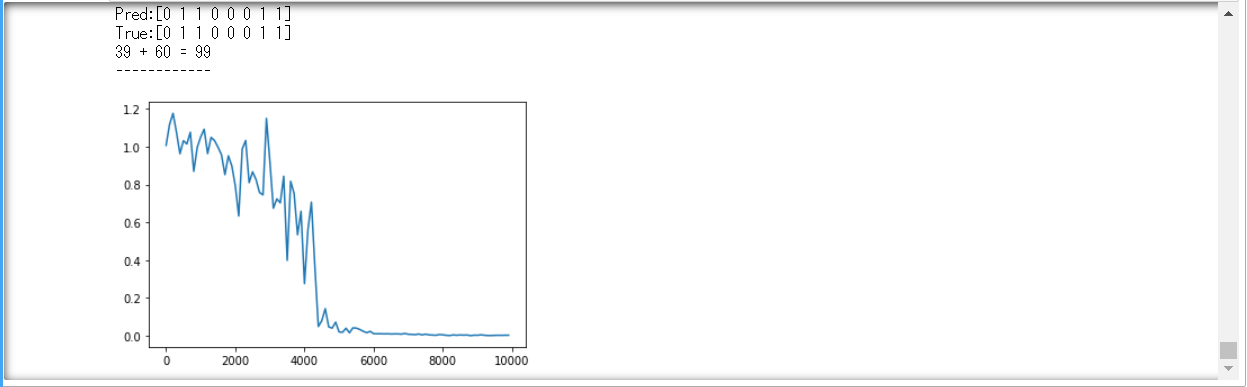
①weight_init_stdやlearning_rate, hidden_layer_sizeを変更してみよう

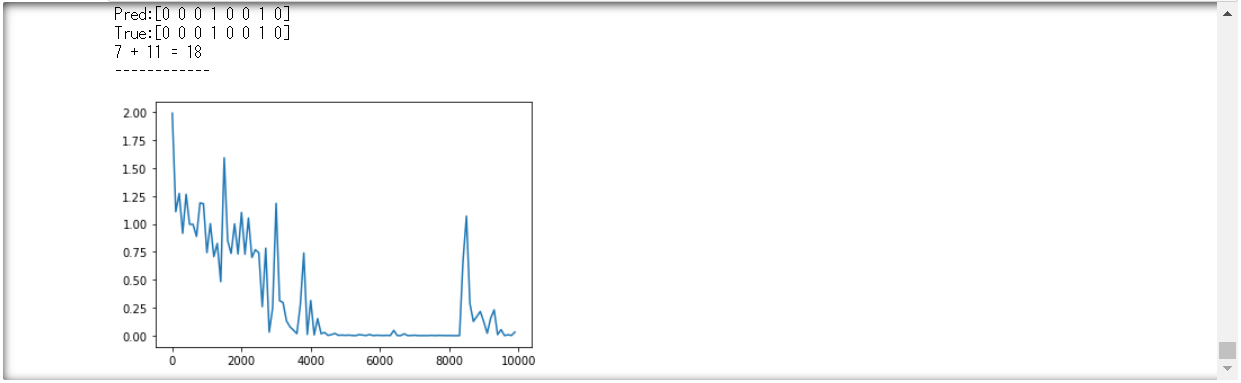
②重みの初期化方法を変更してみよう
・Xavier
処理が早いと感じる。

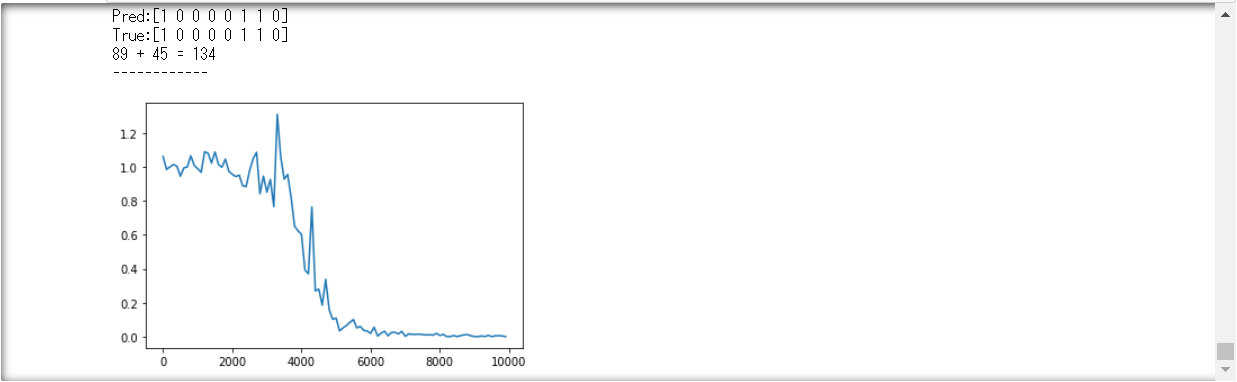
・He
コーディングミスしてた。。。
動くようになって良かった。(汗)


