背景
最近趣味で釣りを始めたのですが、せっかく釣った魚が何者なのか分からないという悲しい事がよく起こります。
そんな自分のために魚の画像を入力したら、なんの魚なのか判定してくれる分類器を作成してみることにしました。
既にアプリあるんじゃないの?と思われたあなた、正解です。
ただ、自分で作ることにこそ「良さ」があると思います。
料理の場合、自分で頑張って作ったら思い入れが出来てその分美味しく食べられます。
ゲキまずでも、作ったという経験は今後活きると思います。
魚判定器でも精度はショボくても自家製判定器を使って判定する、ということやってみたいですね。
まぁしょうもない語りは置いておいて、本題いってみましょう!
概要
PyTorchを使ってカレイとカジカの画像の2クラス分類を行う
データセット用の画像は自力で集める
環境
- MacOS High Sierra
- Python3.8
- Pytorchの学習部分のみ、_google colaboratory_を使いました
方法
1. 大量の魚の画像をweb上からスクレイピング
ここのサイト様にお世話になりました。
様々な魚の画像が保存されていて良サイトです、眺めてるだけでも楽しい…
今回は、「カレイ」と「カジカ」の画像分類 に挑戦してみたいと思います。
見た目が結構違うのを選んだつもりですが、結構色味似てたりしたので、今更ですが他にベターなのはあったかもですね笑
長いコードになりましたので、作業ごとに分けています
カレイ画像のスクレイピングのためのコード その1~属と科のリスト入手~
from selenium import webdriver
from selenium.webdriver.common.by import By
from time import sleep
driver = webdriver.Chrome('/Users/name/Downloads/chromedriver')
# 指定したURLのWebページへ遷移
driver.get('https://zukan.com/fish/tree_index')
sleep(2)
driver.find_element_by_link_text('条鰭綱').click()
sleep(2)
driver.find_element_by_link_text('カレイ目').click()
sleep(2)
driver.find_element_by_link_text('カレイ科').click()
element = driver.find_element_by_id('dd141')
aTags = element.find_elements_by_tag_name("a")
url_list3 = []
for Tag in aTags:
url = Tag.get_attribute("title")
url_list3.append(url)
url_list3 = list(filter(lambda a: a != '', url_list3))
print(url_list3)
import pandas as pd
pd.Series(url_list3).to_csv('./text_flounder.csv', index=False)
カレイ画像のスクレイピングのためのコード その2~df作成まで(保存推奨、コードにはありませんが。。。)~
import re
import numpy as np
import math
import copy
file1 = pd.read_csv("./text_flounder.csv")
# 「種類」の処理1
df_fishes = file1[file1["0"].str.match('(.*)[^属]$')] # (?!hoge)否定先読みアサーション
print(df_fishes)
# 「●属」の処理1
df_zoku = file1["0"].str.extract('(.*属$)') # extractはマッチした最初の()部分のみ抽出
print(df_zoku)
# 「種類」の処理2
## NaN削除
df_fishes.dropna(inplace=True)
## index振り直し
df_fishes.reset_index(drop=True, inplace=True)
import math
import copy
# 「●属」の処理その2
## NaN埋める
df_zoku, df_zoku.loc[0]
df_zoku.fillna(0, inplace=True)
tmp = copy.deepcopy(df_zoku)
for i in range(len(tmp)):
print((tmp.loc[i]!=0).bool)
if all(tmp.loc[i] != 0):
old_zoku_name = tmp.loc[i]
tmp.drop(i, inplace=True)
else:
tmp.loc[i] = old_zoku_name.values[0]
tmp.reset_index(drop=True, inplace=True)
df = tmp.join(df_fishes)
df.rename(columns={0: "zoku", "0": "fish"}, inplace=True)
カレイ画像のスクレイピングのためのコード その3~selenuimで画像入手~
from selenium import webdriver
from selenium.webdriver.common.by import By
from time import sleep
import os
import time
import urllib.error
import urllib.request
from bs4 import BeautifulSoup
for num in range(len(df.iloc[:,0])):
print("処理回数", num)
driver = webdriver.Chrome('/Users/name/Downloads/chromedriver')
