昨年末からデータ可視化ツールを諸々触る中で Redash おもろいわ〜ってなってたんですが、QiitaでMetabaseの記事を目にしてしまったので使わざるを得なかった。投稿者様ありがとうございます!!
https://qiita.com/acro5piano/items/0920550d297651b04387
面白さに勢いで書いてしまったので、拙い点はご容赦ください。
結論から言えば、MetabaseはRedashより遥かに使いやすかった!!(あくまで可視化系ツールを最初に触る人としてはという枕詞つきですが)
Docker使ってる身としては、docker composeでシコシコとセットアップしなくても、docker run 一発で起動できるのは楽で助かる。もちろん、docker compose は様々なコンテナをまとめてセットアップする点で楽なのですが、1ツール1コマンドで起動するのに比べたら手間がかかりますしね。
[今回紹介するMetabase]
https://www.metabase.com
[苦労した方のRedash]
https://redash.io
何がすごいの??
前提として、MetabaseとRedashで比較してみた感触で書きます。それぞれ数時間しか触ってないですが、雰囲気だけでも伝わればと。
セットアップが楽
公式によると、セットアップの選択肢は結構あるようです。
- Docker ... コマンド一発で起動する
- AWS ... Elastic Beanstalkで動かす
- Heroku ... ボタンをポチポチするだけ
- OSの上に直接のっける (Macでやる方法が最初に紹介されてますが、まだ深くまでは見れてない)
- JARファイルをダウンロードして、
java -jar metabase.jar
Redash側は、大きく分けて以下2種類にセットアップが分けられます。
- 公式でホストされたインスタンスを使う
- OSSとして公開されているイメージを元に自分でセットアップ
- Ubuntu上にセットアップ用のスクリプトを使って立てる
- クラウド上の定義済みイメージを使う(AWS / GCP)
- Docker Composeで立てる
私はDockerの勉強がてらMetabaseをDockerのイメージから起動させましたが、JARファイルでやるのも簡単そうですね!
Dockerだと以下コマンドを叩いて、http://localhost:3000にアクセスすればOKです。
$ docker run -d -p 3000:3000 --name metabase metabase/metabase
xxxxxxyyyyyyyxxaserjaser <- コンテナID
$ docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
xxxxxxyyyyy metabase/metabase "/app/run_metabase.sh" 3 seconds ago Up 2 seconds 0.0.0.0:3000->3000/tcp metabase
