先日Qiitaで画期的なテキスト分類の記事を拝見しました。
テキスト分類器fastTextを用いた文章の感情極性判定 - Qiita
これは文章のネガポジ判定に辞書を使わず、単語のベクトルによって文章を分類する仕組みのようです。
Word2Vecの作者の方が新たに作った分類器のようですね。試しに音声入力を利用してネガポジ判定を試してみました。

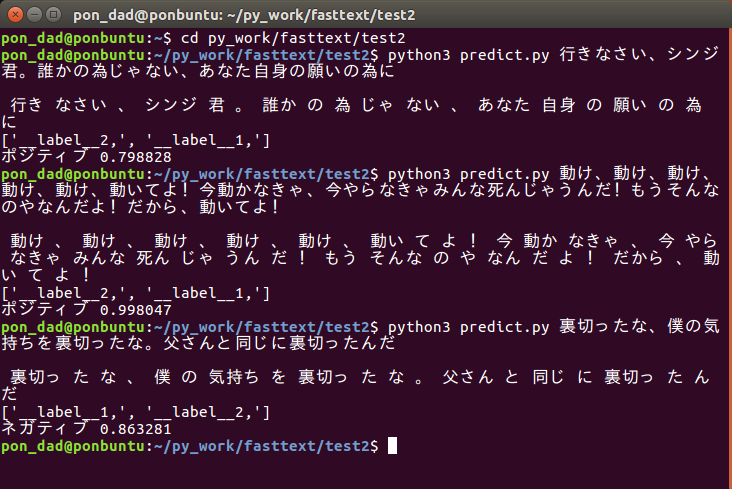
Chromeの音声認識を利用して入力した文章をfastTextでネガポジ判定させています。セリフは著名アニメ作品の主人公の台詞です。
ここではポジティブと判定しています。
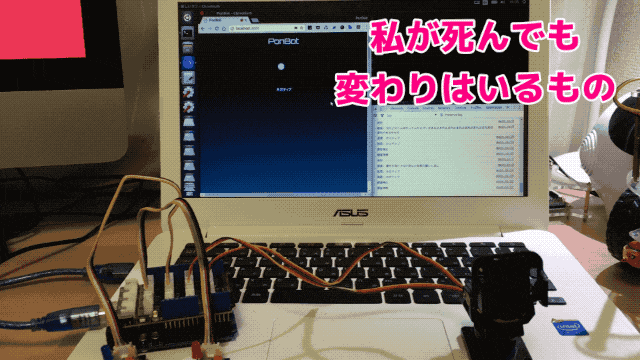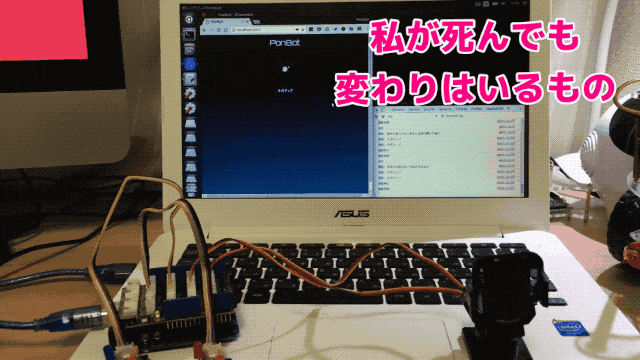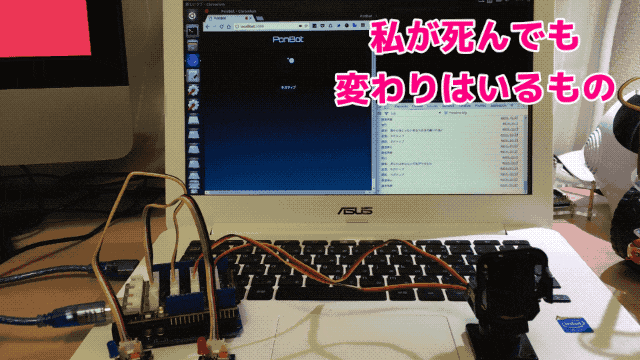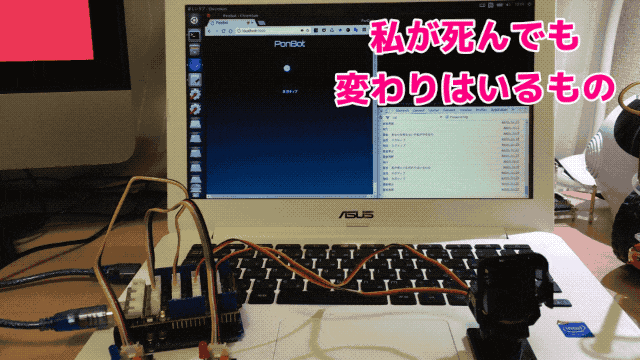
同じく主要キャラクターの有名な台詞です。ここではネガティブと判定されました。
学習モデルはTwitterのネガティブ3,000ツイート、ポジティブ3,000ツイートからつくりました。さて上記記事を参考にして試してみた方法をまとめてみます。
環境
- Ubuntu16.04(Chromebookの仮想環境に入れたもの)
- Python 3.5.2
- Node.js v7.4.0
- Arudino互換機(ちょっと怪しい中華製のもの)
- GROVE ベースシールド
RaspberryPiでfastTextが上手く動かなかったので、今回はChromebookに入れたUbuntu16.04で試してみました。
fastText
以下のレポジトリからクローンして利用できます。
処理の速さもさることながら、学習モデルを簡単に作れるところがポイントです。
通常の機械学習で文章をラベル分類する際、前処理が非常に大変ですが、fastTextでは、分かち書きされた文頭に_label_*,をつけるだけで分類が出来ます。
ツイートから学習モデルを作る
今回はTwitterの「ポジティブ名言」「ネガティブ名言」をつぶやくBotアカウントよりデータをダウンロードしました。
TwitterAPI でツイートを大量に取得。サーバー側エラーも考慮(pythonで) - コード7区
ダウンロード方法はこちらの記事で詳しく説明されているのでサンプルコードを利用させて頂きました。こんなテキストが取得できました。
拾う神あれば 捨てる神あり
わしは劣化した。もうしょうがない。
この鏡、どの角度から見ても気持ち悪い
『新しい喜びは新しい苦痛をもたらす』モーツァルト
友愛の多くは見せかけ。恋情の多くは愚かさであるにすぎない
(以下略)
勝ちに不思議の勝ちあり、負けに不思議の負けなし。
自分が立っている所を深く掘れ。そこからきっと泉が湧きでる。
人生が終わってしまうことを恐れてはいけません。 人生がいつまでも始まらない事が怖いのです。
今日行ないたい善行があれば、すぐに実行せよ。決して明日に延ばすな
(以下略)
これをmecabを利用して分かち書きします。(辞書はmecab-ipadic-neologdを使用しました)
$ mecab -d -/usr/lib/mecab/dic/mecab-ipadic-neologd -O Wakati negative.txt wakati_negathive.txt