③中間層の活性化関数を変更してみよう
直ぐにわからなかったので、答えを参照した。
・ReLU


・ハイパーボリックタンジェント


7-2-2 BPTT
●BPTTとは
RNNにおいてのパラメータ調整方法の一種
⇒逆誤差伝播の一種
●誤差逆伝播法の復習
・他人に誤差逆伝播法を説明してみよう。

☆確認テスト☆
・7-2-2-1 連鎖律の原理を使い、dz/dxを求めよ。
$z=t^2$
$t=x+y$
【自分の回答】
\begin{align}
\frac{dz}{dx} &= \frac{dz}{dt}\frac{dt}{dx}\\
&=\frac{d}{dt}t^2・\frac{d}{dx}(x + y)\\
&=2t・1\\
&=2(x + y)
\end{align}
【解答】
自分の回答と同じ
7-2-3 BPTTの数学的記述
【数学的記述1】
\begin{align}
\frac{\partial E}{\partial W_{(in)}} &= \frac{\partial E}{\partial u^t}\left [ \frac{\partial u^t}{\partial W_{(in)}} \right ]^T = δ^t[x^t]^T\\
\frac{\partial E}{\partial W_{(out)}} &= \frac{\partial E}{\partial v^t}\left [ \frac{\partial v^t}{\partial W_{(out)}} \right ]^T = δ^{out,t}[z^t]^T\\
\frac{\partial E}{\partial W} &= \frac{\partial E}{\partial u^t}\left [ \frac{\partial u^t}{\partial W} \right ]^T = δ^t[z^{t-1}]^T\\
\frac{\partial E}{\partial b} &= \frac{\partial E}{\partial u^t}\frac{\partial u^t}{\partial b} = δ^t\\
\frac{\partial E}{\partial c} &= \frac{\partial E}{\partial v^t}\frac{\partial v^t}{\partial c} = δ^{out,t}
\end{align}
・np.dot(X.T, delta[:,t].reshape(1,-1))
・np.dot(z[:,t+1].reshape(-1,1), delta_out[:,t].reshape(-1,1))
・np.dot(z[:,t].reshape(-1,1), delta[:,t].reshape(1,-1))
【数学的記述2】
\begin{align}
u^t &= W_{(in)}x^t + Wz^{t-1} + b\\
z^t &= f(W_{(in)}x^t + Wz^{t-1} + b)\\
v^t &= W_{(out)}z^t + c\\
y^t &= g(W_{(out)}z^t + c)
\end{align}
・u[:,t+1] = np.dot(X, W_in) + np.dot(z[:,t].reshape(1, -1), W)
・z[:,t+1] = functions.sigmoid(u[:,t+1])
・np.dot(z[:,t+1].reshape(1, -1), W_out)
・y[:,t] = functions.sigmoid(np.dot(z[:,t+1].reshape(1, -1), W_out))
☆確認テスト☆
・7-2-3-1 下図の$y_1$を$x・S_0・S_1・W_{in}・W・W_{out}$を用いて数式で表せ。
※バイアスは任意の文字で定義せよ。
※また中間層の出力にシグモイド関数$g(x)$を作用させよ。

