Power BI に限らずなんだけどお仕事のレポートを作成するとき、日付とか月とか年とか期間単位で集計することって多いじゃないですか。よく使う集計なので、Power BI (Power Pivot for Excel / SSAS も同じですよ) には "タイム インテリジェンス関数" が用意されているのである。
時系列の集計にはタイム インテリジェンス関数を使わなければいけないということではない。標準的な日付システム(グレゴリオ暦)で集計ならタイム インテリジェンス関数を使った方が楽でしょってこと。で、さまざまなタイム インテリジェンス関数が用意されているのだけど、そのツカイカタおかしくない?ってことがまぁ存外にあるのです。
Dates = CALENDAR( FIRSTDATE( Sales[受注日] ), LASTDATE( Sales[受注日] ) )
タイム インテリジェンス関数を使いますよ。と、なったとき"日付テーブル"が必要になるのだけど、このような定義をされるケースがある。ここにはよろしくないポイントがふたつ含まれている。
1月1日から12月31日までの年間通したすべて日付が含まれない可能性があるんじゃね?
CALENDAR 関数は、最初と最後の日付を引数として渡すと連続した日付列(Date)を持つテーブルを返すからなんとなくよさそうな気がしてしまう。だけど、タイム インテリジェンス関数で利用する日付テーブルには、年間通した日付(1/1~12/31) が必要なのだ。タイム インテリジェンス関数がエラーを返すとまでは至らないまでも、期待する結果を返せないということがあるわけ。
"タイム インテリジェンス関数"と"日付と時刻の関数"がごっちゃになってね?
関数名からどんな結果を得られるのかを類推しているのかもしれないけど、タイム インテリジェンス関数は "日付時刻"値を操作する関数ではない。すべての datetime 列を対象とするものでもない。
Dates =
VAR FirstYear = YEAR( MIN( Sales[受注日] ) )
VAR LastYear = YEAR( MAX( Sales[受注日] ) )
RETURN
FILTER(
CALENDARAUTO(),
YEAR( [Date] ) >= FirstYear && YEAR( [Date] ) <= LastYear
)
守ることはさほどない
が、ベストやベターはない。苦労をしたくないから厳守。
ファクトテーブルの datetime 列 を引数として使用してはいけない
タイム インテリジェンス関数の引数 <dates> は、日付テーブルのキーもしくはキーになりえる datetime 列 であること。前提だし、そもそもそのように作られているのだから守らない理由はない。
たとえば、 FIRSTDATE( Sales[受注日] ) / LASTDATE( Sales[受注日] ) で思ってた通りの結果が得られることが たまたま あるのだけど、FIRSTDATE 関数 /LASTDATE 関数は table を返す関数ですしね。前項よろしくないと思う例で結果が得られていることを不思議に思うべきだし、得られる結果とパフォーマンスについて検討することが多い関数をわざわざ選択しているので残念なお気持ちである。
日付テーブルが必要だ
タイム インテリジェンス関数は日付テーブルとともに使用する関数だから。日付テーブルはディメンジョンテーブルのひとつだから、タイム インテリジェンス関数を使用しなくても日付にまつわる集計をするのであれば、日付テーブルは必要である。多くの場合、日付テーブルはひとつで事足りるはずなんだけど、データモデルが指し示すことにもよるという感じでよいはず。
Power BI Desktop の設定は調整したほうがよい
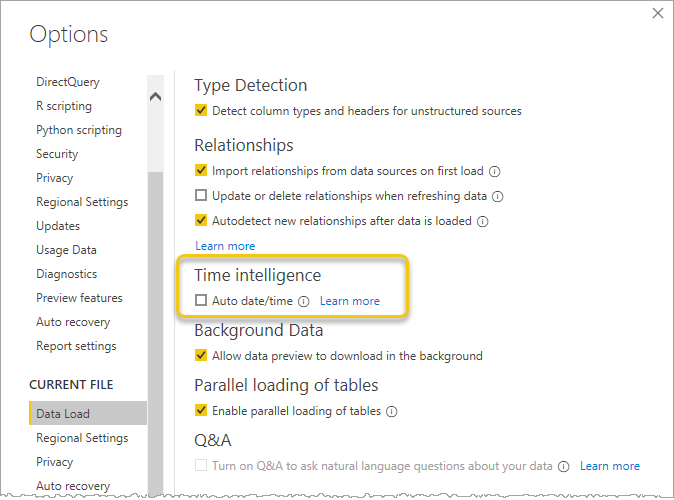
Auto date/ time っていうPower BI Desktop の機能なんだけど、デフォルトで使用しない設定にしておいた方がよい。
日付テーブルが自動で生成されることがちょうどよい場面はあるのだけど、まずはモデル内のすべての datetime 列に対し日付テーブルを用意する仕様なので無駄になることが多い。フォーマットの変更とかできませんし。なので、
グローバル設定で機能を使用しないにして
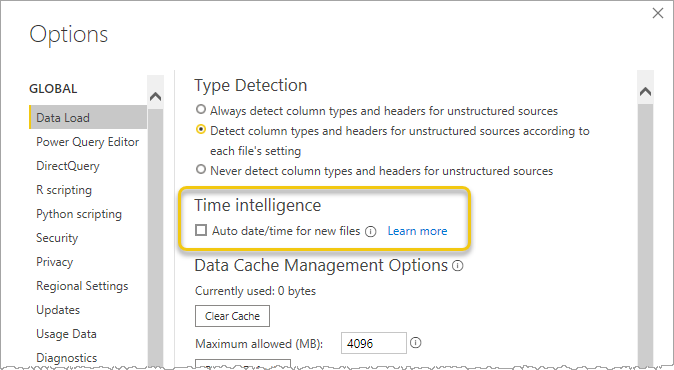
必要であれば、ファイルごとで機能を有効化する。
