メジャーをイイ感じに記述できるようになりたいなと勉強始めたところならスタート地点から考えた方がいい。理解を深めるのが大変だって思ったらスタート地点から考えなおしたがいい。DAX 難しいって言ってるひとの多くは基本をないがしろにしがちで How-to ばかりに注目しているような気がするのである。なぜ、原理原則に近いところから始めずに、難しいところから勉強を始めるのか。ほんと不思議なのだ。
ベストプラクティスや基礎をよく理解しようぜ
お仕事上で様々なレポートを見せていただいたり、どうしたらイイ感じになるのかなどサポートしていて思うことは、メジャーの記述に問題があることが多いようなのだ。勉強不足であるだけならもっと勉強をしたらよいのでは?で済むのだけど、多くの場合で同じ過ちをしているんだよね。問題があるコードってとても強い既視感があるんだよね😏なぜかなぁ🙄もしかして コピペ?🤩
How-to を参考にするのは重要な勉強方法
であり、お手軽であるのだろうけど、基礎であったりベストプラクティスを理解した上で参考にさせてもらった方がよいのでは?と思うのです。基礎的な知識なく応用に進んでも、それが正しいのか/ベストなのか/適しているのかすらわからないですよね。
行き当たりばったりな勉強は無策なリソース消費なのでは?
勉強する時間を捻出するのはとても大変だよね。なので行き当たりばったりな勉強をすべきではないなと思うのです。
メジャーはモデルに込められたロジックをもとに計算される DAX で記述される式なのだけど、○○を集計する方法っていうのは応用要素が多く含まれているし、例えばそのコードを眺めていてもさ、"この記述部分は何をしてるのかな?"ってわからないよね。提示されている内容が必要としているものすらわからないし、期待する結果やパフォーマンスを得られるか判断してるのでしょうね。
見取り稽古だけでできるようになるのは特別な才能を持っているからだと思うのだ。
CALCULATE 関数のベストプラクティス
DAX で最も重要で最も使う関数が CALCULATE 関数。よって、失敗することが多い関数なのだ。
FILTER 関数 じゃなくて CALCULATE 関数
これは以前にポストしたのだけど、
CALCULATE 関数 使わずに FILTER 関数 を多用してよろしくないメジャーを記述していることが多いのだ。たとえば、累計を求めたいとして
SUMX(
FILTER(
ALL( Sales ),
Sales[受注日] <= MAX( Dates[Date] )
),
Sales[単価] * Sales[数量]
)
CALCULATE(
SUMX(
Sales,
Sales[単価] * Sales[数量]
),
Dates[Date] <= MAX( Dates[Date] ) // 集計関数の使用についてはあとで説明
)
使い勝手が悪いどころかパフォーマンスも非常によくないのだ。だから、CALCULATE 関数をきちんと使えるようにしましょうねってこと。加えて、難しいところから始めずに 基礎やベストプラクティスから始めようねって話。
CALCULATE 関数 filter 引数のベストプラクティス
構文から整理する基礎
CALCULATE(
<expression>
, <filter1>
, <filter2>
, ...
)
- CALCULATE 関数で新たに生成されたフィルタコンテキストで expression が評価される。
- 新たに生成される フィルタコンテキストは expression に続く filter 引数で定義する。
- 複数の filter 引数を定義した時、それぞれ評価に利用するフィルタはすべて考慮される。
- 同じ列を含むフィルタの場合は交差
- 異なる列に対するフィルタの場合も交差だけど、追加と同義
-
filter 引数で定義できるのは、Boolean 式、Table 式、Filter modification 関数
- いずれも本質的には table である
CALCULATE(
SUM( Sales[数量] ),
Products[区分名] = "飲料"
)
CALCULATE(
SUM( Sales[数量] ),
Products[区分名] = "飲料",
Products[単価] = 100
)
CALCULATE(
SUM( Sales[数量] ),
Products[区分名] = "飲料",
Products[区分名] = "魚介類"
)
そのほか、CALCULATE 関数の動作を変更する REMOVEFILTERS 関数 や USERELATIONSHIP 関数 などはこのポストでは触れないけれども、filter 引数 で定義したフィルタとメジャー外部から適用されるフィルタとの既定の合成動作(無視 / Orverride)を変更(交差 / Intercection )する KEEPFILTERS 関数だけ取り上げる。
ベストプラクティスを知る
DOCSにも存在するのだけど、これ、タイトルがよくないよね。
CALCULATE / CALCULATETABLE 関数の filter 引数 には、FILTER 関数を使わない。
と、いうベストプラクティスだ。
加えて、2021年3月と9月のアップデートで、CALCULATE 関数の filter 引数 の記述に使用できる糖衣構文/Syntax suger が拡張されている。
追加された糖衣構文 3月
同じテーブルに存在する列であれば、ひとつの filter 引数で定義することができるようになった。
CALCULATE(
SUM( Sales[数量] ),
Products[区分名] = "飲料"
|| Products[単価] = 100
)
このメジャーでえられる結果は、Products[区分名] = "飲料" もしくは Products[単価] = 100 だから、飲料の商品すべて と 単価が100の商品すべて の和集合が対象となる。
ただし、"OR"( || ) ではなく "AND" ( && ) となるときは、
CALCULATE(
SUM( Sales[数量] ),
Products[区分名] = "飲料"
&& Products[単価] = 100
)
ではなく、
