このポストの目的は、よくわからないけどとか、なんとなく使っているということをやめるきっかけになるかな?ってこと。
- あと一歩動作原理に近づいて、機能の仕組みを把握すること
- 一歩戻って、機能を納得ずくで使うこと
きっと DAX は難しい。わからないまま難しいことを始めるのはよくない。フィルタ コンテキストという言葉が馴染んできたとして、フィルタが伝搬する仕組みをほんとに理解できていますか?タイトルからはチクチク成分を除外したつもりですが、よくわかってないまま難しいことを始めないほうがいいよということだ。
特に DAX でテーブルが評価されるときの動作を把握できていないケースが多い。大事なことなのでもういちど、テーブルがフィルタ コンテキストで評価されるときです。
Expanded table
セマンティック モデルに定義されたテーブルが DAX で評価されるとき、テーブルに含まれるネイティブな列だけでなく、リレーションシップを介して関連付けられた別のテーブルの列も含む Expanded table(拡張されたテーブル)として認識される。概念上の動作であり、セマンティック モデルに Expanded table(拡張されたテーブル)が追加されるわけではない。
フィルタ コンテキストの動作やフィルタの伝搬を把握するためにも、この特徴的な動作を理解しておくことが望ましい。
うーん、難しいと思ったら...
難しいと感じたら無理をする必要はない。まずは次に挙げるベストプラクティスを厳守すればよく、多くのケースで十分に対応可能だから。
✅リレーションシップの種類は One-to-Many または Many-to-One を選択する
✅CALCULATE 関数の filter 引数には FILTER 関数を使用しない
✅フィルタの定義はテーブル フィルタよりも列フィルタを優先する
これらのベストプラクティスに沿えば、多くのビジネス要求にある集計結果が適切に得られるはず。余裕ができたときに Expanded table という概念があったなと思い出し、改めて学び直すことで、いっそう深い理解を得ることができるでしょう。
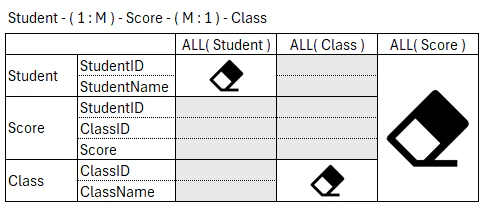
列が追加されるルール
Expanded table は、常にシンプルなルールに基づき、関連するテーブルの列を展開する。
- リレーションシップの 1 側のテーブルの列が追加される
- Power BI セマンティック モデルの場合、標準リレーションシップであること
- クロスフィルタの方向(Single / Both)には依存しない
例を挙げて説明する。
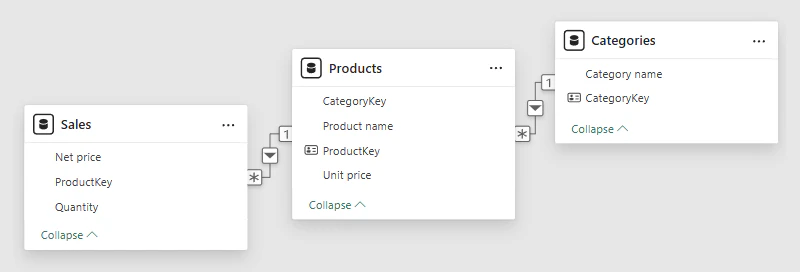
このセマンティック モデルでは、Sales テーブルをファクト テーブルとし、Products テーブル、さらに Categories テーブルへと、1 側に向かうリレーションシップが順に定義されている。なお、スノーフレーク スキーマである点については、ここで取り上げるトピックではない。
3 つのテーブル(Sales、Products、Categories)が DAX により評価されるとき、各テーブルの Expanded table は以下の通り。
| テーブル | Expanded table に含まれる列 |
|---|---|
| Sales | Sales テーブルすべての列 Products テーブルすべての列 Categories テーブルすべての列 |
| Products | Products テーブルすべての列 Categories テーブルすべての列 |
| Categories | Categories テーブルすべての列 |
動作を観察
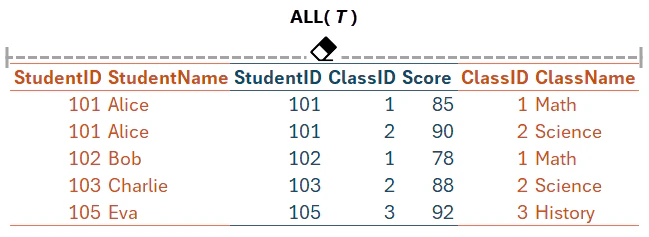
具体的に動作を観察するので、小さいセマンティック モデルを用意する。テーブルは Score, Student, Class。