【自分の回答】
$S$はどこに・・・。(zと仮定しよう。バイアスはb。)
まず、$y_1 = W_{(out)}(W_{(in)}x_1+Wz_0) + b)$
シグモイド関数を入れると・・・。
$y_1 = g(W_{(out)} (W_{(in)}x_1+Wz_0) + b)) + c$
【解答】
$z_1 = sigmoid(S_0W + x_1W_{(in)} + b)$
$y_1 = sigmoid(z_1W_{(out)} + c)$
●ビジネス事例
鏡にキャラクターがいて、パーツごとの化粧のアドバイスをしてくれる。
【数学的記述3】
\frac{\partial E}{\partial u^t} = \frac{\partial E}{\partial v^t}\frac{\partial v^t}{\partial u^t}=\frac{\partial E}{\partial v^t}\frac{\partial {W_{(out)}f(u^t)+c}}{\partial u^t}= f'(u^t)W^T_{(out)}δ^{out,t}=δ^t
・delta[:,t] = (np.dot(delta[:,t+1].T, W.T) + np.dot(delta_out[:,t].T, W_out.T))
* functions.d_sigmoid(u[:,t+1])
【パラメータ更新式】
\begin{align}
W^{t+1}_{(in)}&=W^t_{(in)}-ε\frac{\partial E}{\partial W_{(in)}}= W^t_{(in)}-ε\sum^{Tt}_{z=0}δ^{t-z}[x^{t-z}]^T\\
W^{t+1}_{(out)}&=W^t_{(out)}-ε\frac{\partial E}{\partial W_{(out)}}= W^t_{(out)}-εδ^{out,t}[z^t]^T\\
W^{t+1}&=W^t-ε\frac{\partial E}{\partial W}= W^t_{(in)}-ε\sum^{Tt}_{z=0}δ^{t-z}[z^{t-z-1}]^T\\
b^{t+1}&=b^t - ε\frac{\partial E}{\partial b} = b^t-ε\sum^{Tt}_{z=0}δ^{t-z}\\
c^{t+1}&=c^t - ε\frac{\partial E}{\partial c}= c^t - εδ^{out,t}
\end{align}
・W_in -= learning_rate * W_in_grad
・W_out -= learning_rate * W_out_grad
・W -= learning_rate * W_grad
7-2-4 BPTTの全体像
●BPTTとして以下のように簡単に書くことができる。
それぞれ、中身を展開していく。
\begin{align}
E^t&= loss(y^t,d^t)\\
&=loss(g(W_{(out)}z^t+c),d^t)\\
&=loss(g(W_{(out)}f(W_{(in)}x^t+Wz^{t-1}+b)+c),d^t)
\end{align}
$f()$の中身は・・・
\begin{align}
&W_{(in)}x^t+Wz^{t-1} + b\\
&W_{(in)}x^t + Wf(u^{t-1})+ b\\
&W_{(in)}x^t+Wf(W_{(in)}x^{t-1}+Wz^{t-2}+b)+b
\end{align}
●コード演習問題
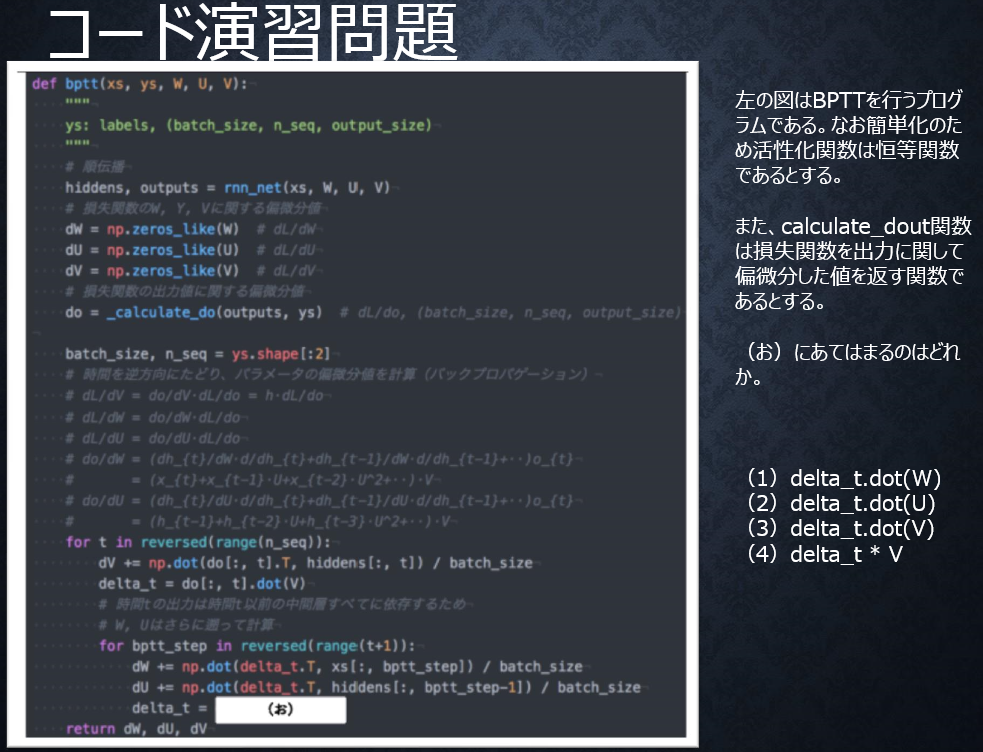
【自分の回答】
(3)delta_t.dot(V)
【解答】
(2)delta_t.dot(U)
RNNにおいて損失関数を重みWやUに関して偏微分するときは、
それを考慮する必要があり、$dh_{t}/dh_{t-1} = U$
であることに注意すると、過去に遡るたびにUが掛けられる。
つまり、delta_t= delta_t.dot(U)となる