CALCULATE(
SUM( Sales[数量] ),
Products[区分名] = "飲料",
Products[単価] = 100
)
と記述したほうがよりよい。
ひとつのテーブルに含まれる列であれば、
CALCULATE(
[受注額],
Sales[数量] * Sales[単価] >= 20000
)
ということも可能になった。
追加された糖衣構文 9月
集計関数を使った filter 引数の糖衣構文が利用できるようになった。
CALCULATE(
SUM( Sales[数量] ),
Sales[数量] = MAX( Sales[数量] )
)
メジャーの記述を眺めているだけではいったいぜんたい何のことやらだから、ビジュアルに配置して確認するとよい。
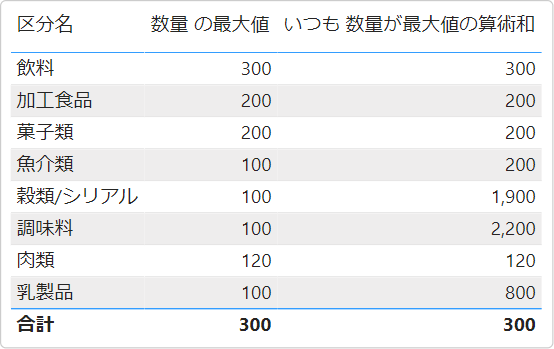
filter 引数の MAX( Sales[数量] ) は Sales テーブルの列 [数量]の最大値を返す。このビジュアルでは、テーブル各行ごとに 区分名へのフィルタが適用されるから、商品区分ごとの[数量]の最大値だ。"飲料"の行では、[数量]の最大値 が 300 で、[数量]が300 という条件にマッチする行が1行 300。"乳製品"の行では、[数量]の最大値 が 100、[数量]が100 という条件にマッチする行が 8行 100 + 100 + 100 + 100 + 100 + 100 + 100 + 100 = 800 ということ。
大事なこと
糖衣構文の拡張までひっくるめると、**CALCULATE 関数の filter 引数 は、True / False を返す Boolean 式で記述する。**これにつきる。シンプルに記述できるようになっているのだから、わざわざ難しく記述する必要はないよねと。
-
**もし勉強始めたばかりというなら、**このルールは簡単でしょ。簡単なところから始めるとよいのです。FILTER 関数をつかった複雑なフィルタはもう少しあとでも十分なはずだし、基礎を忠実に反復するという勉強が大事なのです。
-
**もし勉強始めたばかりではないというなら、**なぜこのルールがベストプラクティスなのかよーく勉強してみてください。FILTER 関数を多用したときのサイドエフェクトまで勉強してねと思う。記述したメジャーのオプティマイズやチューニングを検討しなければならないことがいずれあるでしょう。その結果がよいのか、もしくは、そうでないかの基準になるはずだから、基礎をないがしろにしないでねと。
-
**もっともよくないのは、**充分な理解のないままの状態でベストプラクティスにないことやトリッキーな手法を利用することだ。
ベストプラクティスをもっと知る
さて、CALCULATE 関数の filter 引数 は、True / False を返す Boolean 式で記述する。 ということだけど、実際にはどのように評価されているかを理解するとよりよいのです。
CALCULATE(
SUM( Sales[数量] ),
Products[区分名] = "飲料"
)
は次の式に相当する。
CALCULATE(
SUM( Sales[数量] ),
FILTER(
ALL( Products[区分名] ),
Products[区分名] = "飲料"
)
)
FILTER 関数は、table 引数で定義された table 式 各行を反復して、filter 式 が true である行を抽出する。そして、CALCULATE の filter 式がひとつの列で定義されているとき、ALL( 'table'[Column] )。このテーブル式で得られるのは、重複が削除された列の値リスト。フィルタ条件に使用するテーブルはこれで充分だから。
別の例も見てみる。
CALCULATE(
SUM( Sales[数量] ),
Products[区分名] = "飲料"
|| Products[単価] = 100
)
は次の式に相当する。
CALCULATE(
SUM( Sales[数量] ),
FILTER(
ALL( Products[区分名], Products[単価] ),
Products[区分名] = "飲料"
|| Products[単価] = 100
)
)
ALL( Products[区分名], Products[単価] ) は、Product テーブルに存在する [区分名] と [単価] の組み合わせのみである。なので、
CALCULATE(
SUM( Sales[数量] ),
FILTER(
ALL( Products ),
Products[区分名] = "飲料"
|| Products[単価] = 100
)
)
テーブルにクロスフィルタが適用されることがほぼない ディメンジョン テーブルであれば結果はかわらない。けれども仕草としてよいとは考えられない。
また、ひとつのテーブルから複数の列を参照する記述も許容されたので、
CALCULATE(
SUMX(
Sales,
Sales[数量] * Sales[単価]
),
Sales[数量] * Sales[単価] >= 10000
)
と、記述することもできる。これは、
CALCULATE(
SUMX(
Sales,
Sales[数量] * Sales[単価]
),
FILTER(
ALL( Sales[数量], Sales[単価] ),
Sales[数量] * Sales[単価] >= 10000
)
と認識される。、
CALCULATE(
SUMX(
Sales,
Sales[数量] * Sales[単価]
),
FILTER(
ALL( Sales ), // 必要以上にフィルタが除外されてしまう。
Sales[数量] * Sales[単価] >= 10000
)
という記述してはいけない。これは期待する結果を返さないことがあるよね。ベストプラクティスに忠実に、かつ同じ結果を得たいのであれば、
CALCULATE(
SUMX(
Sales,
Sales[数量] * Sales[単価]
),
Sales[数量] * Sales[単価] >= 10000,
REMOVEFILTERS( Sales )
)
だよね。
KEEPFILTERS 関数とは何?
