※メモしたいことが増え次第追記
桁数を指定
# 桁数指定
> format(0.3456789, digits = 2)
[1] "0.35"
# 百分率表記
> sprintf("%1.2f", 0.123456 * 100)
[1] "12.35"
列の入替え
> df
A C B
1 1 3 2
> df[,c(1,3,2)]
A B C
1 1 2 3
plotされる図で日本語が文字化け回避
# フォントをHirakakuProN-W3に設定
> par(family = "HiraKakuProN-W3")
描画関連
誤差バーを追加
# (x, y)の点に対してyに標準偏差をプロット
arrows(x, y - stddev, x, y + stddev, code = 3, length = 0.02, angle = 90)
y = xの線をプロット
abline(0, 1, lty = 2)
凡例を追加
legend("topleft", lty = rep(1, 6), legend=labels, col = palette()[-1])
乱数の生成
# 5つの乱数生成
> runif(5) # デフォルトでは0~1
[1] 0.7698414 0.4976992 0.7176185 0.9919061 0.3800352
# 0~10の間で乱数生成
> runif(5, min = 0, max = 10)
[1] 7.774452 9.347052 2.121425 6.516738 1.255551
# シードの固定(同じ乱数を出力する)
> set.seed(1); runif(5)
[1] 0.2655087 0.3721239 0.5728534 0.9082078 0.2016819
分布関数から値の取得
確率分布と乱数に関する使い方
| 用途 | 関数名 | 説明 |
|---|---|---|
| 確率密度(pdf: probably density function) | dxxx(q) | qは確率点を表す |
| 累積分布(cdf: cumulative distribution function) | pxxx(q) | |
| 確率点(qauntile) | qxxx(p) | |
| 乱数(random) | rxxx(p) |
Rに用意されてる主要な確率分布
| 分布名 | コード名 | パラメータ |
|---|---|---|
| ベータ分布 | beta | |
| 二項分布 | binom | n: 事象が起きる回数, size:試行回数, prob:事象が起きる確率 |
| コーシー分布 | cauchy | |
| χ二乗分布 | chisq | |
| 指数分布 | exp | |
| F分布 | f | |
| ガンマ分布 | gamma | |
| 幾何分布 | geom | |
| 超幾何分布 | hyper | |
| 対数正規分布 | lnorm | |
| ロジスティック分布 | logis | |
| 多項分布 | multinom | |
| 負の2項分布 | nbinom | |
| 正規分布 | norm | |
| ポアソン分布 | pois | |
| t分布 | t | |
| 一様分布 | unif | min:最小値, max:最大値 |
参考:確率分布と乱数
離散値から累積密度関数と累積確率の算出
累積分布関数$F$は「確率変数$X$がある値$x$以下($X \le x$)の値となる確率」を表す関数
$$
F(x) = P(X \le x)
$$
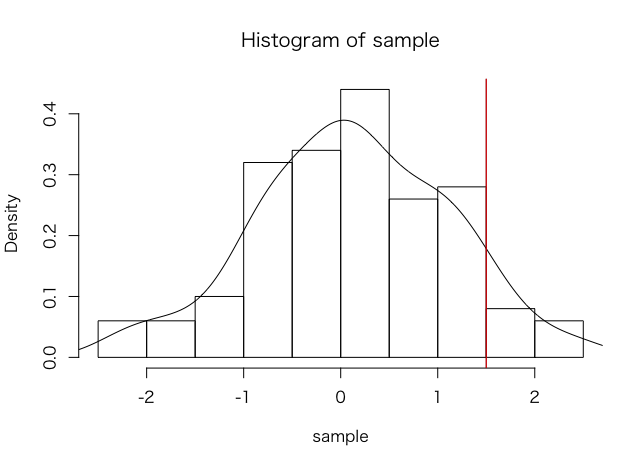
# 正規分布からサンプリング
> sample <- rnorm(100)
# 確率密度でヒストグラムを描画
> hist(sample, freq = F)
# 確率密度の曲線描画
> lines(density(sample))
# 累積確率関数の生成
> ecdf.sample <- ecdf(sample)
# 1.5以下の累積確率
> ecdf.sample(1.5)
[1] 0.93
# 累積確率の閾値描画