先般(2023-09-09)、佐賀在住の技術コミュニティ ローコードツール勉強会 主催の "Power BI 勉強会 in 佐賀" でモデリングのお話をしてきた、
読んだだけでわかるようなスライドを作る習慣はないからスライド単体での共有はない。だけど、当日いくつか質問をもらっているので、補足や当日話したこと説明することができなかったことなど含めてポストする。
話そうとしたきっかけ、思いなど
このポストでは"○○したほうがよいですよ"などあいまいな表現をしません。
DO もしくは DON'T です。
手元の四角い箱で検索した結果や○○する方法とか探していても、いつまでたっても "できる"ようにはならないのだ。一時的な成果で "できた" になるだろうけど。
手段/方法を選択判断するプロセスが欠けているから、問題が発生しても対処するすべがわからない。提案を目利きする能力が不十分だから、そもそも失敗していることにさえ気づけないかもしれないよね。
ビジュアルの設定をしても期待通りに表示できないとか、メジャーに定義する式がわかりませんとか、そのような類が私の手元に届けられる。それらの原因がモデリングというケースが非常に多いのである。入門書や動画など既に用意されたコンテンツで基礎を学んでいるはずなのにね🤔なぜできていないの?
モデリングを始めるなら、 まず最初にあるべき状態(シンプル かつ 機能的)で土台を築くことが必要。難しいことや複雑なことは後回しでよい。だって、理解できていない手法を選択してもうまくいくわけないから。最悪なケースは失敗していることに気付けないことだ。
モデリングという作業
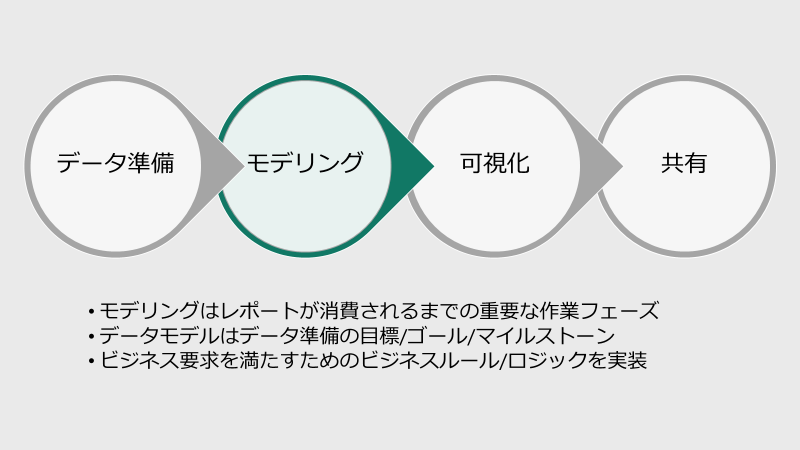
Power BI では、レポートがユーザに展開されるまでの間で、
1.データ準備 ⇒ 2.モデリング ⇒ 3.可視化 ⇒ 4.共有
という作業フェーズになるはずだ。そして、作業フェーズごとの成果物は次のフェーズの開始点なのである。
