AVERAGEX 関数でいろんな平均(算術平均)を求めるパターン。Excel の ピボット テーブル(Excel データモデル), SSAS でも通用するはず。
AVERAGE 関数 / AVERAGEA 関数
AVERAGE Function (DAX) は引数に 集計対象の値を含む [列] を指定するもので、テーブルの列(計算列を含む)の値から算術平均が求められる。"A" がつく AVERAGEA Function (DAX) は、数値以外の値が集計対象に含まれる場合の扱いをどうするかに違いがあって、値を 0 とみなしたり、除数に組み入れたりする違いがあるだけ。ただ、計算済みの値が必要があり、引数にメジャーを使用することができない。
AVERAGEX 関数
AVERAGEX(
<table>, // テーブル名 もしくは テーブル式
<expression> // 評価対象
)
引数:table の 行ごと で 引数:expression を評価し、それらから算術平均を得る。ポイントは、引数:table が テーブル式でもよいということ。
いくつかのパターン
では、いくつかパターンを作ってみる。
ベースになるもの
基本的なスタースキーマで、ファクト テーブル '受注' に いくつかのディメンジョン テーブルが関連している状態。そして、テーブル '受注' は、ヘッダー情報とディテールを非正規化しひとつのファクトテーブルにまとめたもの。なので、ヘッダー情報の 受注ID / 得意先ID / 社員ID / 受注日 は繰り返しが含まれる。
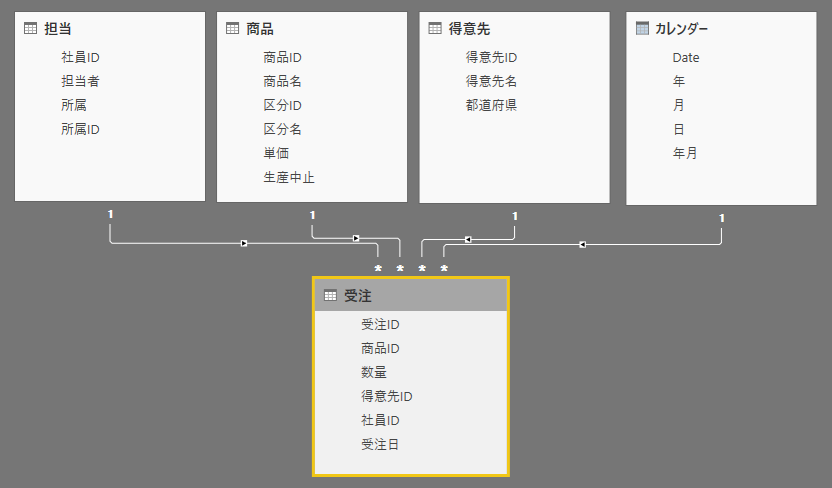
受注に関するデータモデルなので受注額を対象とし、数量と単価から計算する [受注額] を集計する。
受注額 = SUMX ( '受注', [数量] * RELATED ( '商品'[単価] ) )
平均ではないけれども、テーブル '受注' の行ごとで評価された結果の和。使い方は AVERAGEX 関数と同じ。
このデータモデルでは使わないパターン
ひとつめ = AVERAGEX ( '受注', [受注額] )
これは何を意味するのかなのだけど、テーブル '受注' の行ごとに [受注額]が評価され、その算術平均を返している。なので、
ひとつめalt = DIVIDE ( [受注額], COUNTROWS ('受注') )
と同じ結果になる。このデータモデルではたぶん使わないパターンでしょう。
"ほにゃらら" ごとの平均
ファクトテーブルの行ごとの集計でない場合、引数:table を 集計されるべき粒度をしめした テーブル式 にする。
受注額平均(受注ごと) = AVERAGEX ( VALUES ( '受注'[受注ID] ), [受注額] )
受注額平均(受注ごと)alt = DIVIDE( [受注額], DISTINCTCOUNT( '受注'[受注ID] ) )
同じように
受注額平均(担当者ごと) = AVERAGEX ( VALUES ( '受注'[社員ID] ), [受注額] )
受注額平均(担当者ごと)alt = DIVIDE( [受注額], DISTINCTCOUNT( '受注'[社員ID] ) )
VALUES Function (DAX) は、引数に 列名 を受け、列に含まれる一意の値リストをひとつの列として持つテーブルを返す。結果、集計対象のメジャー[受注額] はそれら値ごとに評価され、AVRAGEX で算術平均値を得ることができる。

まぁ、合いますよね。目を皿にすることでもない。
ここで理解しておくことがあって、
例えば担当者ごとの集計をしたとき、在籍していないとか、実績がないとき、つまりファクトテーブル '受注'に存在しない行については、[受注額] は BLANK と評価され 平均値の集計に組み込まれない。なので、実績がないときの結果を 0 として 平均に組み入れる場合は、
AVERAGEX( VALUES( '担当'[社員ID] ), [受注額] + 0 )
