RaspberryPiと外部ブラウザ(Chrome)を利用して会話するのを以前試したのですが( Raspberry Pi とブラウザで会話する。)これを自立型で出来ないかあれこれ考えていたところ、ブラジルの方でElectronを利用して実現されている方を見つけました。
Raspberry Pi 3 + NodeJS + Electron - Cloud and Mobile
動画を拝見すると確かにRaspberryPiのみを使って会話をしています。JavaScriptライブラリを使うことで簡単に実装できるよ!みたいなことが書かれているので参考に試してみました。
こんな感じ
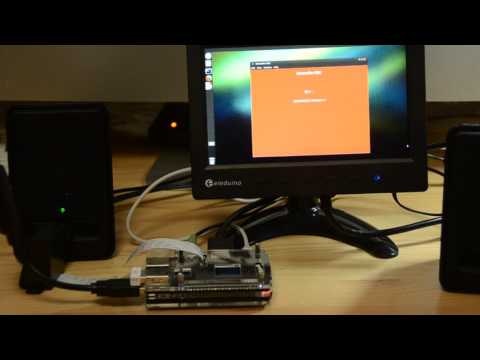
Raspberry Pi Voice Assistsnt - YouTube
キーワードに対して2〜3の簡単な返答はできるようになりました。基本ブラジルのAugusto Goncalvesさんのコードを少しいじっただけなのですが、少々ハマった部分もありましたのでまとめてみます。
環境
Raspberry Pi2 ModelB
- Ubuntu MATE 16.04
- Node.js v-6.2.0
- Electron 1.0.2
Ubuntu MATE
動画のモニターを見ていただけると分かると思うのですがOSはRaspbianではなくてUbuntu MATEを使用しています。Macで上手く動作したんでいざラズパイで試そうとしたところ、Electronのインストールでエラーが出てしまいました。
Electron not starting on Raspberry Pi #145
検索で調べたところ、どうもRaspbianのバグで今のところインストール時にエラーになってしまう様です。仕方がないのでUbuntu MATEを利用することにしました。
機会があればまとめたいのですが、ラズパイに最適化されているRaspbianと比べて設定しなければいけないことが多くて少々面倒です。SSHが初期インストールされていないのでセットアップにモニターとキーボード・マウスが必要になります。
ただし、使用感は上々でElectronもすんなりインストールする事が出来ました。ダウンロードは以下より可能です。
Annyang.js
ChromeのWeb Speech Recognition APIはさすがにGoogleさんが作っているだけあって恐ろしく正確に日本語も解析してくれます。ただし、ブラウザで利用する際には安全面からか数分経つと自動的に音声読み込みを遮断してしまう仕様になっています。
以下のライブラリを使用することで音声読み込みが切れることなく利用する事が出来ます。
annyang! SpeechRecognition that just works
setTimeout(annyang.start, 1000-timeSinceLastStart);こんな記述が見えるので、タイマーを利用して1秒毎に音声検索を実行するようにしている様です。
これでマウスクリックやタップを利用せずに音声認識を使用する事が出来ます。
Electron desktop app using annyang
上記のライブラリを制作されているイスラエルのTal Aterさんがさらに気の利いたことにElectronで利用出来るライブラリを公開されていました。
const annyang = require('annyang');でライブラリを読み込む事が出来ます。最新のElectron1.0でも利用可能でした。
ResponsiveVoice.js
MacやWindowsなどには音声発話エンジンが搭載されていますが、Raspberry Piで音声発話させる際にはライブラリを読み込むか外部APIより読み込まなくてはなりません。
そこで以下のライブラリを利用します。
こちらも優れもので、発話エンジンが搭載されている場合はそれを利用します。以下Macで使用した時の動画です。
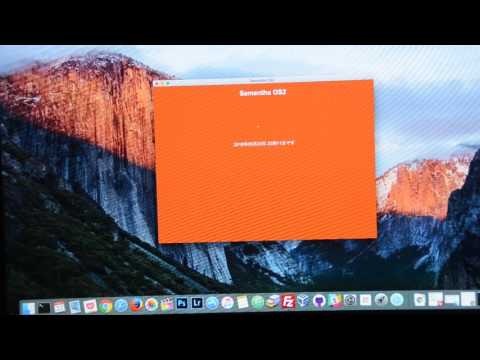
Electron App Voice Assistant - YouTube
Macで利用する際はお馴染みKyokoさんを呼び出して発話させてくれます。
上記のラズパイで利用する際は、
http://responsivevoice.org/responsivevoice/getvoice.php?t=
こんな記述が見れるのでAPIのエンドポイントに自動的にリクエストを送り、帰って来た音声データをaudio属性で自動的に再生してくれます。
Web経由の音声発話は、やはり組み込みと比べると1,2秒タイムラグが出来てしまいますね。
音声発話エラー時の対応
ここが一番のポイントになると思うのですが、APIリクエストで音声発話をさせると結構頻繁にエラーが起きます。
冒頭のAugusto Goncalvesさんはこんな風に記述していました。
function say(msg, callback) {
console.log('Pause annyang');
console.log('Saying: ' + msg);
lastSentence=msg;
annyang.abort();
responsiveVoice.speak(msg, CONFIG.voiceSpeakingLanguage, {
onend: function () {
console.log('Resume annyang');
annyang.start();
}
});
}
音声発話のタイミングで一旦音声認識を停止させて、発話が終わったタイミングで音声認識を開始させています。
ラズパイで試すと結構音声発話にエラーが発生します。キーボード無しで操作する際はそこでエラーが出て停止状態になってしまいます。
上記のコードに加えて、音声発話がエラーになった時も音声認識を再開する様にしてみました。(冒頭動画の30秒位で一度発話エラーが起きています。エラー後に再度音声認識を自動で再開させています)
余談
どうでも良いことですが、この音声アシスタント「サマンサOS2」は映画「her/世界でひとつの彼女」に登場するAI「SamanthaOS1」(声:スカーレット・ヨハンソン )にインスパイアされています。
本当にどうでも良いですね。
まとめ
コードは一応GitHubに上げてあります。
映画の「SamanthaOS1」の様に気の利いた会話が出来る様になるにはまだまだ先になりそうですが。