次の組み合わせで One-to-Many / Single のリレーションシップが定義されている。
- Student[StudentID] (主キー) と Score[StdentID] (外部キー)
- Class[ClassID] (主キー) と Score[ClassID] (外部キー)
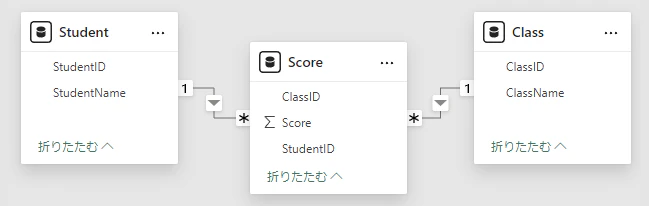
このセマンティック モデルの Score テーブルを評価するとき、次のような Expanded table として把握されているということである。
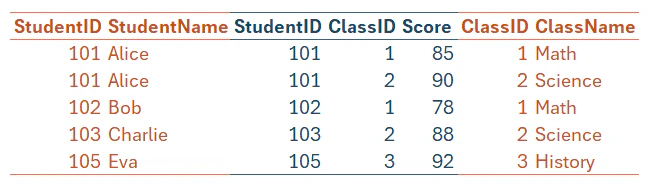
だったら、最初からひとつのテーブルにすればよいのでは?と感じるなら、Score テーブルに出現しない David はどうする?を先に考えたほうがよい。
DAX によるテーブルの評価
いくつかの DAX 関数でテーブルを評価し、その動作を確認する。
xmSQL(ストレージエンジンのクエリ)を追記しているのは、Expanded table が xmSQL の WHERE 句で説明可能と考えているから。ただし xmSQL を読むときには、常に GROUP BY されていることに注意。
RELATED 関数
RELATED 関数はテーブルを評価する関数ではないが、テーブルを評価する DAX 関数による行コンテキストで評価結果(1 側の列の値)を返す。
EVALUATE
SELECTCOLUMNS(
Score,
"Student name", RELATED( Student[StudentName] ),
"Class name", RELATED( Class[ClassName] )
)
SELECTCOLUMNS 関数のソーステーブル Score の Expanded table で、同じ行にある列の値を参照するだけ。


SET DC_KIND="AUTO";
SELECT
'Student'[StudentName],
'Class'[ClassName],
'Score'[RowNumber]
FROM 'Score'
LEFT OUTER JOIN 'Student'
ON 'Score'[StudentID]='Student'[StudentID]
LEFT OUTER JOIN 'Class'
ON 'Score'[ClassID]='Class'[ClassID];
| Clause | 説明 |
|---|---|
| FROM | ベーステーブル Score と Student テーブル, Class テーブルの JOIN |
| WHERE | なし |
| SELECT |
'Score'[RowNumber] は行の識別子列(内部利用のみ)したがって、Score テーブルすべての行 |
SUMMARIZE 関数
SUMMARIZE 関数で集計列を追加しないことを強くおススメし、テーブルからユニークな列の値、もしくは、ユニークな列の値の組み合わせが必要なときには使用する。
EVALUATE
CALCULATETABLE(
SUMMARIZE(
Score,
Class[ClassName]
),
Student[StudentName] = "Alice"
)
SUMMARIZE 関数のソーステーブル Score の Expanded table には Class[ClassName] 列, Student[StudentName] 列が含まれている。
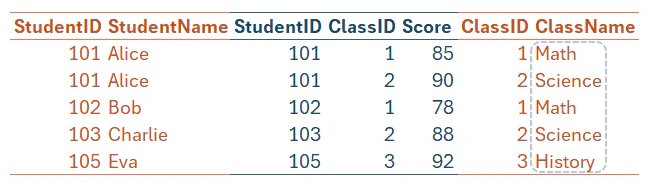
Student[StudentName] = "Alice" が含まれるフィルタ コンテキストでソーステーブル Score を評価した後、Class[ClassName] 列を集計する。