# 指定したURLのWebページへ遷移
driver.get('https://zukan.com/fish/tree_index')
sleep(5)
driver.find_element_by_link_text('条鰭綱').click()
sleep(3)
driver.find_element_by_link_text('カレイ目').click()
sleep(3)
driver.find_element_by_link_text('カレイ科').click()
sleep(4)
# driver.find_element_by_link_text('アカガレイ属').click()
driver.find_element_by_link_text(df.iloc[num, 0]).click()
sleep(3)
driver.find_element_by_link_text(df.iloc[num, 1]).click()
sleep(3)
tc = driver.find_element_by_id('tree_content')
url_img = tc.find_element_by_tag_name("a").get_attribute("href")
tc.click()
sleep(2)
save_img(url_img)
while True:
try:
driver.get(url_img)
next_url = driver.find_element_by_link_text("次へ »")
next_url.click()
sleep(2)
url_img = driver.current_url
print("ページ移動", url_img)
save_img(url_img)
except Exception as e:
# except:
print("最終ページに到達")
break
driver.quit()
def save_img(url_img):
req = urllib.request.Request(url_img)
html = urllib.request.urlopen(req)
soup = BeautifulSoup(html, "html.parser")
url_list = ['https://zukan.com'+img.get('src') for img in soup.find(class_='leaf_tiles_ul').find_all('img')]
# 人手で指定
download_dir = './img/add/flounder'
sleep_time_sec = 2
for url in url_list:
# print(url)
url_name = url.split('/')[-1]
url_name = url_name.split('?')[0]
download_path = download_dir + '/' + url_name
# print(download_path)
download_file(url, download_path)
print("保存", download_path)
time.sleep(sleep_time_sec)
すみませんipynbのママなのでゲキ汚いです、後日修正します。。。
カジカについては適宜、パスを設定し直していただければ収集できます(後日アップロードします)
2. 収集画像のreshape、データ拡張
カレイは534枚、カジカは634枚収集できました
枚数をカレイに合わせて、それぞれ534枚の画像を入手できました
はじめにサイズがバラバラなので画像をreshapeし、データ拡張のため左右反転させます
reshapeについてはiMage ToolsというAppleStoreにあったフリーソフトを使いました
形状はあんまり大きいと学習で苦戦しそうだったので、128(縦)x256(横)の画像サイズにしました。
左右反転についてはMacに標準搭載されている_プレビュー_を使って一括変換しました
結果、それぞれ1068枚のデータを最終的に獲得しました
これらを学習させ、判定器を作成します
3. Pytorchによる学習
はじめに下のようなデータセット用csvを作成します
画像のパス, label
hogehoge1.jpg, 0
hogehoge2.jpg, 0
hogehoge3.jpg, 1
hogehoge4.jpg, 1
・
・
・
データセット用csv作成
import glob
import pandas as pd
import numpy as np
lf_f = glob.glob('img/flounder_flip/*.jpg')
lf_r = glob.glob('img/flounder_resize/*.jpg')
ls_f = glob.glob('img/swordfish_flip/*.jpg')
ls_r = glob.glob('img/swordfish_resize/*.jpg')
# 0: カレイ
class_f = np.zeros(543)
# 1: カジカ
class_s = np.ones(543)
concat_f1 = np.concatenate([[lf_f, class_f]], axis=1)
concat_f2 = np.concatenate([[lf_r, class_f]], axis=1)
all_f = np.concatenate([concat_f1, concat_f2], axis=1)
concat_s1 = np.concatenate([[ls_f, class_s]], axis=1)
concat_s2 = np.concatenate([[ls_r, class_s]], axis=1)
all_s = np.concatenate([concat_s1, concat_s2], axis=1)
# 転地
all_f_T = all_f.T
all_s_T = all_s.T