7-3 Section2 LSTM
●RNNの課題
時系列を遡れば遡るほど、勾配が消失していく。
⇒長い時系列の学習が困難。
●解決策
構造自体を変えて解決したものがLSTM。
●勾配消失問題の復習
誤差逆伝播法が下位層に進んでいくにつれて、
勾配がどんどん緩やかになっていく。
勾配降下法による更新では、下位層のパラメータは、
ほとんど変わらず、訓練は最適値に収束しなくなる。
☆確認テスト☆
・7-3-1 シグモイド関数を微分した時、入力値が0の時に最大値
をとる。その値として正しいものを選択肢から選べ。
(1) 0.15 (2) 0.25 (3) 0.35 (4) 0.45
【自分の回答】
(2)0.25((1-0.5)×0.5)
【解答】
(2)0.25
●勾配爆発
勾配が、層を逆伝播するごとに指数関数的に大きくなっていく。
●演習チャレンジ
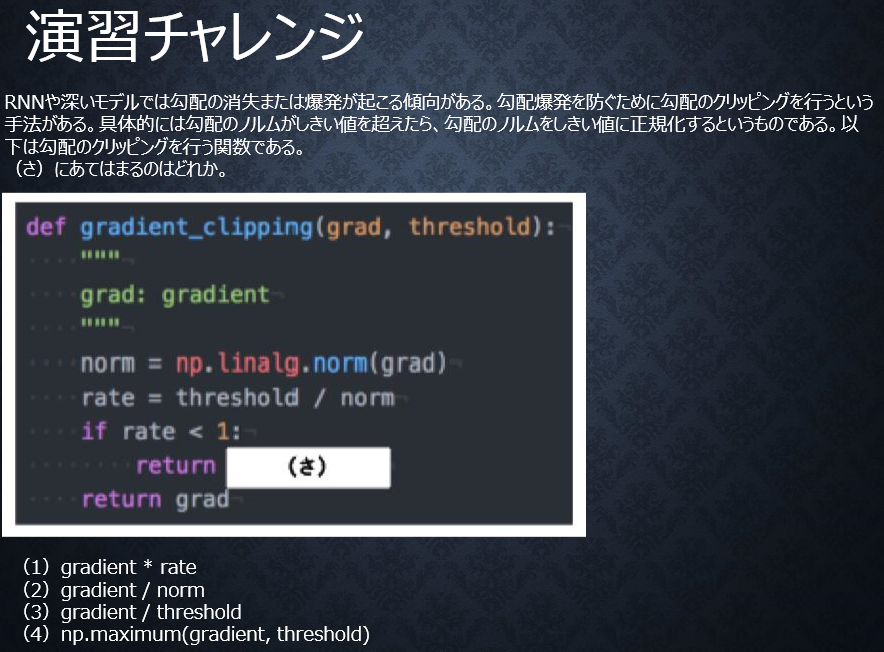
【自分の回答】
(3)gradient/threshold
【解答】
(1)gradient*rate
勾配に対してrateを掛け合わせるだけ。

7-3-1 CEC

●CEC
勾配消失および勾配爆発の解決方法として、
勾配が1であれば解決できる。
●CECの課題
入力データについて、
時間依存度に関係なく重みが一律である。
⇒ニューラルネットワークの学習特性が無い。
(そもそも学習が失われてしまう)
・入力層⇒隠れ層への重み・・・入力重み衝突
・隠れ層⇒出力層への重み・・・出力重み衝突 と呼ぶ。
7-3-2 入力ゲートと出力ゲート
●入力ゲート

●出力ゲート
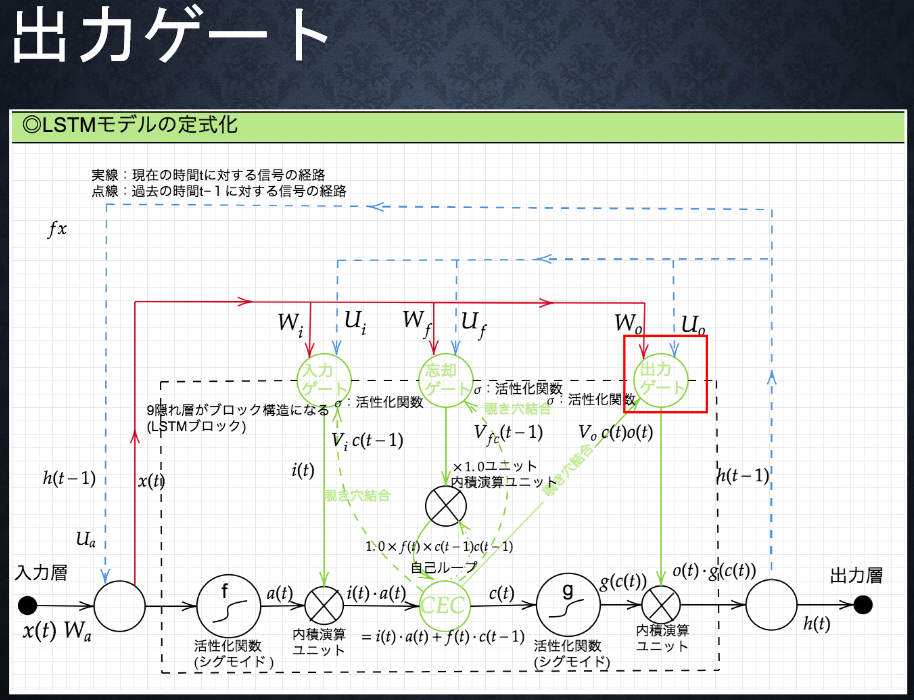
●入力・出力ゲートの役割
入力・出力ゲートを追加することで、
それぞれのゲートへの入力値の重みを、
重み行列WとUで可変可能とする。
⇒WとUを使うことで差分が生まれやすくなり、
CECの課題を解決できた。
7-3-3 忘却ゲート
●LSTMの現状
CECは過去の情報が全て保管されている。