こんな感じです。
拾う 神 あれ ば 捨てる 神 あり
わし は 劣化 し た 。 もう しょうが ない 。
この 鏡 、 どの 角度 から 見 て も 気持ち 悪い
『 新しい 喜び は 新しい 苦痛 を もたらす 』 モーツァルト
(以下略)
勝ち に 不思議 の 勝ち あり 、 負け に 不思議 の 負け なし 。
自分 が 立っ て いる 所 を 深く 掘れ 。 そこ から きっと 泉 が 湧き でる 。
人生 が 終わっ て しまう こと を 恐れ て は いけ ませ ん 。 人生 が いつまでも 始まら ない 事 が 怖い の です 。
今日 行ない たい 善行 が あれ ば 、 すぐ に 実行 せよ 。 決して 明日 に 延ばす な
(以下略)
文頭へのラベルの差し込みはUNIXのsedコマンドを利用しました。(Macだと結構ハマるのですが、Ubuntuだとスムーズに処理出来ます)
$ sed -e "s/^/__label__1, /g" wakati_negative.txt > label_negathive.lst
こんな感じです。
__label__1, 拾う 神 あれ ば 捨てる 神 あり
__label__1, わし は 劣化 し た 。 もう しょうが ない 。
__label__1, この 鏡 、 どの 角度 から 見 て も 気持ち 悪い
__label__1, 『 新しい 喜び は 新しい 苦痛 を もたらす 』 モーツァルト
__label__1, 友愛 の 多く は 見せかけ 。 恋情 の 多く は 愚か さ である に すぎ ない
(以下略)
__label__2, 勝ち に 不思議 の 勝ち あり 、 負け に 不思議 の 負け なし 。
__label__2, 自分 が 立っ て いる 所 を 深く 掘れ 。 そこ から きっと 泉 が 湧き でる 。
__label__2, 人生 が 終わっ て しまう こと を 恐れ て は いけ ませ ん 。 人生 が いつまでも 始まら ない 事 が 怖い の です 。
__label__2, 今日 行ない たい 善行 が あれ ば 、 すぐ に 実行 せよ 。 決して 明日 に 延ばす な
(以下略)
この2ファイルを1つにまとめます。
__label__1, 拾う 神 あれ ば 捨てる 神 あり
__label__1, わし は 劣化 し た 。 もう しょうが ない 。
__label__1, この 鏡 、 どの 角度 から 見 て も 気持ち 悪い
__label__1, 『 新しい 喜び は 新しい 苦痛 を もたらす 』 モーツァルト
__label__1, 友愛 の 多く は 見せかけ 。 恋情 の 多く は 愚か さ である に すぎ ない
(以下略)
__label__2, 勝ち に 不思議 の 勝ち あり 、 負け に 不思議 の 負け なし 。
__label__2, 自分 が 立っ て いる 所 を 深く 掘れ 。 そこ から きっと 泉 が 湧き でる 。
__label__2, 人生 が 終わっ て しまう こと を 恐れ て は いけ ませ ん 。 人生 が いつまでも 始まら ない 事 が 怖い の です 。
__label__2, 今日 行ない たい 善行 が あれ ば 、 すぐ に 実行 せよ 。 決して 明日 に 延ばす な
(以下略)