モデリングで必要な作業が行われていないと、 ビジュアルに正確な集計結果を投影できない/集計結果を得るまでのパフォーマンスが許容範囲を超えてしまうことなんて日常茶飯事。
どのようなデータモデルが必要なのかを目標/マイルストーンとして定めていないと、データ準備で何をすべきなのか選択決定できないまま。
それなのに漫然と作業を続けるのは最悪だ。なにも考えずデータを準備、モデルにロードしビジュアライズ。そこで実現できる集計はごく僅かになるのでしょう。さらなるビジネス要求に対応できない。
どんなに忙しくてもやらなければならない
では、どうするか。まずはベストプラクティスだけを選択すればよい。学びはじめならなおさらのこと。
説明されていることを理解し実施するだけのこと。それだけでも充分な効果がある。すべて技術的に説明可能な内容であり合理的でもある。ほとんどのビジネス要件をサポートする実績のある手法で根拠の乏しいおまじないでもない。
ベストプラクティスがなぜベストプラクティスなのか。
複雑なことや高度なことから始めてレベル上げをしようとするより、ベストプラクティスに挙げられる内容を技術的に説明できるようになることが重要だ。
プロの仕草は破天荒な型破りではない。基本となる所作は正確に繰り返すことができ、かつ、常に状況を把握し適切な判断をできるようにしているのだ。型があるゆえの型破りであり、その効果だけではなく、限界を説明できるということだ。
ビジネスデータは想像以上に複雑な構造である。たとえば、サンプルデータのような単純ではないのが普通。なので、複雑であることをそのままにモデリングに臨んではいけない。レポートへのビジネス要件から必要なモデリング/必要なデータ準備をしなければならないのだけど、それはレポートユーザのリクエスト(話し言葉)をデータモデル/データ準備の言語に翻訳し、それぞれごとにロジックとして実装するということ。論理的、効率的、かつ、速やかに検討できるようにベストプラクティスはすでに用意されているのだ。
スタースキーマ
データモデルのメタデータ/スキーマ情報だけで、どのようなデータが存在しどのような集計が可能なのかがわかるようになっている。スタースキーマだけに限った話ではないと思うけどね。