# test.csvの作成
tmp1_f = all_f_T[:50,:]
tmp2_f = all_f_T[50:,:]
tmp1_s = all_s_T[:50,:]
tmp2_s = all_s_T[50:,:]
tmp3_test = np.concatenate([tmp1_f, tmp1_s])
df_test = pd.DataFrame(tmp3_test, columns=['path','label'])
tmp4 = np.concatenate([tmp2_f, tmp2_s])
tmp4_train, tmp4_val = np.vsplit(tmp4, [int(tmp4.shape[0] * 0.8)])
df_train = pd.DataFrame(tmp4_train, columns=['path','label'])
df_val = pd.DataFrame(tmp4_val, columns=['path','label'])
df_train.to_csv('./train.csv', index=False)
df_val.to_csv('./val.csv', index=False)
df_test.to_csv('./test.csv', index=False)
次にメインとなる学習部分です
ここは先人達の偉大なるソースコードを大いに参考にし、下のようにコードになりました
データの振り分けはtrain 2036枚, test 100枚にしました
実行環境はGoogle Colaboratoryです
Tesla k80で学習時間は3分くらいでした
PyTorchによる学習
import pandas as pd
import torch
from torch.autograd import Variable #自動微分用
import torch.nn as nn #ネットワーク構築用
import torch.optim as optim #最適化関数
import torch.nn.functional as F #ネットワーク用の様々な関数
import torch.utils.data as data_utils#データセット読み込み関連
import torchvision #画像関連
from torchvision import datasets, models, transforms #画像用データセット諸々
from torchvision.transforms import ToTensor
class Net(nn.Module):
# NNの各構成要素を定義
def __init__(self):
super(Net, self).__init__()
# 畳み込み層とプーリング層の要素定義
self.conv1 = nn.Conv2d(3, 6, 5) # (入力, 出力, 畳み込みカーネル(5*5))
self.pool = nn.MaxPool2d(2, 2) # (2*2)のプーリングカーネル
self.conv2 = nn.Conv2d(6, 16, 5)
# 全結合層の要素定義
# self.fc1 = nn.Linear(61, 120) # (入力, 出力)
self.fc1 = nn.Linear(16 * 1769, 120) # (入力, 出力)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 2) # クラス数が2なので最終出力数は2
# この順番でNNを構成
def forward(self, x):
# print(x.shape)
x = self.pool(F.relu(self.conv1(x))) # conv1->relu->pool
# print(x.shape)
x = self.pool(F.relu(self.conv2(x))) # conv2->relu->pool
# print(x.shape)
x = x.view(-1, 16 * 1769 * 1) # データサイズの変更
# print(x.shape)
x = F.relu(self.fc1(x)) # fc1->relu
x = F.relu(self.fc2(x)) # fc2->relu
x = self.fc3(x)
return F.log_softmax(x, dim=0)
train = pd.read_csv('./train.csv')
test = pd.read_csv('./test.csv')
val = pd.read_csv('./val.csv')
# valとの学習比較のやり方が分からなかったので、結合してtrainにしちゃいましょう
train_con = pd.concat([train, val])
train_con.reset_index(drop=True, inplace=True)
# 画像の変形処理
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
train_labels = torch.Tensor(train_con["label"])
test_labels = torch.Tensor(test["label"])
from PIL import Image
train_images = []
test_images = []
for i, file in enumerate(test["path"]):
image = Image.open(file)
image = transforms.ToTensor()(image)
test_images.append(image)
for i, file in enumerate(train_con["path"]):
image = Image.open(file)
image = transforms.ToTensor()(image)
train_images.append(image)
train_features = torch.stack(train_images)