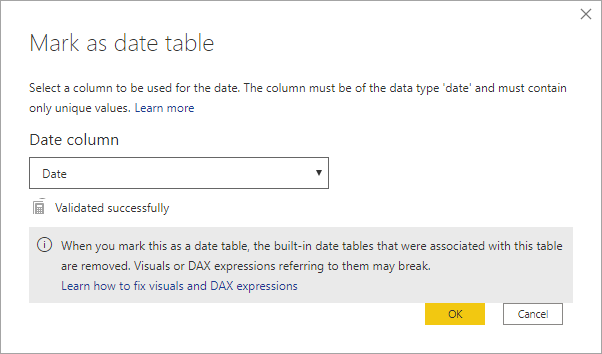
日付テーブルを用意したら Mark as date table
これはやっておいた方がよい。
引数 <dates> とは
日付テーブルのキー、もしくは、等価の datetime 列 を列指定することが多いのだけど、
- A reference to a date/time column.
- A table expression that returns a single column of date/time values.
- A Boolean expression that defines a single-column table of date/time values.
と、なっていて、CALCULATE 関数の <filter> 引数と同じなのだ。
| Date |
|---|
| 2020-01-01 |
| 2020-02-02 |
| ... |
| 2020-12-30 |
| 2020-1231 |
| という日付テーブル(Dates)があるとき、 |
LASTDATE( Dates[Date] )
は、
| Date |
|---|
| 2020-12-31 |
| という、1行1列のテーブルを返す。列参照しているように見えて内部的には、CALCULATETABLE( DISTINCT( Dates[Date] ) ) なのである。そして テーブル式でもよい。 |
LASTDATE(
CALCULATETABLE(
VALUES( Dates[Date] ),
Dates[Date] < DATE( 2020, 10, 1 )
)
)
は、
| Date |
|---|
| 2020-09-30 |
| という、1行1列のテーブルを返す。そして、 |
LASTDATE( Dates[Date] < DATE( 2020, 10, 1 ) )
は、
| Date |
|---|
| 2020-09-30 |
| という、1行1列のテーブルを返す |
なお、DATESBETWEEN 関数 / DATESINPERIOD 関数 の <dates> 引数は完全な列参照。
Context transition が起こりえますよ
DATESINPERIOD関数 / DATESBETWEEN 関数以外のタイム インテリジェンス関数は コンテキストトランジションが動作することがある。関数で得られる効果をぼんやりと覚えているだけだと、思ってもないことが起きるということだし、なぜこうなる?ということがわからないのだ。
具体的に
たとえば、各ピリオド最終日の集計をしたいとして、LASTDATE 関数を使った。LASTDATE 関数は Dates[Date] 列 のうち、もっとも新しいの値(日付時刻値) を含む テーブルを返す関数である。
EVALUATE
SUMMARIZECOLUMNS(
Dates[Year], Dates[Month],
"SalesAmount",
CALCULATE(
[受注額],
FILTER(
ALL( Dates[Date] ),
Dates[Date] = LASTDATE( Dates[Date] )
)
)
)
と記述すると、メジャー[受注額] はすべての行で同じ値が返されるのである。日付と時間の関数ではないのだから、そもそもこうでしょ。
EVALUATE
SUMMARIZECOLUMNS(
Dates[Year], Dates[Month],
"SalesAmoun",
CALCULATE(
[受注額],
LASTDATE( Dates[Date] )
)
)
EVALUATE
SUMMARIZECOLUMNS(
Dates[Year], Dates[Month],
"SalesAmoun",
CALCULATE(
[受注額],
FILTER(
ALL( Dates[Date] ),
Dates[Date] = MAX( Dates[Date] )
)
)
)
とはいえ、フィルタ式の部分に注目して何が起きていたのか。
FILTER(
ALL( Dates[Date] ),
Dates[Date] = LASTDATE( Dates[Date] )
)
FILTER 関数のひとつめの引数は <table> でイテレータ。ふたつめの引数が<table>の行ごとに評価される式になり行コンテキストで評価されるのです。FILTER 関数はテーブルから行を絞り込むのだから、行ごとに評価が必要なのは当然だ。