これをfastTextの分類器にかけ、学習モデルを作ります。上記サイトのlearning.pyを利用させて頂きます。
$ python3 learning.py label_negaposi.txt negaposi.bin

これで学習済みモデルのバイナリファイルが出来ました。
リンクを貼っておきますので、試しに使ってみたい方がいらっしゃいましたらご自由にお使い下さい。
Python3でネガポジ判定
fastTextは3層のニューラルネットワークです。分類したい文章を形態素に分け(分かち書きし)学習済みモデルを元にしてベクトルの近いものを数値で表すことが出来ます。
Pythonで利用するためのモジュールも公開されています。
Python3で利用するときは以下の様にインストールします。
$ sudo pip3 install cython
$ sudo pip3 install fasttext
ドキュメントによれば、推測ラベルを抽出するのにclassifier.predict()メソッドを使い、と推測データを抽出するのにclassifier.predict_proba()メソッドを使うとありました。
ドキュメントはPython2系だったので3系に合わせて少し書き換えてみました。subprocessモジュールを使ってmecabで分かち書きしたあと、学習済みモデルを利用して推測します。
# -*- coding: utf-8 -*-
import sys
import fasttext as ft
import subprocess as cmd
obj = sys.argv[1]
morp = cmd.getstatusoutput("echo " + obj + " | mecab -Owakati -d /usr/lib/mecab/dic/mecab-ipadic-neologd")
words = morp[1]
print('\n', words)
classifier = ft.load_model('negaposi.bin')
estimate = classifier.predict([words], k=2)
estimate_2 = classifier.predict_proba([words], k=2)
print(estimate[0])
if estimate[0][0] == "__label__1,":
print('ネガティブ',estimate_2[0][0][1])
elif estimate[0][0] == "__label__2,":
print('ポジティブ',estimate_2[0][0][1])
実行結果はこんな感じです。
おまけ - Chromeで音声認識してArduinoに反応させる
なんか感情認識出来るトイロボットを作ってみたかったので、試しにやってみました。長くなってしまったので、コードだけ残しておきます。
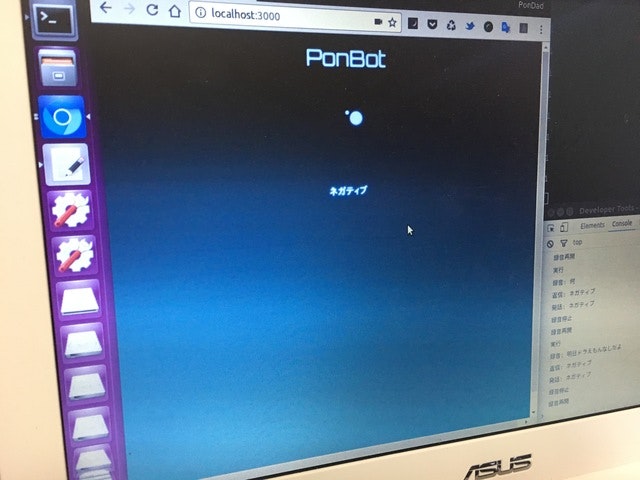
Chromeで音声認識させます。

Arduinoでネガティブの場合は青LED点灯、サーボが首を横に振ります。ポジティブの場合は赤LED点灯、サーボが首を縦に振ります。
まとめ
今回は格言ツイートを元に学習済みモデルを作成したので、ちょっと長くて固めの表現だと上手いことネガポジ判定をしてくれました。
ラベル付けされた大量の会話文をもとにしたらかなり高性能な分類器が出来そうに感じます。
個人の手作業でラベル付するのはちょっとしんどいかもしれないですね。では。