ハマりポイントとしては、DockerコンテナでMetabaseのデータ取得先のDBを動かしている場合は、--link オプションで動かさないとセットアップで以下のエラーが出て先に進めなくなります。
No matching clause: com.mysql.jdbc.exceptions.jdbc4.CommunicationsException: Communications link failure The last packet sent successfully to the server was 0 milliseconds ago. The driver has not received any packets from the server.
解決例としては、以下のようにリンクさせればOK。これはMySQLのコンテナとリンクさせた例。
docker run -d -p 3000:3000 --name metabase --link ponz-mysql:ponz-mysql metabase/metabase
アクセスして約1分待てばHome画面に遷移します。超早い!
ここから、自分で登録したDBやサンプルで最初から入ってるデータセットを調べたりできます。
データ可視化までにSQLを使わなくても良い
これがRedashとの最大の違いかなと。(私の知っている限りなので、もし違ったら教えてください)
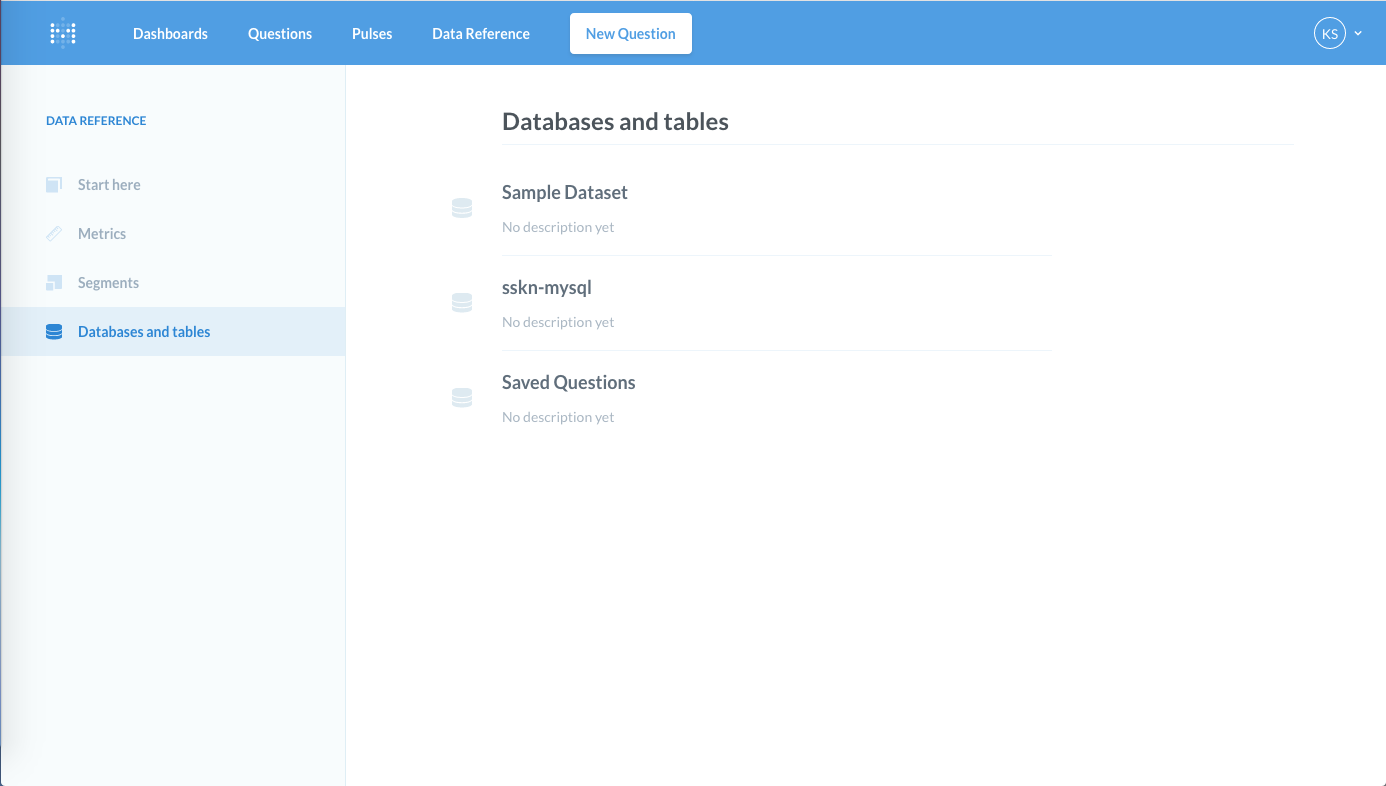
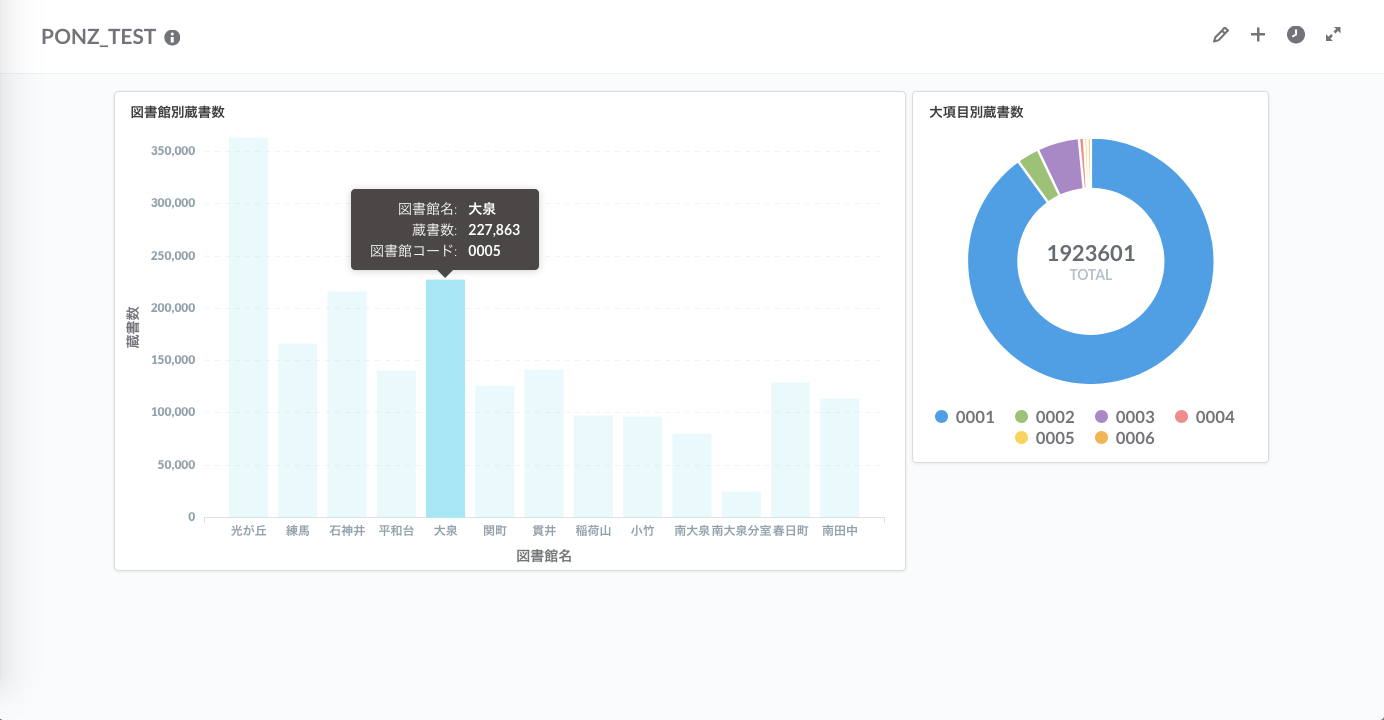
例えば、東京都練馬区の各図書館の蔵書数(平成28年度時点)について調べたいとします。
※ こちらの蔵書数については、区発行のオープンデータを使用させていただきました。元はRedashいじるために使おうとしてました。。。
調べたいデータを"New Question -> Custom" から選んで、自分で読み込んだDBのテーブルを選択。あとはプルダウンからサクッとデータ項目を選べば綺麗なチャートがあら簡単。円グラフが作れました。ここから、区分'0001'(図書資料)が圧倒的に多いな〜と分かりますね。
Redashは "Group by" に選んだ項目で絞ったりグラフを描画しても思った通りにならない時があるので、こちらの方が直感的かもしれないです。(個人差はあると思いますよ)
もちろん、SQLも書いても問題なくいけます。"New Question -> Native Query" でSQLエディターが出てくるので、ここでSQLを打てばOK。
若干Redashの方がグラフのオプションが多い気がします。
ダッシュボートはグリッド形式で大きさを指定して配置できます。ここも難なくできます。
雑感
まだバージョンが 0.27.2 (2018/01/04時点) なので、破壊的な変更が入る可能性がなきにしもあらずですが、非常に可能性を感じさせるプロダクトですね!非エンジニアもRedash以上にデータを扱いやすくなりそう...