で、タイム インテリジェンス関数の <dates> 引数は
CALCULATETABLE( DISTINCT( Dates[Date] ) )
であるから、
FILTER(
ALL( Dates[Date] ),
Dates[Date] = LASTDATE( CALCULATETABLE( DISTINCT( Dates[Date] ) ) )
)
記述を変更しても依然として結果は変わらない。ここでどのようなことが起きているのか考えるとよい。
Dates[Date] の値セットから順々に <filter>に渡されていくので DISTINCT( Dates[Date] ) は 現在の Dates[Date] と一致し、<filter>の評価は常に true に。で、この FILTER 関数では、すべての Dates[Date] が対象となってしまうのだ。
CALCULATE / CALCULATETABLE は、現在のフィルタコンテキストから新しいフィルタコンテストを作成し適用するのだけど、LASTDATE 関数内部の CALCULATETABLE 関数に<filter> が指定されていないから、現在の評価コンテキスト変更せずそのまま適用する。ここでは、FILTER 関数による 行コンテキストが作用しているので、これをフィルタコンテキストに変換し、DISTINCT( Dates[Date] ) を評価しているってことだ。で、少しおかしなことをしてみる。
EVALUATE
SUMMARIZECOLUMNS(
Dates[Year], Dates[Month],
"SalesAmount",
CALCULATE(
[受注額],
FILTER(
ALL( Dates[Date] ),
Dates[Date] = LASTDATE(
CALCULATETABLE(
DISTINCT( Dates[Date] ),
DISTINCT( Dates[Date] ) //🤩
)
)
)
)
)
ふたつめの DISTINCT( Dates[date] ) は、Dates[Year] / Dates[Month] に関連するフィルタコンテキストで評価されているから、単一の日付となっている DISTINCT( Dates[Date] ) を強制的に戻したって感じ。期待する集計結果はを得ることはできるけどマネスンナ。
そもそも、タイム インテリジェンス 関数が意味することを理解しておけばよいのだけど、得られる効果だけ丸暗記は絶対ダメってことだ。
関数ごとに
基本的なものだけ
- 評価結果は日付テーブルの範囲にとどまる。日付テーブルに定義されていない日付を得ることはできない。
FIRSTDATE 関数 / LASTDATE 関数
datetime値を変換する関数ではないのだぜ。
現在のフィルタコンテキストで評価された <dates> 列のうち、
FIRSTDATE 関数
もっとも古い<dates>の値を持つ 1行1列のテーブルが返る
LASTDATE 関数
もっとも新しい<dates>の値を持つ 1行1列のテーブルが返る
CALCULATE(
<measure>,
LASTDATE( <date_column> )
)
っていう感じで使えばよいのだけど、すこし複雑な <filter> になるなら、MAX 関数 / MIN 関数を使った方がよいし、日付テーブル以外の datetime 列 ならば、MAX 関数 / MIN 関数 である。
CALCULATE(
<measure>,
FILTER(
ALL( <date_column> ),
<date_column> = MAX( <date_column> )
)
DATEADD 関数 / SAMEPERIODLASTYEAR 関数 / PARALLELPERIOD 関数
DATEADD 関数
現在のフィルタコンテキストで評価された <dates> 列を<interval> で <number_of_intervals> 分スライドさせた 1列のテーブルを返す。ただし、<dates> は連続した値が必要でギャップがあるとエラーになる。
<interval> が 'Month' の時、大の月 / 小の月 の末日がどのように処理されるかがポイント。
DATEADD(
YEAR( Dates[Date] ) = 2020
&& MONTH( Dates[Date] ) = 9,
-7,
MONTH
)
| Date |
|---|
| 2020-02-01 |
