いずれもよく使う関数だけれども、得られる効果丸暗記系の人がよくやってしまう間違いなので。意味的に同じ CALCULATETABLE 関数を含め FILTER 関数と何が違うのさってことをよく理解しておかなければならないのである。得られる効果の一部が似ているだけであって、そもそもの存在理由が異なるのです。
FILTER 関数
テーブルにフィルタを適用
CALCULATE / CALCULATETABLE 関数
新たにフィルタ コンテキストを用意してイイ感じにしてから評価
どんなことが起きるのか
日付テーブル : Dates と ファクト テーブル : Sales があり、リレーションシップが定義されている。日付など時系列の集計が可能なデータモデルになっている。
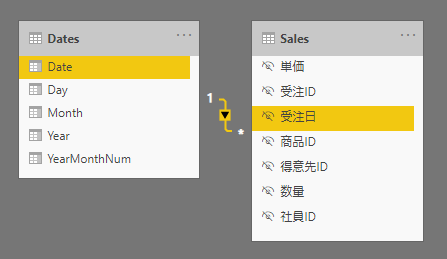
そこで日付ごとの累積した結果を得ようとしたとき、集計のロジックは、
- 投影されたテーブル行ごとの日付以前を行ごとで集計すれば累積値を得ることができる。
- 行ごとの日付以前 を FILTER 関数 か CALCULATE 関数のどちらで表現すべきか。
- いずれも同じ結果を得ることはできる。
さきに結論 : こういうときは FILTER 関数じゃなくて CALCULATE 関数
フィルタ コンテキストがイイ感じに利用されることはとても大事。
試して確認すること大事
比べるのに都合がよいので、SUMX 関数を使います。
SUMX 関数の テーブル引数で FILTER 関数
EVALUATE
ADDCOLUMNS(
Dates,
"SalesAmount RT", SUMX(
FILTER(
Sales,
Sales[受注日] <= Dates[Date]
),
Sales[単価] * Sales[数量]
)
)
ORDER BY Dates[Date]
注目点
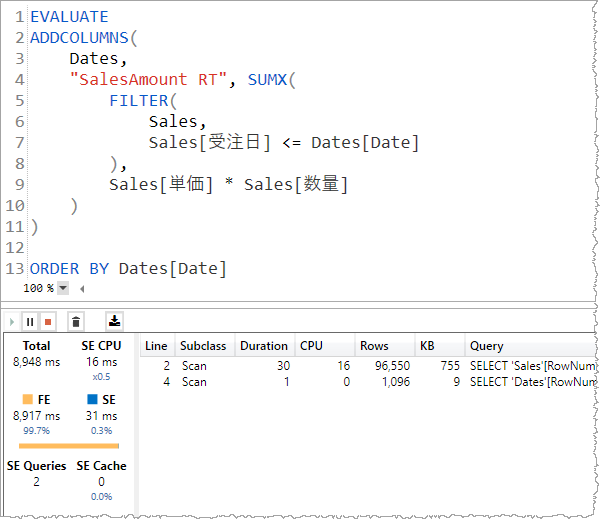
わずか 96,000行 / 1,100 行なのに DAX Query の評価完了まで 約 9 秒を要したことは解決すべき重要な問題ではあるけれども、問題はそれだけではない。
2行目の Query をみたとき、
SET DC_KIND="AUTO";
SELECT
'Sales'[RowNumber], 'Sales'[受注日], 'Sales'[数量], 'Sales'[単価]
FROM 'Sales';
となっていて、"SELECT 'Sales'[RowNumber], ... FROM 'Sales';" となっているから、Storage engine (SE) が メモリ上にキャッシュされるクエリは集計されたものでなくSales テーブルすべての行を含んでいるよねと。 'Sales'[RowNumber] というのは Sales テーブルの行の識別子なのだけど集計に使用することはできない。いわゆる中の人用。
Rows 列 で "96,550" となっているから、Sales テーブルの行数と合致し、容量 755 KB との見積もりではある。さて、たった 10万行弱 だからなんとかセフセフだったけどさ、GB級のキャッシュがリソースを消費する事態もあり得るわけですよ。
EVALUATE
ADDCOLUMNS(
VALUES( Dates[Date] ),
"SalesAmount RT", SUMX(
FILTER(
Sales,
Sales[受注日] <= Dates[Date]
),
Sales[単価] * Sales[数量]