SET DC_KIND="AUTO";
SELECT
'Class'[ClassName]
FROM 'Score'
LEFT OUTER JOIN 'Student'
ON 'Score'[StudentID]='Student'[StudentID]
LEFT OUTER JOIN 'Class'
ON 'Score'[ClassID]='Class'[ClassID]
WHERE
'Student'[StudentName] = 'Alice';
| Clause | 説明 |
|---|---|
| FROM | ベーステーブル Score と Student テーブル, Class テーブルの JOIN |
| WHERE | 'Student'[StudentName] = 'Alice' |
| SELECT | 'Class'[ClassName] |
ALL 関数 / REMOVEFILTERS 関数
REMOVEFILTERS 関数ことフィルタ修飾関数としての ALL 関数は、評価結果のテーブルを返さないだけで本質的な動作は同じである。
まず比較として ネイティブなテーブル Score が評価される動作を確認する。
EVALUATE
CALCULATETABLE(
Score,
Student[StudentName] = "Alice"
)
ソーステーブル Score が評価されるとき、 Student テーブルと Class テーブルすべての列が含まれる Expanded table として認識される。
Expanded table の Student[StudentName] 列で Student[StudentName] = "Alice" のフィルタが適用されたテーブルから Score テーブルすべての列の射影になる。


SET DC_KIND="AUTO";
SELECT
'Score'[RowNumber],
'Score'[StudentID],
'Score'[ClassID],
'Score'[Score]
FROM 'Score'
LEFT OUTER JOIN 'Student'
ON 'Score'[StudentID]='Student'[StudentID]
WHERE
'Student'[StudentName] = 'Alice';
| Clause | 説明 |
|---|---|
| FROM | ベーステーブル Score と Student テーブル JOIN |
| WHERE | 'Student'[StudentName] = 'Alice' |
| SELECT | Score テーブルすべての列'Score'[RowNumber] (フィルタが適用されたScore テーブルすべての行 ) |
ALL( T )
テーブルを参照する ALL 関数の動作を確認する。
EVALUATE
CALCULATETABLE(
ALL( Score ),
Student[StudentName] = "Alice"
)
テーブルを引数にする ALL 関数は、Expanded table に対して適用されるフィルタを除外する。したがって、 CALCULATETABLE 関数によるフィルタ Student[StudentName] = "Alice" は上書き(無視)される。

SET DC_KIND="AUTO";
SELECT
'Score'[RowNumber],
'Score'[StudentID],
'Score'[ClassID],
'Score'[Score]
FROM 'Score';
| Clause | 説明 |
|---|---|
| FROM | ベーステーブル Score |
| WHERE | なし |
| SELECT | Score テーブルすべての列'Score'[RowNumber] ( Score テーブルすべての行 ) |
ALL( T ), REMOVEFILTERS( T ) の作用 (Expanded table)
ALL( T[C0] [, T[Cn], ...] )
テーブルの列を引数にする ALL 関数は、列ごとに適用されるフィルタを除外する。
EVALUATE
CALCULATETABLE(
ALL( Score[StudentID], Score[ClassID], Score[Score] ),
Student[StudentName] = "Alice"
)
テーブルの評価ではないので Expanded table を認識する必要がない。また、フィルタ コンテキストを操作するフィルタ式の列 Student[StudentName] は共通していない。したがって、CALCULATETABLE 関数によるフィルタ Student[StudentName] = "Alice" は無視される。