- ビジネス エンティティによる構成
- テーブル(エンティティ)の行ごとで、ひとつの ヒト/モノ/デキゴトなど を表す
- 行に含まれる列は属性を表す値が含まれる
- ビジネス エンティティは OLTP に定義されるテーブルとは異なる実装
- 2種類のテーブルとその役割
- ディメンションテーブル
- ビジュアルの見出しや軸、凡例に利用する列を含むテーブル
- 行を特定できるキー(主キー)が必要
- ファクトテーブル
- 行ごとでデキゴトやアクティビティを表す
- 集計される値が含まれる列
- ディメンジョンテーブルの主キーを外部キーとする列
- ディメンションテーブル
- リレーションシップ
- ビジネスエンティティ間の関連付け
- データモデルに既定のクロスフィルタ動作を定義する
- OLTP のように参照整合性を制約するものではない
データソースのフォーマットやエンティティをそのままデータモデルに持ち込まないことが超大事。なので、特徴をデフォルメした話をすることが多い。
-
Excel ユーザの皆さんへ
必ず正規化をしてください
テーブルひとつだけではビジネス要求を満たす集計ができません -
データベースエンジニアの皆さんへ
必ず非正規化をしてください
リレーショナルデータベースの正規化する手法はデメリットです。
だれであっても、最初に必要とされるモデリング手法は常にスタースキーマ。シンプルな構造だから、集計パフォーマンスに優れ、そして拡張性にも優れている。
特別なビジネス要件を満たすために部分的にスタースキーマから逸脱し最適化として許容することがある。それでも常にスタースキーマから始めるべきだ。なぜなら、
- 最適化の効果を測定できるようにする
- 最適化の副作用の範囲を計測する
- 副作用が想定した許容範囲に収まることを実証する
少なくとも、採用した理由/判断が明確ではない逸脱は単なる設計ミスになるということだ。
DO / DON'T
よく遭遇する初歩的なミスチョイスを取り上げる。