●LSTMの課題
過去の情報が要らなくなった場合、削除できず、
保管され続けてしまう。
●解決策
過去の情報が要らなくなった場合、
そのタイミングで情報を忘却する機能が必要。
⇒忘却ゲートが誕生した。
☆確認テスト☆
・7-3-3-1 以下の文章をLSTMに入力し空欄に当てはまる単語を予測したいとする。
文中の「とても」という言葉は空欄の予測において
なくなっても影響を及ぼさないと考えられる。
このような場合、どのゲートが作用すると考えられるか。
「映画おもしろかったね。ところで、とてもお腹が空いたから何か____。」
【自分の回答】
忘却ゲート
【解答】
影響を及ぼさないがキーワード
⇒忘却ゲート
●演習チャレンジ

【自分の回答】
(3)input_gate* a + forget_gate* c
【解答】
(3)input_gate* a + forget_gate* c
新しいセルの状態は、計算されたセルへの入力と、
1ステップ前のセルの状態に入力ゲート、
忘却ゲートを掛けて足し合わせたものと表現される。

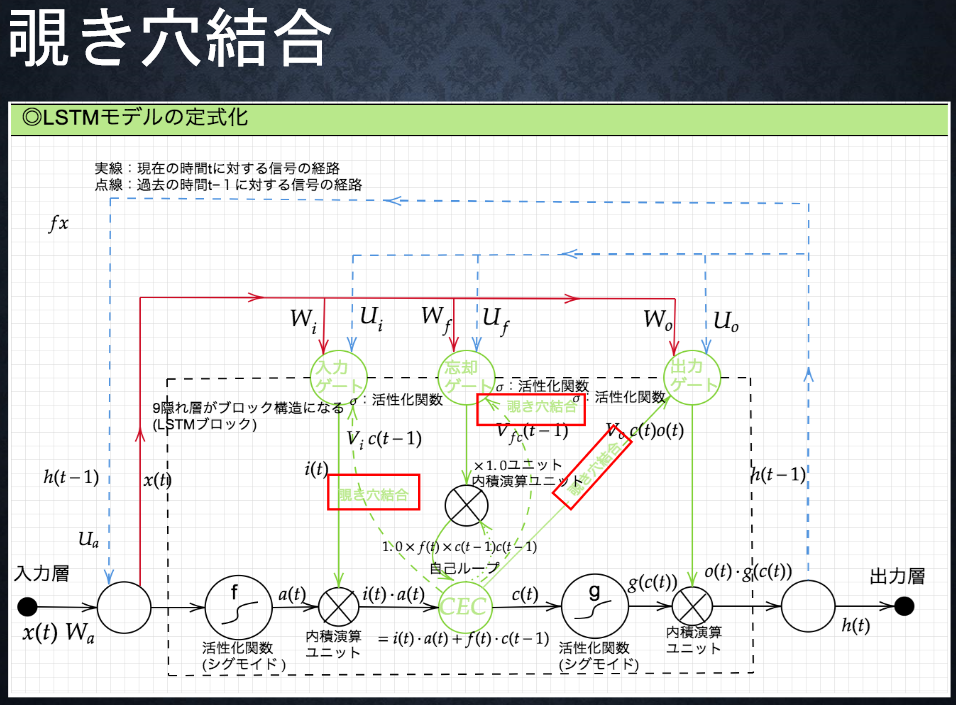
7-3-4 覗き穴結合
●課題
CECの保存されている過去の情報を、
任意のタイミングで他のノードに伝播させたり、
あるいは任意のタイミングで忘却させたい。
CEC自身の値は、ゲート制御に影響を与えない。
⇒覗き穴結合??
CEC自身の値に重み行列を介して伝播可能とした構造。
入力ゲート、忘却ゲート、出力ゲートに影響を与える。
7-4 Section3 GRU(Gated Recurrent Unit)
●LSTMの課題
パラメータ数が多く、計算負荷が高くなる問題があった。
⇒解決する方法としてGRU。
●GRUとは
従来のLSTMでは、パラメータが多数存在していたため、
計算負荷が大きかった。GRUではパラメータを大幅に削減し、
精度は同等または、それ以上が望めるようになった構造。
⇒計算負荷が低いメリットがある。
●GRUの全体像