| 2020-02-02 |
| ... |
| 2020-02-28 |
| 2020-02-29 |
DATEADD(
Dates[Date]
= DATE( 2020, 10, 30 ),
-1,
MONTH
)
| Date |
|---|
| 2020-09-30 |
DATEADD(
Dates[Date]
= DATE( 2020, 10, 31 ),
-1,
MONTH
)
| Date |
|---|
| 2020-09-30 |
DATEADD(
Dates[Date]
IN {
DATE( 2020, 9, 30 ),
DATE( 2020, 10, 1 )
},
-1,
MONTH
)
| Date |
|---|
| 2020-08-30 |
| 2020-08-31 |
| 2020-09-01 |
DATEADD(
Dates[Date]
IN {
DATE( 2020, 9, 30 ),
DATE( 2020, 10, 1 )
},
1,
MONTH
)
| Date |
|---|
| 2020-10-30 |
| 2020-10-31 |
| 2020-11-01 |
DATEADD(
Dates[Date]
IN {
DATE( 2020, 10, 30 ),
DATE( 2020, 10, 31 ),
DATE( 2020, 11, 1 )
},
-1,
MONTH
)
| Date |
|---|
| 2020-09-30 |
| 2020-10-01 |
EVALUATE
DATEADD(
Dates[Date]
IN {
DATE( 2020, 10, 30 ),
// DATE( 2020, 10, 31 ),
DATE( 2020, 11, 1 )
},
-1,
MONTH
)
Function 'DATEADD' expects a contiguous selection when the date column is not unique, has gaps or it contains time portion.
Mark as date table でバリデーションが済んでいるから、ほとんどの場合で問題は起きない。しかし、フィルタコンテキストでギャップが発生することがあるのだ。
SAMEPERIODLASTYEAR 関数
DATEADD( Dates[Date], -1, Year ) のショートハンド
PARALLELPERIOD 関数
DATEADD 関数 と違うところは、 現在のフィルタコンテキストで評価された <dates> を<interval> で <number_of_intervals> 分スライドさせるのでなく、スライドした <dates> を含む <interval> のすべての範囲の日付を含む 1列のテーブルが返る。
PARALLELPERIOD(
Dates[Date]
= DATE( 2020, 9, 25 ),
-1,
MONTH
)
| Date |
|---|
| 2020-08-01 |
| 2020-08-02 |
| ... |
| 2020-08-30 |
| 2020-08-31 |
PARALLELPERIOD(
Dates[Date]
IN {
DATE( 2020, 9, 25 ),
DATE( 2020, 10, 5 )
},
-1,
MONTH
)
| Date |
|---|
| 2020-08-01 |
| 2020-08-02 |
| ... |
| 2020-09-29 |
| 2020-09-30 |
PARALLELPERIOD(
Dates[Date]
IN {
DATE( 2020, 9, 25 ),
DATE( 2020, 10, 5 )
},
1,
MONTH
)
| Date |
|---|
| 2020-10-01 |
| 2020-10-02 |
| ... |
| 2020-11-29 |
| 2020-11-30 |
PARALLELPERIOD(
Dates[Date]
IN {
DATE( 2020, 9, 25 ),
DATE( 2020, 10, 5 )
},
-1,
QUARTER
)
| Date |
|---|
| 2020-04-01 |
| 2020-04-02 |
| ... |
| 2020-09-29 |
| 2020-09-30 |
PARALLELPERIOD(
Dates[Date]
IN {
DATE( 2020, 9, 25 ),