ディメンジョンテーブル
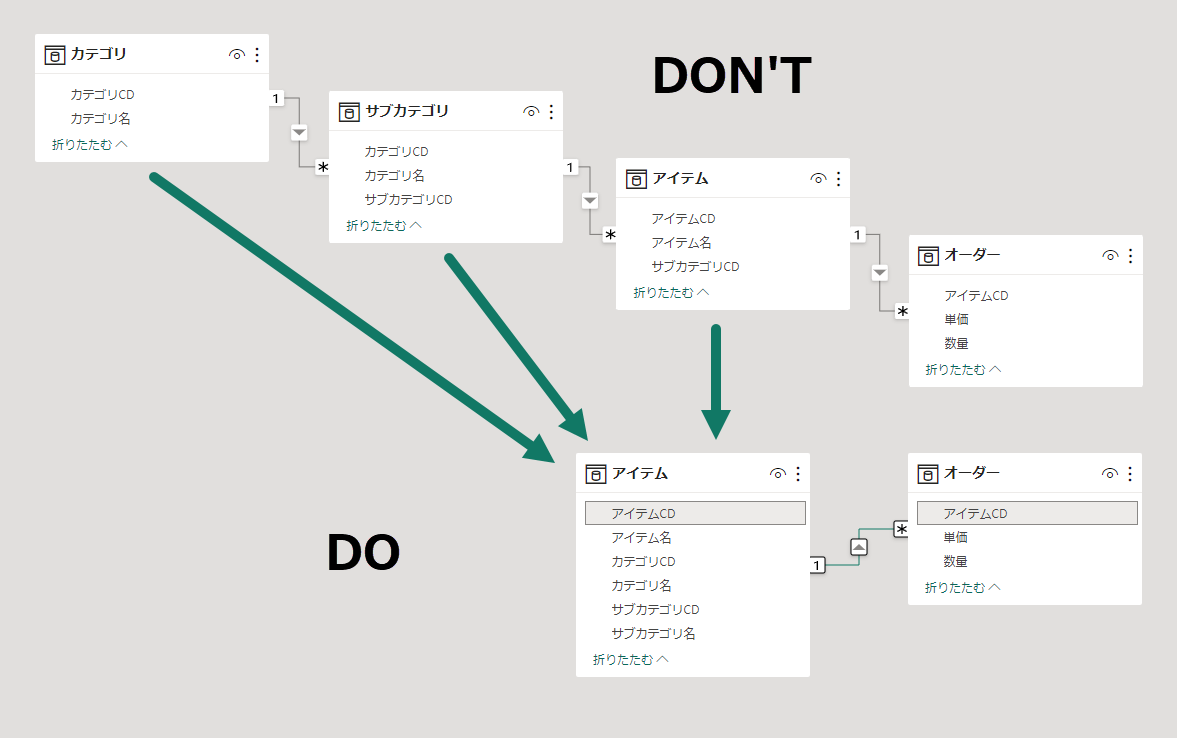
- Power BI では高効率で保存/集計可能な列指向データベース/列指向フォーマットが採用されているから、列に含まれる値が繰り返されていても OLTP で忌避するような影響はなく、クエリの評価効率がよい
- 非正規化による効果は正規化によるデメリットを常に上回る
- 最適化が必要になるとき、部分的なスノーフレークスキーマを選択できる余地を残しておくべき
ファクトテーブル
ファクトテーブル間のリレーションシップを定義しない。
クエリの評価パフォーマンスを低下させるだけだから。
- 非正規化を行い、2つのファクトテーブルがディメンジョンテーブルを共有するデザイン
- そもそもファクトテーブルはひとつでなくてもよい
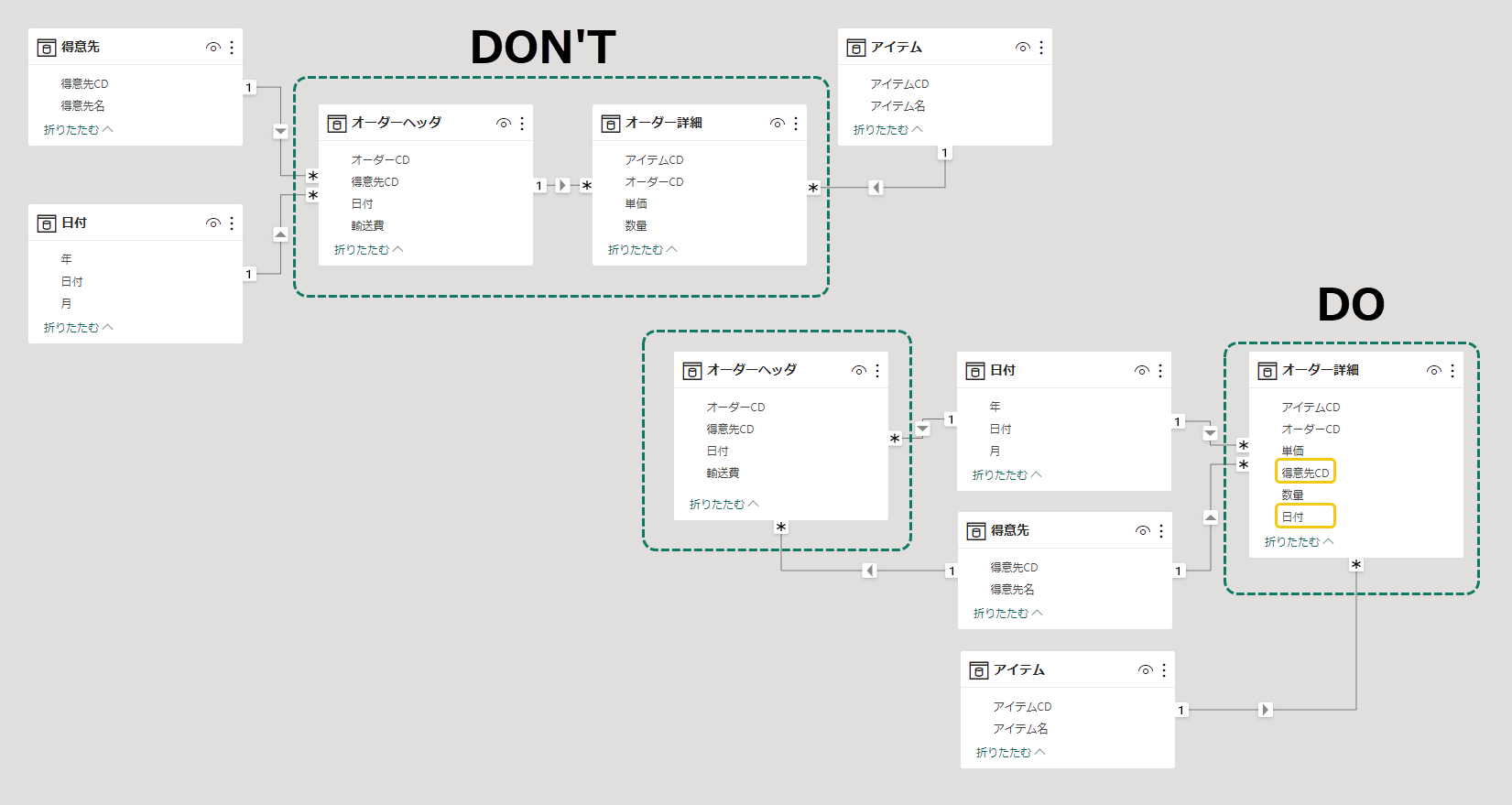
この例では、ヘッダテーブルに存在する列を詳細テーブルにも用意していて、異なる集計粒度もサポートしている
リレーションシップ
リレーションシップはデータモデルに定義するビジネスエンティティ間の既定のクロスフィルタ動作。参照整合性を制約するものではない。
リレーションシップにはいくつかの種類があるけれども、どれ使ってもいいよっていうことではない。
One to Many / Single になっていないとき、それはなぜですか?とその理由を考えるか聞いてみるとよい。
モデリング(スタースキーマ)を始めるとき、
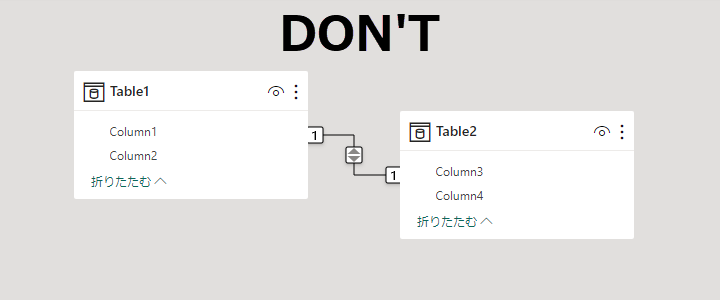
- リレーションシップは 常に One to Many / Single
- それ以外はイレギュラー
- イレギュラーを常習化しないことがコツ
常に One to Many / Single で定義する。
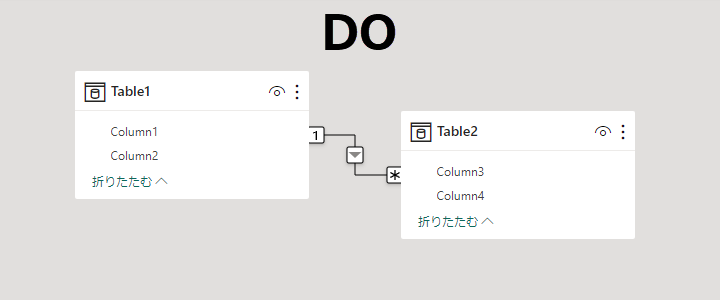
リレーションシップの定義でクロスフィルタの方向を Both にする必要はない、副作用によるあいまいさが増すだけ。