train = data_utils.TensorDataset(train_features, train_labels)
test_features = torch.stack(test_images)
test = data_utils.TensorDataset(test_features, test_labels)
trainloader = data_utils.DataLoader(train, batch_size=32, shuffle=True, num_workers=2)
testloader = data_utils.DataLoader(test, batch_size=32, shuffle=True, num_workers=2)
# モデル定義
model = Net()
# GPU設定
device = 'cuda: 0'
model.to(device)
# Loss関数の指定
criterion = nn.CrossEntropyLoss()
# Optimizerの指定
optimizer = optim.SGD(model.parameters(), lr=0.001, momentum=0.9)
# トレーニング
# エポック数の指定
for epoch in range(100): # loop over the dataset multiple times
#データ全てのトータルロス
running_loss = 0.0
for i, data in enumerate(trainloader):
#入力データ・ラベルに分割
# get the inputs
inputs, labels = data
# Variableに変形
# wrap them in Variable
inputs, labels = Variable(inputs), Variable(labels)
# device設定
inputs, labels = inputs.to(device), labels.to(device)
# optimizerの初期化
# zero the parameter gradients
optimizer.zero_grad()
#一連の流れ
# forward + backward + optimize
outputs = model(inputs)
#ここでラベルデータに対するCross-Entropyがとられる
loss = criterion(outputs, labels.type(torch.long))
loss.backward()
optimizer.step()
# ロスの表示
# print statistics
running_loss += loss.data.item()
if epoch % 25 == 0: # print every 2000 mini-batches
print('[%d, %5d] loss: %.3f' %
(epoch + 1, i + 1, running_loss / 2000))
print('Finished Training')
print('[%d, %5d] loss: %.3f' %
(epoch + 1, i + 1, running_loss / 2000))
print('Finished Training')
# Accuracyの導出
correct = 0
total = 0
with torch.no_grad():
for (images, labels) in testloader:
images, labels = images.to(device), labels.to(device)
outputs = model(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('Accuracy: {:.2f} %'.format(100 * float(correct/total)))
結果
学習結果です

loss低すぎじゃないですか?
あかん気がプンプンする…、うまく学習できてる気がしないですねぇ
次に精度です
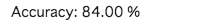
100枚テストしたので、84枚正しいと!
うーむ、これ大丈夫か笑
なんか過学習とかしてそうなので、あんまし信用ならないのですが…
課題
-
データ量が少ないので、データ拡張をもっとするべきだった
-
ネットワークを改良
- ネットの海に落ちているコーのをかき集めた状態。中身もよくわかってない部分も多い。中身を理解した後、改良を行っていきたい
-
PyTorchに関する圧倒的知識不足
まとめ
- PyTorchを用いて、魚画像の2クラス分類に挑戦した
- データセット作成のためにサイト上の魚画像を自力でスクレイピング
- 学習は上手くいってる気がしない
感想
初心者なりに頑張ってみましたが、信頼性がなさそうな結果。。。
あんましうまく学習できてる気がしないですね。
魚自動分類器の道のりはまだまだ遠い。。。
前置きにて、自作した判定器を使って魚の種類を判定させることに意義があるみたいなことを豪語してましたが、しばらくの間は既出アプリを使って釣った魚を判定するのがベストですね!自作はきつい!(おい)
ただ、作業日が4日間の割には頑張ったかと!
とりあえず骨組みみたいなのは出来て良かったです。
昔はこんなの出来なかったので成長したと思います笑
ただ、まだまだ勉強が足りないですね。
特にPyTorch難しいです。。。全然わかってないです笑
参考書やYouTubeなどで勉強ですねー
Qiita夏祭りのDataRobot部門に参加したく、step1は本日が締め切りなので急ピッチで記事書いていて、ほぼ書きなぐってる状態なので見苦しい箇所がたくさんあると思います、すみません。あとで編集します。
最後になりますが、期日ギリギリな中必死こいて作業したのはなんだかんだ楽しかったですね。
次のAutoMLの方も是非とも参加します!(次は時間に余裕を持って。。。)(AutoMLって?)