DATE( 2020, 10, 5 )
},
1,
QUARTER
)
| Date |
|---|
| 2020-10-01 |
| 2020-10-02 |
| ... |
| 2021-03-30 |
| 2021-03-31 |
PARALLELPERIOD(
Dates[Date]
IN {
DATE( 2020, 9, 25 ),
DATE( 2021, 1, 5 )
},
-1,
YEAR
)
| Date |
|---|
| 2019-01-01 |
| 2019-01-02 |
| ... |
| 2020-12-30 |
| 2020-12-31 |
PARALLELPERIOD(
Dates[Date]
IN {
DATE( 2019, 9, 25 ),
DATE( 2020, 1, 5 )
},
1,
YEAR
)
| Date |
|---|
| 2020-01-01 |
| 2020-01-02 |
| ... |
| 2021-12-30 |
| 2021-12-31 |
PREVIOUSDAY 関数 / NEXTDAY 関数
FIRSTDATE 関数 / LASTDATE 関数 同様、1行1列のテーブルが返る関数。なので、変換する関数と間違えられることがおおいのだろうか。
現在のフィルタコンテキストで評価された <dates> 列のうち、
PREVIOUSDAY 関数
もっとも古い<dates>の値の前日の値を持つ 1行1列のテーブルが返る
NEXTDAY 関数
もっとも新しい<dates>の値の翌日の値を持つ 1行1列のテーブルが返る
CALCULATETABLE(
ROW(
"PREVIOUSDAY", PREVIOUSDAY( Dates[Date] ),
"NEXTDAY", NEXTDAY( Dates[Date] )
),
FILTER(
ALL( Dates[Year], Dates[Month] ),
Dates[Year] = 2020
&& Dates[Month] = 9
)
)
| PREVIOUSDAY | NEXTDAY |
|---|---|
| 2020-08-31 | 2020-10-01 |
PREVIOUSMONTH 関数 / NEXTMONTH 関数
現在のフィルタコンテキストで評価された <dates> 列のうち、
PREVIOUSMONTH 関数
もっとも古い<dates>の値の前月すべて値を持つ 1列のテーブルが返る
NEXTMONTH 関数
もっとも新しい<dates>の値の翌月すべての値を持つ 1列のテーブルが返る
PREVIOUSMONTH(
Dates[Date]
IN {
DATE( 2020, 8, 31 ),
DATE( 2020, 9, 1 )
}
)
| Date |
|---|
| 2020-07-01 |
| 2020-07-02 |
| ... |
| 2020-07-30 |
| 2020-07-31 |
NEXTMONTH(
Dates[Date]
IN {
DATE( 2020, 8, 31 ),
DATE( 2020, 9, 1 )
}
)
| Date |
|---|
| 2020-10-01 |
| 2020-10-02 |
| ... |
| 2020-10-29 |
| 2020-10-30 |
PREVIOUSQUARTER 関数 / NEXTQUARTER 関数
四半期は 1~3 / 4~6 / 7~9 / 10~12
現在のフィルタコンテキストで評価された <dates> 列のうち、
PREVIOUSQUARTER 関数
もっとも古い<dates>の値の前四半期すべて値を持つ 1列のテーブルが返る
NEXTQUARTER 関数
もっとも新しい<dates>の値の翌四半期すべての値を持つ 1列のテーブルが返る
PREVIOUSQUARTER(
Dates[Date]
IN {
DATE( 2020, 8, 1 ),
DATE( 2020, 10, 1 )
}
)
| Date |
|---|
| 2020-04-01 |
| 2020-04-02 |
| ... |
| 2020-06-29 |
| 2020-06-30 |
NEXTQUARTER(
Dates[Date]
IN {
DATE( 2020, 8, 1 ),
DATE( 2020, 10, 1 )
}
)
| Date |
|---|
| 2021-01-01 |
| 2021-01-02 |
| ... |