入社日など情報があれば、
AVERAGEX( FILTER( '担当', '担当'[入社日] <= MAX( 'カレンダー'[Date] ) ), [受注額] + 0 )
のような感じで人事情報を合わせた集計ができるのかと。
移動平均を求める
以前6か月を対象とする移動平均(月ごと)
まず、カレンダーでの月単位を表すテーブルが必要
SUMMARIZE( 'カレンダー', 'カレンダー'[年], 'カレンダー'[月], 'カレンダー'[年月] )
[年]列 と [月]列 の組合せ、 [年月]列は 同じ月単位を表すものであるけれども、レポートに配置したビジュアルの軸に使用されることがあって、いずれでも期待する集計ができるように組み入れている。
で、このテーブルの行ごとで集計していく。集計される行以前6か月の範囲でフィルタは
CALCULATETABLE(
SUMMARIZE( 'カレンダー', 'カレンダー'[年], 'カレンダー'[月], 'カレンダー'[年月] ),
DATESINPERIOD( 'カレンダー'[Date], LASTDATE( 'カレンダー'[Date] ), -6, MONTH )
)
とし、
受注額移動平均(6M) =
AVERAGEX (
CALCULATETABLE (
SUMMARIZE ( 'カレンダー', 'カレンダー'[年], 'カレンダー'[月], 'カレンダー'[年月] ),
DATESINPERIOD ( 'カレンダー'[Date], LASTDATE ( 'カレンダー'[Date] ), -6, MONTH )
),
[受注額]
)
AVERAGEX 関数 で 平均値を集計する。
たとえば、
AVERAGEX (
DATESINPERIOD ( 'カレンダー'[Date], LASTDATE ( 'カレンダー'[Date] ), -6, MONTH ),
[受注額]
)
とした場合は、カレンダーテーブルの行単位 つまり [Date]列ごとに集計される。このとき、集計している行含め以前6か月の範囲で[受注額]が評価され、DISTINCTCOUNT( '受注'[受注日] ) が除数とした算術平均と一致する。
以前5受注日を対象とする移動平均(受注日ごと)
カレンダーではなく、受注日で移動平均を集計する場合。使う関数が増えた分フクザツになりますね。
受注額移動平均(5営業日) =
AVERAGEX (
VAR Dates =
TOPN (
5,
FILTER ( ALL ( '受注'[受注日] ), '受注'[受注日] <= LASTDATE ( 'カレンダー'[Date] ) ),
'受注'[受注日], DESC
)
RETURN
DATESBETWEEN( 'カレンダー'[Date], FIRSTDATE( Dates ), LASTDATE( Dates ) ),
[受注額]
)
FILTER ( ALL ( '受注'[受注日] ), '受注'[受注日] <= LASTDATE ( 'カレンダー'[Date] ) )
まず、
レポートのビジュアルでは 'カレンダー' をもとに集計するので、フィルターが適切に伝搬する必要があり、'受注'[受注日] は 'カレンダー' からフィルターが伝搬しているので、ALL で 除外。
TOPN (
5,
FILTER ( ALL ( '受注'[受注日] ), '受注'[受注日] <= LASTDATE ( 'カレンダー'[Date] ) ),
'受注'[受注日], DESC
)
TOPN 関数で '受注'[受注日]の最近5受注日('受注'[受注日] を DESC(降順) で 5件)を参照し、その行ごとに[受注額]を集計する。
TOPN Function (DAX)
テーブル もしくは テーブル式 から 評価式の昇順もしくは降順で n 行抽出。得られる行は一意。
まだ終わりません
このままだとイケてない集計結果を表示してしまうことがあるので、集計自体の定義以外に工夫が必要。