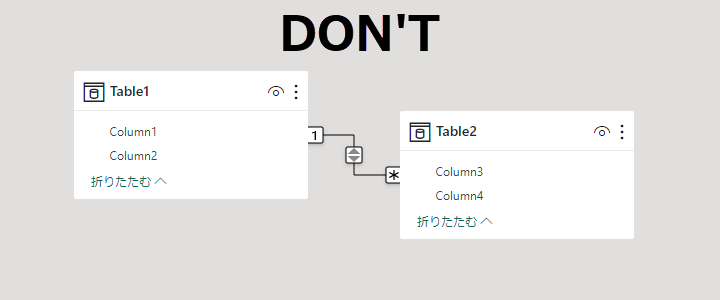
One to One を使用することはほぼない。テーブルをひとつにすることが最優先。
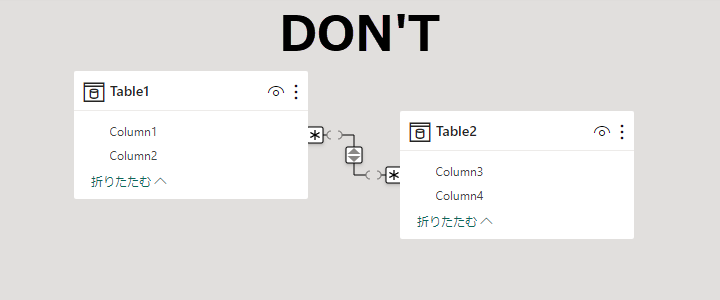
Many to Many は常に制限付きリレーションシップになる。
課せられる制限を理解できてないなら使用してはいけない。制限を理解していても使用する時は限定的。
Many to Many / Both になれば、制限 + あいまいさ という多重の困難さ
ビジネスルールの実装
モデリング作業は、 データモデルにビジネスルール/ビジネスロジックを実装する作業
だから、集計ができない もしくは 困難 というのは大きな問題だ。
よくある失敗は、"実績がない" ということも "実績"ということを考慮できていない。
- "実績がある" ことは部分的なデータでも集計可能
- "実績がない" という集計にはすべてのデータが必要
この課題を解決するために常にディメンジョンテーブルが必要である。
そして、ディメンジョンテーブルにはすべて行とすべての属性を表す列が必要である。
テーブルひとつだけのモデル
ディメンジョンテーブルがなければ "実績がない" という集計ができない
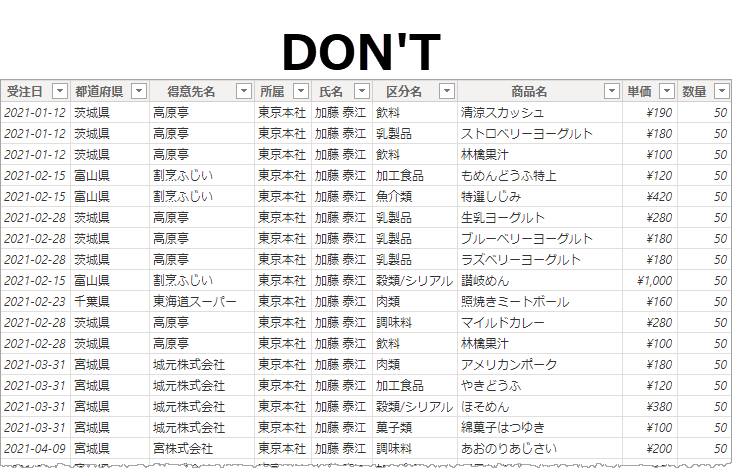
ビジネスルールを実装していないディメンジョンテーブル
テーブルはビジネス エンティティだから、たとえば担当者テーブル(ディメンジョンテーブル)には、だれがどのセクションに属しているかのビジネス ルールが明示されている必要がある。
なのだけど、ディメンジョンテーブルがビジネス エンティティになっておらず、重要なビジネスルールを損なっているケースがある。これも"実績がない" という集計が困難になる。
- 実績がない担当者は集計できる
- 実績がない担当者所属は集計できる
- 担当者所属ごとで実績のない担当者の集計は困難
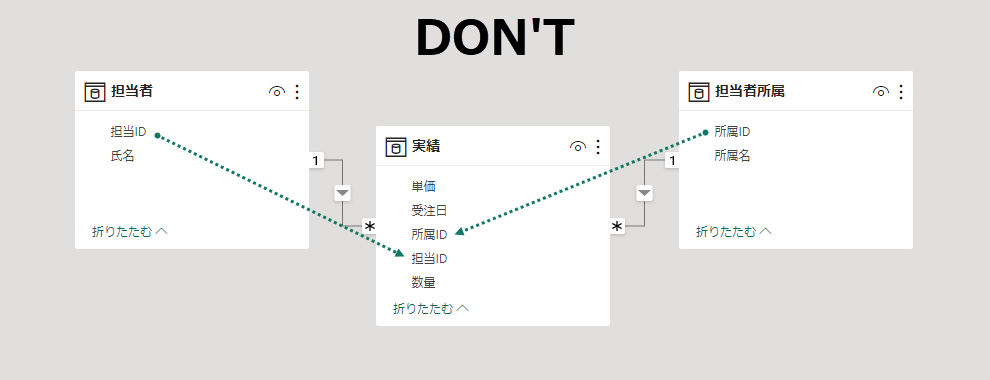
