アプリ開発者にとってはVagrant(仮想化はVMwarePlayerではなくVirtualBox)が主流なのでしょうが、今後サービスのクラウド化にともなって運用も自動化され、アプリとインフラのエンジニアの壁はなくなり「サービス開発&運用エンジニア」という流れになると思っています。
ということでAWS, Azureも提供しているVMwareの自律運用機能について簡単にメモしておきます。(MicrosoftはHyper-VというVMwareに対抗する仮想技術を持っているので、AzureにVMwareを載せるにあたっては微妙な言い回しをしていますが。。。)
VMwareの4つの自律運用機能
- VMware vMotion(仮想マシンを停止せずに別の物理サーバに移動)
- VMware HA(物理サーバ障害時にそこで稼働していた仮想マシンを移動)
- VMware DRS(物理サーバの負荷の偏りを仮想マシン移動によって平均化)
- VMware DPM(負荷状況によって仮想マシンを移動して物理サーバの電源オフ&オン)
では、ひとつずつ簡単に。
1. VMware vMotion
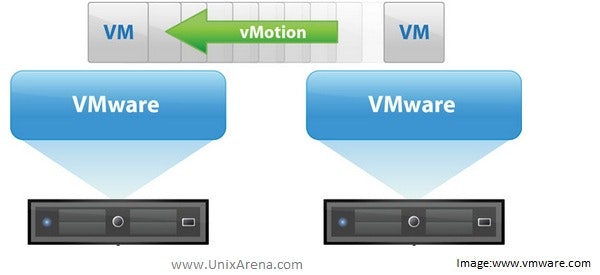
VMwareの物理サーバ(ESXiサーバ)上で稼働しているLinuxやWindowsなどの仮想マシンを停止せずに別の物理サーバに移動します。ネットワークをはじめサーバダウン時間はほぼゼロです。(1秒未満)
どのように実現しているかは下記のサイトが参考になりました。
http://d.hatena.ne.jp/takaochan/20080412/1207934961
これがVMware技術の土台になります。
2. VMware HA(High Availability)
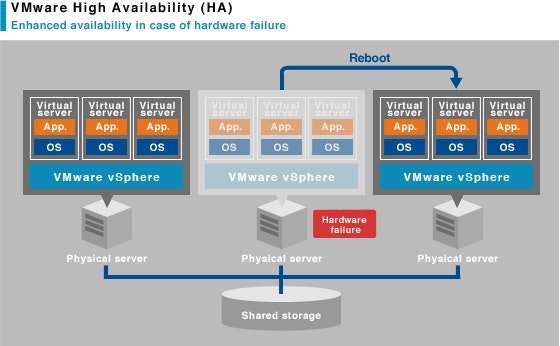
いわゆるクラスタです。障害でダウンした物理サーバ上で動いていた仮想マシン群を別の物理サーバに移動させてサービスを続行させます。物理サーバがダウンした時点で当然そこで稼働していた仮想マシンもダウンしますが、すみやかに別の物理サーバ上でRebootされます。
3. VMware DRS(Distributed Resource Scheduler)
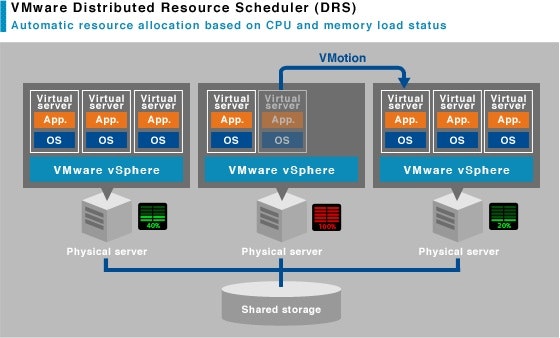
ある物理マシンの負荷が他の物理マシンに比べて高い場合、負荷の原因となっている仮想マシンを別の物理マシンに移動させて物理マシンの負荷を平均化させます。仮想マシンは上記のvMotionを使用して稼働したまま移動するので基本的に「サービス断なし」になります。この機能は仮想マシンを起動する際にどの物理サーバで稼働させるかの判断にも使用されます。
4. VMware DPM(Distributed Power Management)
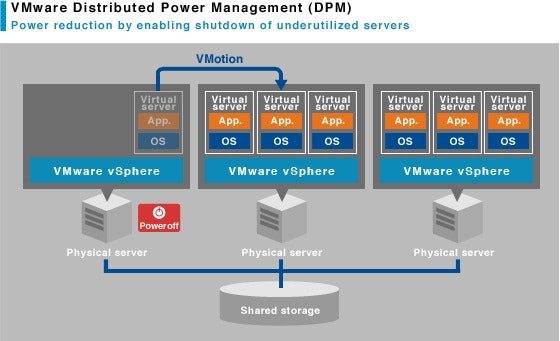
サービス全体の負荷状態から「物理マシン数を減らせる」と判断された場合、ある物理マシン上で稼働している仮想マシンを別の物理マシンに移動させて、空いた物理マシンを電源オフします。逆に「物理マシン数が足りない」と判断された場合は、物理マシンを電源オンしてそこに仮想マシンを移動させます。もちろんvMotionを使用して稼働したまま移動するので基本的に「サービス断なし」になります。
これは状況次第でクラウドサービスの課金など運用コストに大きく影響します。
今後のサービス運用
ということで今後の流れとして、少なくとも物理マシン切替などの作業は自動化されいわゆるオペレータは必要なくなるかもしれません。一方、上記の自律運用機能の障害発生時には「サーバしかわからない」「ネットワークしかわからない」「アプリしかわからない」というエンジニアではなく、サーバ&ネットーワーク&アプリすべてを把握し、かつ上記VMwareの機能にも精通したエンジニアが必要となってくるかもしれません。
おまけ:ところで現状
ところでこれらのVMwareの機能、かなり以前から提供されていて私の現場環境でも使用可能なのでが、現状どうかというとHAだけしか有効にしていません。
おまけに手動によるvMotionも事前にユーザ許可が必要ですし、やる時は結構ビクビクだったりします。つまりはまだちょっと「理屈では」「マニュアル上は」という感じで若干不安定という印象を持ってます。
ただ今後これらの技術・機能が安定してきて実例・実績が増えてくれば、ごく当たり前になってくると思います。
もうひとつおまけ
実はもうひとつ「VMware FT(Fault Tolerance)」というのがあるのですが仮想サーバの移動を利用するのではなく「メモリを含めてまったく同じ状態で稼働している物理マシンを用意しておいて、障害時は瞬時にそちらに切り替える」というものです。今回の話の流れだとちょっと支流な感じがするので割愛。VMware HAは物理マシン障害時にいったん仮想マシン群がダウンしますがVMware FTは「サービス断なしのクラスタ」というイメージです。これについてはまた別の機会に。