SET DC_KIND="AUTO";
SELECT
'Score'[StudentID],
'Score'[ClassID],
'Score'[Score]
FROM 'Score';
| Clause | 説明 |
|---|---|
| FROM | ベーステーブル Score |
| WHERE | なし |
| SELECT | Score テーブルすべての列 ただし、重複行は除外される |
CALCULATE 関数
CALCULATE 関数によるフィルタ コンテキストの操作で、どのようにフィルタが伝搬するかを確認する。ここでは、SUMX 関数を使用する DAX 式を CALCULATE 関数の filter 引数に示されるフィルタ コンテキストで評価する。
EVALUATE
ROW(
"Sum of Score",
CALCULATE(
SUMX(
Score,
Score[Score]
),
Student[StudentName] = "Alice"
)
)
SUMX 関数 もしくは SUM 関数は、ソーステーブルの行ごとに評価を繰り返し(行コンテキスト)、列の値の算術和を得る。

SUMX 関数の table 引数 Score テーブルの評価には、Expanded table に含まれる Student テーブルの列を用いてフィルタが適用される。


SET DC_KIND="AUTO";
SELECT
SUM ( 'Score'[Score] )
FROM 'Score'
LEFT OUTER JOIN 'Student'
ON 'Score'[StudentID]='Student'[StudentID]
WHERE
'Student'[StudentName] = 'Alice';
| Clause | 説明 |
|---|---|
| FROM | ベーステーブル Score と Student テーブルの JOIN |
| WHERE | 'Student'[StudentName] = 'Alice' |
| SELECT | SUM(Score[Score]) |
Expanded table と フィルタ コンテキスト
CALCULATE 関数でフィルタ コンテキストを操作するときの Expanded table の作用を把握しておく。多く利用される SUMMARIZECOLUMNS 関数を用いて具体的な動作の説明を試みる。
フィルタ修飾関数 (Filter modification functions)
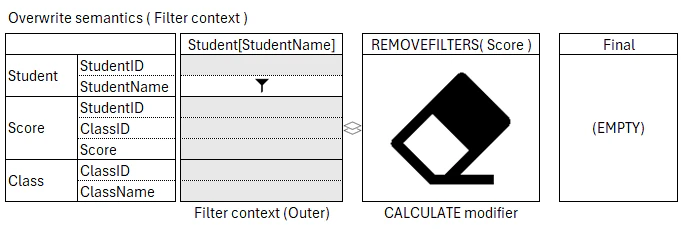
CALCULATE 関数のフィルタ修飾関数は、複製された CALCULATE 関数の外側のフィルタ コンテキストに対し、filter 引数の評価より前に適用される。
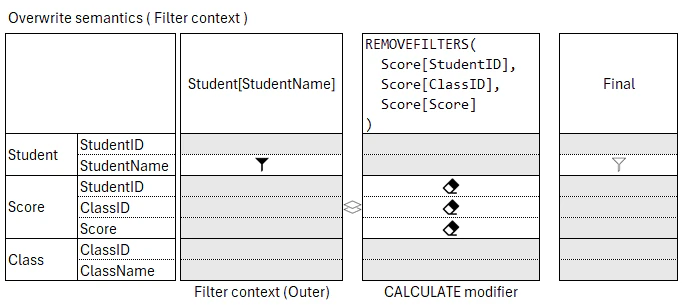
REMOVEFILTERS( T )
EVALUATE
SUMMARIZECOLUMNS(
Student[StudentName],
"REMOVEFILTERS_Table",
CALCULATE(
[<measure>],
REMOVEFILTERS( Score )
)
)
この DAX クエリで <measure> が評価されるとき、複製された Student[StudentName] の列フィルタを含むフィルタ コンテキストから Score テーブルの Expanded table でフィルタを除外する。したがって、このメジャーはすべての行で同じ値を返す。
REMOVEFILTERS( T[C0] [, T[Cn], ...] )
EVALUATE
SUMMARIZECOLUMNS(
Student[StudentName],
"REMOVEFILTERS_Columns",
CALCULATE(
[<measure>],
REMOVEFILTERS(
Score[StudentID],
Score[ClassID],
Score[Scoree]
)
)
)
複製された Student[StudentName] の列フィルタを含むフィルタ コンテキストからフィルタを除外するが、REMOVEFILTERS( T ) ではないので Expanded table ではない。結果として、Student[StudentName] の列フィルタは除外されない。
フィルタ式 (setfilter)
ブーリアン フィルタ式 (Boolean filter expressions)
CALCULATE 関数の filter 引数に FILTER 関数を使用しないというベストプラクティスである。
EVALUATE
SUMMARIZECOLUMNS(
Student[StudentName],
"Boolean_filter",
CALCULATE(
[<measure>],
Score[Score] > 0
)
)
Boolean filter expressions は糖衣構文として用意されていて、このメジャーでは FILTER( ALL( Score[Score] ), Score[Score] > 0 ) として認識される。