☆確認テスト☆
・7-4-1 LSTMとCECが抱える課題について、それぞれ簡潔に述べよ。
【自分の回答】
LSTM ・・・ パラメータ数が多く、計算負荷が高い。
CEC ・・・ 過去の情報を全て保管しており忘却できない。
【解答】
LSTM ・・・ パラメータ数が多くて計算負荷が大分かかる。
CEC ・・・ 重みの概念が画一化する。最適なパラメータが学習できない。
●演習チャレンジ
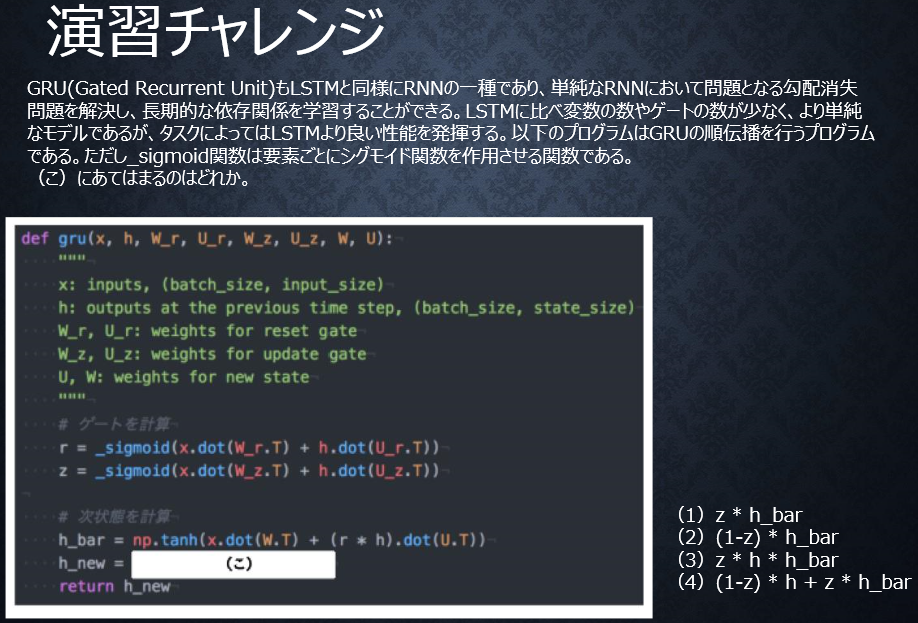
【自分の回答】
(3)z * h * h_bar
【解答】
(4)(1-z) * h + z * h_bar
迷ったんですよね・・・。
新しい中間状態は、1ステップ前の中間表現と計算された
中間表現の線形和で表現される。つまり更新ゲートzを用いて、
(1-z) * h + z * h_barと書ける。
⇒間違った方は全体像で再確認・・・。そうします↓↓↓

☆確認テスト☆
・7-4-2 LSTMとGRUの違いを簡潔に述べよ。
【自分の回答】
パラメータ数が違うため、計算量が違ってくる。
精度はあまり変わらない。
【解答】
相対比較し、LSTMはパラメータ数が多く、
GRUはパラメータ数が少ない。
⇒それぞれ処理を走らせてみて、検証することが必要。
パラメータはどこが多くて、どこが少ないか確認すると良い。
7-5 Section4 双方向RNN
●双方向RNN
過去の情報だけでなく、未来の情報を加味することで、
精度を向上させるためのモデル。

・実用例
文章の推敲や、機械翻訳等
●演習チャレンジ

【自分の回答】
(4)np.concatenate([h_f, h_b[::-1]], axis=1)
【解答】
(4)np.concatenate([h_f, h_b[::-1]], axis=1)
双方向RNNでは、順方向と逆方向に伝播したときの中間層表現を
あわせたものが特徴量となるので、
np.concatenate([h_f, h_b[::-1]], axis=1)である。