| 2021-03-30 |
| 2021-03-31 |
PREVIOUSYEAR 関数 / NEXTYEAR 関数
現在のフィルタコンテキストで評価された <dates> 列のうち、
PREVIOUSYEAR 関数
もっとも古い<dates>の値の前年すべて値を持つ 1列のテーブルが返る
NEXTYEAR 関数
もっとも新しい<dates>の値の翌年すべての値を持つ 1列のテーブルが返る
PREVIOUSYEAR(
Dates[Date]
IN {
DATE( 2020, 12, 31 ),
DATE( 2021, 1, 1 )
}
)
| Date |
|---|
| 2019-01-01 |
| 2019-01-02 |
| ... |
| 2019-12-30 |
| 2019-12-31 |
NEXTYEAR(
Dates[Date]
IN {
DATE( 2020, 12, 31 ),
DATE( 2021, 1, 1 )
}
)
| Date |
|---|
| 2022-01-01 |
| 2022-01-02 |
| ... |
| 2022-12-30 |
| 2022-12-31 |
STARTOFMONTH 関数 / ENDOFMONTH 関数
現在のフィルタコンテキストで評価された <dates> 列のうち、
STARTOFMONTH 関数
もっとも古い<dates>の値を含む月の1日持つ 1行1列のテーブルが返る
ENDOFMONTH 関数
もっとも新しい<dates>の値を含む月の末日持つ 1行1列のテーブルが返る
CALCULATETABLE(
ROW(
"STARTOFMONTH", STARTOFMONTH( Dates[Date] ),
"ENDOFMONTH", ENDOFMONTH( Dates[Date] )
),
Dates[Date]
IN {
DATE( 2020, 9, 15 ),
DATE( 2020, 10, 15 )
}
)
| STARTOFMONTH | ENDOFMONTH |
|---|---|
| 2020-09-01 | 2020-10-31 |
STARTOFQUARTER 関数 / ENDOFQUARTER 関数
現在のフィルタコンテキストで評価された <dates> 列のうち、
STARTOFQUARTER 関数
もっとも古い<dates>の値を含むの四半期の初日を持つ 1行1列のテーブルが返る
ENDOFQUARTER 関数
もっとも新しい<dates>の値を含む四半期の最終日を持つ 1行1列のテーブルが返る
CALCULATETABLE(
ROW(
"STARTOFQUARTER", STARTOFQUARTER( Dates[Date] ),
"ENDOFQUARTER", ENDOFQUARTER( Dates[Date] )
),
Dates[Date]
IN {
DATE( 2020, 9, 15 ),
DATE( 2020, 10, 15 )
}
)
| STARTOFQUARTER | ENDOFQUARTER |
|---|---|
| 2020-07-01 | 2020-12-31 |
STARTOFYEAR 関数 / ENDOFYEAR 関数
現在のフィルタコンテキストで評価された <dates> 列のうち、
STARTOFQUARTER 関数
もっとも古い<dates>の値を含むの年の初日を持つ 1行1列のテーブルが返る
ENDOFQUARTER 関数
もっとも新しい<dates>の値を含む年の最終日を持つ 1行1列のテーブルが返る
CALCULATETABLE(
ROW(
"STARTOFYEAR", STARTOFYEAR( Dates[Date] ),
"ENDOFYEAR", ENDOFYEAR( Dates[Date] )
),
Dates[Date]
IN {
DATE( 2020, 12, 31 ),
DATE( 2021, 1, 1 )
}
)
| STARTOFYEAR | ENDOFYEAR |
|---|---|
| 2020-01-01 | 2021-12-31 |
思ったこと🙄
関数の組合せだけでなんとかなるということはとても少ない。
DAX 関数を含む式がどのように評価されるのかが重要だし、DAX関数がどのような動作をするのか、もう一歩理解を深める必要があるねと思うのです。
タイム インテリジェンス関数 を使わないで同様の結果を得るにはどうしたらよいか?とかとても勉強になるですよね。