テーブル フィルタ式 (Table filter expressions)
CALCULATE 関数の filter 引数に定義するフィルタ式は本質的にテーブルであるから、テーブル フィルタ式 (Table filter expression) であっても、意図する通りにフィルタ コンテキストの操作は可能である。ただし、常に評価パフォーマンスが低下するので、列フィルタが適用されるブーリアン フィルタ式 (Boolean filter expression) を最優先で選択すべきだ。
EVALUATE
SUMMARIZECOLUMNS(
Student[StudentName],
"Table_filter",
CALCULATE(
[<measure>],
FILTER(
Score,
Score[Score] > 0
)
)
)
CALCULATE 関数の filter 引数で参照している Score テーブルは Expanded table で評価される。Student[StudentName] の列フィルタを含むフィルタ コンテキストで評価された後、Score[Score] > 0 のフィルタが追加される。ここで問題になるのは、<measure> を評価するフィルタ コンテキストが大きすぎる傾向にあるということだ。列と行が多い大きいフィルタテーブルを使用することになる。加法メジャーやシンプルなフィルタ式であれば、わずかなパフォーマンス低下で済んでしまうので、やらかしていることに気づいていないケースが多い。

思ったこと🙄
FILTER 関数 と ALL 関数は、
- シンプルな動作をするから理解しやすいのでしょう
- シンプルに説明できるので教えやすいのでしょう
ただし、DAX 計算エンジンの基礎を支える関数でもあるので、その作用は強力で影響範囲も広いという認識が必要だ。
CALCULATE 関数の filter 引数に FILTER 関数を使用しないというベストプラクティスは、可能な限り Boolean filter expressions という糖衣構文で記述するといいよということなのだけど、なぜ糖衣構文が提供されたのかを考えることがある。FILTER 関数、ALL 関数を完全に理解することが難しすぎるからだと思う。
その他
createOrReplace
ref model Model
table Student
column StudentID
isKey
dataType: int64
formatString: 0
summarizeBy: none
sourceColumn: [StudentID]
column StudentName
dataType: string
summarizeBy: none
sourceColumn: [StudentName]
partition Student = calculated
mode: import
source =
DATATABLE(
"StudentID", INTEGER, "StudentName", STRING,
{
{ 101, "Alice" },
{ 102, "Bob" },
{ 103, "Charlie" },
{ 104, "David" },
{ 105, "Eva" }
}
)
table Class
column ClassID
isKey
dataType: int64
formatString: 0
summarizeBy: none
sourceColumn: [ClassID]
column ClassName
dataType: string
summarizeBy: none
sourceColumn: [ClassName]
partition Class = calculated
mode: import
source =
DATATABLE(
"ClassID", INTEGER, "ClassName", STRING,
{
{ 1, "Math" },
{ 2, "Science" },
{ 3, "History" },
{ 4, "IT" }
}
)
table Score
column StudentID
dataType: int64
formatString: 0
summarizeBy: none
sourceColumn: [StudentID]
column ClassID
dataType: int64
formatString: 0
summarizeBy: none
sourceColumn: [ClassID]
column Score
dataType: int64
formatString: 0
summarizeBy: none
sourceColumn: [Score]
partition Score = calculated
mode: import
source =
DATATABLE(
"StudentID", INTEGER, "ClassID", INTEGER, "Score", INTEGER,
{
{ 101, 1, 85 },
{ 101, 2, 90 },
{ 102, 1, 78 },
{ 103, 2, 88 },
{ 105, 3, 92 }
}
)
relationship ScoreToClass
fromColumn: Score.ClassID
toColumn: Class.ClassID
relationship ScoreToStudent
fromColumn: Score.StudentID
toColumn: Student.StudentID