7-6 Section5 Seq2Seq
7-6-1 Seq2Seq
●Seq2Seqとは
Encoder-Decoderモデルの一種を指す。

●具体的な用途は
非常に特徴的で、機械対話や機械翻訳などに使用。
7-6-2 Encoder RNN
●Encoder RNN
ユーザがインプットしたテキストデータを、
単語等のトークンに区切って渡す構造。
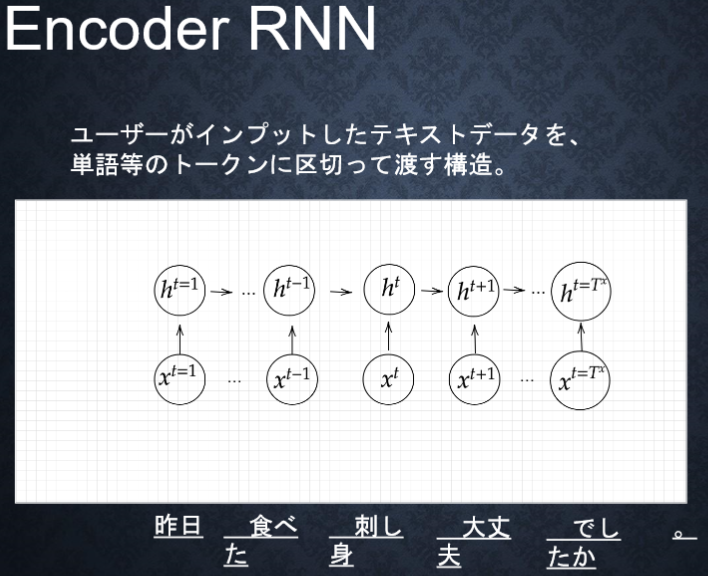
●Taking:文章を単語等のトークン毎に分割し、
トークン毎のIDに分割する。
●Embedding:IDからトークンを表す分散表現ベクトルに変換。
⇒数値化していく。
●Encoder RNN:ベクトルを順番にRNNに入力していく。
●Encoder RNN処理手順
・vec1をRNNに入力し、hidden stateを出力。
このhidden stateと次の入力vec2をまたRNNに入力してきた
hidden stateを出力という流れを繰り返す。
・最後のvecを入れたときのhidden stateをfinal stateとして
とっておく。このfinalstateがthought vectorと呼ばれ、
入力した文の意味を表すベクトルとなる。
vec(入力)→hidden state(出力)→最後のvec(入力)
→final state(出力)・・・thought vectorと呼ばれる。
7-6-3 Decoder RNN
●Decoder RNN
システムがアウトプットデータを、
単語等のトークン毎に生成する構造。

●Decoder RNNの処理
1.Decoder RNN: Encoder RNN のfinal state (thought vector) から、
各tokenの生成確率を出力していきます。
final stateをDecoder RNNのinitial stateとして設定しEmbeddingを入力。
⇒ベクトル化されているものから、次のワードを予測する。
2.Sampling:生成確率にもとづいてtokenをランダムに選ぶ。
3.Embedding:2で選ばれたtokenをEmbeddingしてDecoder RNN
への次の入力とする。
4.Detokenize:1~3を繰り返し、2で得られたtokenを文字列に直す。
⇒「お腹」の後にくる単語を予測し、生成確率が高いものを採用する。
「が」→「痛い」→「です」→「。」

☆確認テスト☆
・7-6-3-1 下記の選択肢からseq2seqについて説明しているものを選べ。
(1)時刻に関して順方向と逆方向のRNNを構成し、
それら2つの中間層表現を特徴量として利用するものである。
(2)RNNを用いたEncoder-Decoderモデルの一種であり、
機械翻訳などのモデルに使われる。
(3)構文木などの木構造に対して、隣接単語から表現ベクトル
(フレーズ)を作るという演算を再帰的に行い(重みは共通)、
文全体の表現ベクトルを得るニューラルネットワークである。
(4)RNNの一種であり、単純なRNNにおいて問題となる勾配消失問題を
CECとゲートの概念を導入することで解決したものである。
【自分の回答】
(2)
【解答】
(2)
●演習チャレンジ

【自分の回答】
(3)w.dot(E.T)
【解答】
(1)E.dot(w)
単語wはone-hotベクトルであり、
それを単語埋め込みにより別の特徴量に変換する。
これは埋め込み行列Eを用いて、E.dot(w)と書ける。
⇒内積を取る。特徴量に変換することに意味がある。

7-6-4 HRED
●Seq2Seqの課題
一問一答しかできない。
⇒問に対して文脈も何もなく、ただ応答が行われる。
⇒HREDは人間っぽさを出す。
●HREDとは
過去n-1個の発話から次の発話を生成する。
⇒Seq2Seqでは、会話の文脈無視で応答されるが、
HREDでは前の単語の流れに即して応答される。
より人間らしい文章が生成される。
【Seq2Seq+Context RNN】
Context RNN:Encoderのまとめた各文章の系列をまとめて、
これまでの会話コンテキスト全体を表すベクトル
に変換する構造。文脈をベクトル化。
⇒過去の発話の履歴を加味した返答ができる。
●HREDの課題
HREDは確率的な多様性が字面にしかなく、
会話の「流れ」のような多様性がない。
⇒同じコンテキスト(発話リスト)を与えられても、
答えの内容が毎回会話の流れとしては同じものしか出せない。
HREDは短く情報量に乏しい答えをしがちである。
⇒短いよくある答えを選ぶ傾向がある。
7-6-5 VHRED
●VHREDとは
HREDにVAEの潜在変数の概念を追加したもの。(???)
⇒HREDの課題を、VAEの潜在変数の概念を
追加することで解決した構造。
特にHREDの課題のうち、同じような回答をする部分が改善。
☆確認テスト☆
・7-6-5-1 Seq2SeqとHRED、HREDとVHREDの違いを簡潔に述べよ。
【自分の回答】
Seq2Seqは文脈を無視しているが、HREDは次の発話を生成し、
より人間的な文章が生成できる。
HREDは良くある答えを選択しがちであるが、
VHREDはHREDの課題を解決したものである。
【解答】
Seq2Seqは一問一答しかできない。
その課題を解決したものがHREDである。
HREDは会話の文脈に即して回答があるが、
毎回同じような回答がある。
VHREDはそれを改善し、違った回答がされる。
7-6-6 AE(Auto Encoder)
●AEとは
教師なし学習の一つ。
学習時の入力データは訓練データのみで教師データは利用しない。
⇒特徴の一つ。
MNISTの場合、28×28(=784)の数字の画像を入れて、
同じ画像を出力するニューラルネットワークになる。
●構造説明
入力データから潜在変数$z$に変換する
ニューラルネットワークをEncoder
逆に潜在変数$z$をインプットとして元画像を復元する
ニューラルネットワークをDecoder
●メリット
次元削減ができる。
$z$の次元が入力データより小さい場合、次元削減とみなせる。