)
)
ORDER BY Dates[Date]
SUMX 関数を CALCULATE 関数でラップ
EARLIER 関数 ではなくてよいんだけど、見た目を似せておこうと思っただけ。
EVALUATE
ADDCOLUMNS(
Dates,
"SalesAmount RT", CALCULATE(
SUMX(
Sales,
Sales[単価] * Sales[数量]
),
Sales[受注日] <= EARLIER( Dates[Date] ),
ALL( Dates )
)
)
ORDER BY Dates[Date]
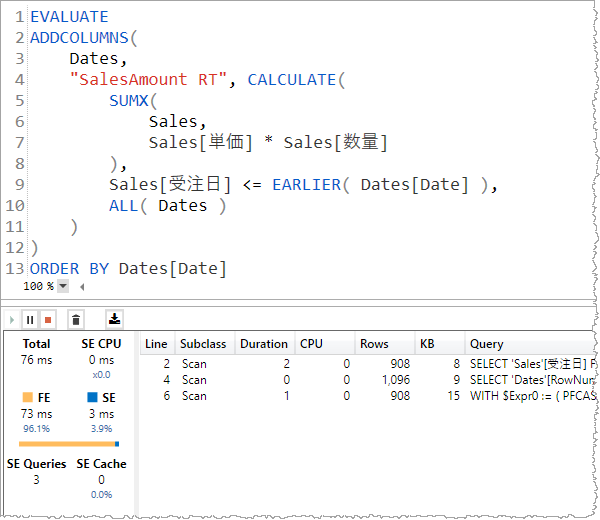
注目点
同じ結果を得るために 0.1 秒程度を要した。大きな改善である。というか、CALCULATE 関数を使うとフィルタ コンテキストが効果的に利用されるから本来の性能なのである。
SET DC_KIND="AUTO";
SELECT
'Sales'[受注日]
FROM 'Sales';
そもそも Sales テーブルすべての行をキャッシュする必要がなかったし、ここで得ているのは Sales[受注日] 列 のみでユニークな値のセット。暗黙に DISTINCT キーワードが追加されていると考えるとよい。
SET DC_KIND="AUTO";
WITH
$Expr0 := ( PFCAST ( 'Sales'[単価] AS INT ) * PFCAST ( 'Sales'[数量] AS INT ) )
SELECT
'Sales'[受注日],
SUM ( @$Expr0 )
FROM 'Sales'
WHERE
'Sales'[受注日] IN ( 42552.000000, 42798.000000,
..[263 total values, not all displayed] ) ;
ここで注目するのは、Sales[単価] * Sales[数量] の計算とその和、Sales[受注日] ごとの集計がこの時点で行われていること。これは Storage engine の特徴であり役割でもあるんだよね。
これ以降は Formula engine が わっせわっせと計算するのだけど、予め計算済みの結果からの集計だから作業が少なくて済んでいるのである。
EVALUATE
ADDCOLUMNS(
VALUES( Dates[Date] ),
"SalesAmount RT", CALCULATE(
SUMX(
Sales,
Sales[単価] * Sales[数量]
),
Dates[Date] <= EARLIER( Dates[Date] )
)
)
ORDER BY Dates[Date]
思ったこと🙄
そもそも効率のよい格納と読み出しそして集計ができるようヒトにはできない工夫がされているわけだ。そこにヒトが手計算するためのような準備を強要するとそりゃ遅くなりますよね。フィルタ コンテキストはとても重要な概念であり機能なんだけど、DAX coder はこれをよく理解する必要がある。Engine に対しどのような情報を伝えるかなんだよねと。
調査には DAX Studio 使っていますが、SQL Server Profiler でもよい。
で、Storage engine の結果などを示している情報は 疑似的に SQL っぽく表現されているだけで、問い合わせに利用されているわけではないですよ。と思ったら内部的には xmSQL 問い合わせらしくて表示は簡略化されているだけらしい。