filter 引数に定義したフィルタの既定動作(Override)を変更する KEEPFILTERS 関数について
CALCULATE(
SUM( Sales[数量] ),
Products[区分名] = "飲料"
)
と記述したとき、Products[区分名] = "飲料" で定義したフィルタは、メジャー外部のフィルタを無視する。
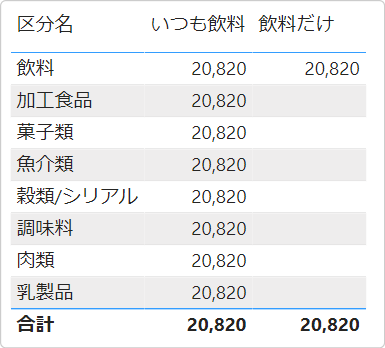
なので、Total 行含めすべての行で同じ評価結果となるわけだ。この既定の動作を変更するのが KEEPFILTERS 関数であり、ここでは、filter 引数を修飾する使い方になる。
CALCULATE(
SUM( Sales[数量] ),
KEEPFILTERS( Products[区分名] = "飲料" )
)
ビジュアルの飲料の行では、
ビジュアルから発生したフィルタ Products[区分名] = "飲料" と filter 引数で定義したフィルタ Products[区分名] = "飲料" の交差、Products[区分名] = "飲料" で SUM( Sales[数量] ) 評価されたといううこと。
Total の行では、
ビジュアルから発生したフィルタは存在していない。Products[区分名] = (すべて) と理解してもよくて、filter 引数で定義したフィルタ Products[区分名] = "飲料" との交差が Products[区分名] = "飲料"である。
そのほか行では、
例えば、加工食品の行では、Products[区分名] = "加工食品" と Products[区分名] = "飲料" の交差で抽出できる商品がこのモデルには存在しないので 評価結果は BLANK だ。
なお、パフォーマンスに影響する可能性があるケースは次の通り。
CALCULATE(
DISTINCTCOUNT( Sales[受注ID] ),
FILTER(
Sales,
Sales[数量] >= 100
)
)
CALCULATE(
DISTINCTCOUNT( Sales[受注ID] ),
KEEPFILTERS(
Sales[数量] >= 100
)
)
これら2つのメジャーは同じ結果を得ることができる。
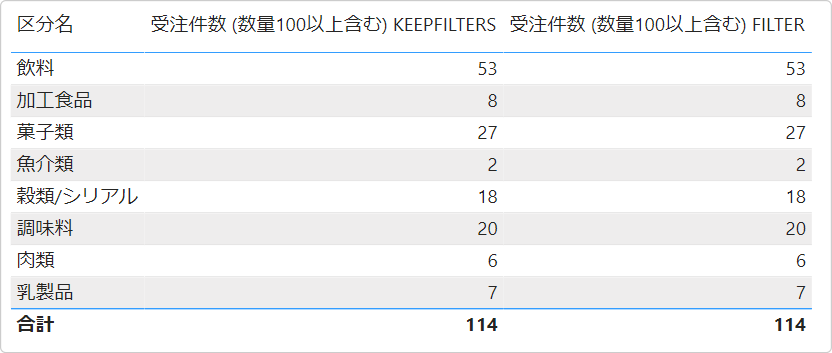
できるが、DAX Caluclation engine でのクエリの解釈が異なるっているのだ。CALCULATE 関数の filter 引数に FILTER 関数を使用しないというベストプラクティスに沿っているので KEEPFILTERS 関数を使用するアプローチがおススメなのである。この選択は、パフォーマンスが悪化するということがほぼないと思うし、シンプルに記述したほうがいいでしょって話。
filter 引数に メジャーを使用しなければならないとき
filter 引数に定義する Boolean 式 に メジャーを使用することはできない。これは制約のままである。で、主な使われ方としては、異なる粒度で評価されたメジャーの結果をフィルタ条件とするときなど。
CALCULATE(
[受注額],
FILTER(
VALUES( Dates[YearMonth] ),
[受注額] > 300000
)
)
ただし、複雑な処理になっていることがあるから、集計結果が期待するものかどうかは当然のこと、パフォーマンスが低下していないかなど、よく確認することが重要だ。
その他