●多角的に全体像を把握(牽引企業)
クラウド・・・AWS(使いやすい)
GCP(AWSの方が価格面でも使いやすい)
Googleが作っているTensorFlowが使いやすい。
ハード・・・nVIDIAが良い。
ソリューション:TOYOTAの自動運転技術等。
7-6-7 VAE
●VAE(バエ)とは
通常のオートエンコーダの場合、
潜在変数$z$にデータを押し込めているものの、
その構造がどのような状態かわからない。
⇒VAEは潜在変数$z$に確率分布z~N(0,1)を仮定したもの。
文脈に従って、答えの言葉が出てくる。
⇒VAEは、データを潜在変数$z$の確率分布という構造に
押し込めることを可能とする。
☆確認テスト☆
・7-6-7-1 VAEに関する下記の説明文中の空欄に当てはまる言葉を答えよ。
自己符号化器の潜在変数に____を導入したもの。
【自分の回答】
確率分布の構造
【解答】
確率分布
7-7 Section6 Word2vec
●RNNの課題
RNNでは単語のような可変長の文字列をNNに与えることはできない。
⇒固定長の必要がある。
●Word2vec
学習データからボキャブラリを作成
必要な分のボキャブラリができればよい。
(例)I want to eat apples.I like apples.
⇒{apples,eat,I,like,to,want}
●one-hot ベクトル
Applesを入力する場合は、入力層に以下のベクトルが入力される。
※本来は辞書の単語数だけone-hotベクトルができる。
●Word2vecのメリット
大規模データの分散表現の学習が、
現実的な計算速度とメモリ量で実現可能とした。
⇒従来はボキャブラリ数×ボキャブラリ数だけ重み行列ができた。
ボキャブラリ数×任意の単語ベクトル次元で重み行列ができる。
(次元を大分減らしてもその単語の意味を理解できる。)

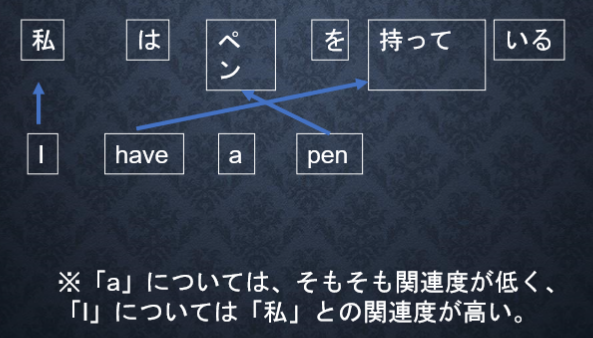
7-8 Section7 Attention Mechanism
●Seq2Seqの課題
Seq2Seqの問題は長い文章の対応が難しい。
2単語でも、100単語でも固定次元ベクトルの中に入力が必要。
●解決策
文章が長くなるほど、そのシーケンスの内部表現の次元も
大きくなっていく仕組みが必要となる。
⇒Attention Mechanism
⇒「入力と出力のどの単語が関連しているのか」
の関連度を学習する仕組みである。
関連度の精度を上げることで対応できるようになる。
☆確認テスト☆
・7-8-1 RNNとword2vec、seq2seqとAttentionの違いを簡潔に述べよ。
【自分の回答】
RNNとWord2vecの違いは、計算量が異なる。
Seq2SeqとAttentionは、長い文章への対応の差である。
【解答】
Word2vecの違いはWORDに対しての重り等が現実的な消費量で計算できる。
ボキャブラリ数×ボキャブラリ数⇒ボキャブラリ数×任意の単語ベクトル
Seq2SeqとAttentionは長い文章の取り込みであるが、
翻訳として成り立つこと。
●演習チャレンジ

【自分の回答】
これはパワポの資料に載っていない・・・。
(4)W.dot(np.maximum(left,right))
【解答】
(2)W.dot(np.concatenate([left,right]))
leftとrightを使ってベクトル化していくか。
特徴量に重みをかける。
●実務経験を積む
既存でデータがあるところで実務をする方が、
身に着けられる。AIの構造も研究であるが、
サービスとして分析・モデル化したもの提供するのも経験である。