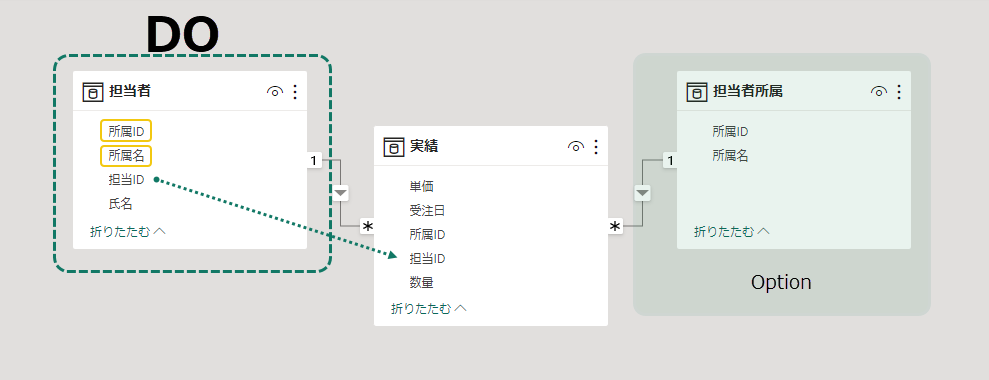
担当者が属している所属情報は重要なので、ビジネスエンティティとして十分機能を果たす構成になっている必要がある。オプションとして担当者所属テーブルを追加した状態もメリットがある。ディメンジョンテーブルの行数が多くなりすぎたときに利用できる最適化のひとつ。
主要ビジネスルールの実装例 - SCD
ディメンジョンテーブルもファクトテーブル同様に変化する。行が追加されたり行の属性列に含まれる値が更新されたりと。このとき、一貫した集計を維持するための手法が SCD(Slowly Changing Dimension)という。
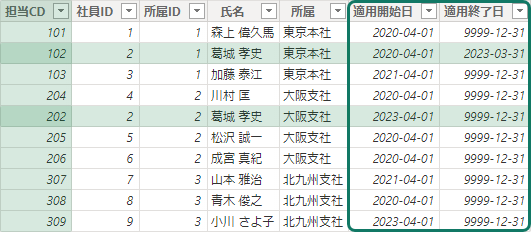
例として組織の人事異動や組織を兼任するケースを挙げる。

このままでは異動や兼任というビジネスルールを実装できないので行を追加しなければならない。
属性: 所属が変更された行を追加し、"東京本社の葛城孝史" と "大阪支社の葛城孝史"という人物を定義
このディメンジョンテーブルでも、所属ごと、担当者ごと、所属と担当者ごとの集計が引き続き可能
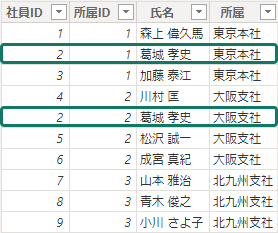
ただし、ファクトテーブルとのリレーションシップが Many to Many になってしまうので、ディメンジョンテーブルの行を特定する主キーとして代理キーが必要
当然ファクトテーブルにもリレーションシップを定義できる列の準備が必須
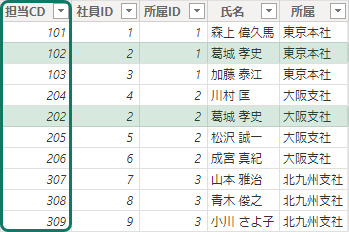
これだけでも概ね集計はできるけれども、属性の変更を表す属性列が必要
この例では、適用開始日と適用終了日のこと
追加された行や属性列を使えば異動前後での比較も可能になるでしょ。
思ったこと🙄
ね、かんたんでしょ🫠
やらなければならないことをやらないままだと、何もできないんだよ。
スタートはいつもシンプルな状態からだよ。
その他