概要
#Qiita夏祭り2020_DataRobotoの記事になります。
今回はお題のstep2ということで、AutoMLを使って魚画像のデータセットを学習したいと思います!
step1で書いた前記事はここをクリック
- 魚画像のデータ収集方法(実はメイン)
- PyTorchによる学習方法(割とはちゃめちゃなので見ないで。。。)
等々が載ってます
AutoMLって?
恥ずかしながら全然知りませんでした……
要するに自分でプログラムを組んで機械学習させるのではなく、用意された優秀な機能が自動的に学習してくれるというツールです
データサイエンスの敷居が低くなって良いことですね!
Google, IBM, Amazon等、色々な会社が提供してるのですねー、ほぇぇぇ(呆然)
今回はDatRobot社のAutoMLに触ってみますよ!
ログインとか操作方法とか
@yshr10icさんの下記事が大変参考になりました
ありがとうございました!
画像データはパスが記載されたcsv込みでzipで圧縮したデータをimportする必要があります
それと、アップロードは100MBが限度ですので気をつけて下さいね
画像分類チャレンジ!
早速、画像分類に挑戦しましょう!
対象となるデータは前回同様「カレイ」と「カジカ」の画像になります。
カレイ: 0, カジカ:1 というクラス名になっています

まずは120枚の画像**(学習用&検証用: 100枚,テスト用: 20枚)**を使って、AutoMLを動かしていきましょう!
(最初、95MBのデータ量で作業したところ割と処理が重たくてしんどかったです。最初は小さめのデータで試すべき…)
⓵ データセット作成
学習用のcsvと画像データを同じフォルダに置き、zip
学習用の画像は100枚(カレイ 50枚, カジカ 50枚)です
csvの中身はこんな感じです
path, ,label
画像のパス1, 0
画像のパス2, 0
・
・
画像のバス99, 1
画像のバス100, 1
DataRobotのサイトにて、zipファイルをimportします
⓶ 学習
学習モードは3種類あります
今回はデフォルトの「クイック」で学習を行いました
しばらく経つと、モデルがいくつか出来上がります
一番上のモデルが最も精度が良い(っぽい)ので、このモデルを使って予測を行っていきましょう!

ちなみに「有用な特徴量」をクリックすると、学習データの訓練、検証、ホールドアウトの割合を手動で設定できます
⓷ 学習結果
学習モデル毎の結果は「評価」「解釈」ボタンをクリックすれば確認できます
「評価」では学習曲線・ROC曲線・収益曲線のグラフや、チューニングの設定ができます

「解釈」では、画像の分布を表示してくれるそうなのですが、私が使ってるsafariではなぜか表示できませんでした…
滅茶苦茶面白そうなのに。。。。
④ 予測
今回は20枚(カレイ10枚、カジカ10枚)の画像データをテストします
csvはパスだけでOKです(label必要なし → labelあっても問題なしでした)
img
画像パス1
画像パス2
・
・
画像パス19
画像パス20
「予測」をクリックして、テスト用のzipをimport!
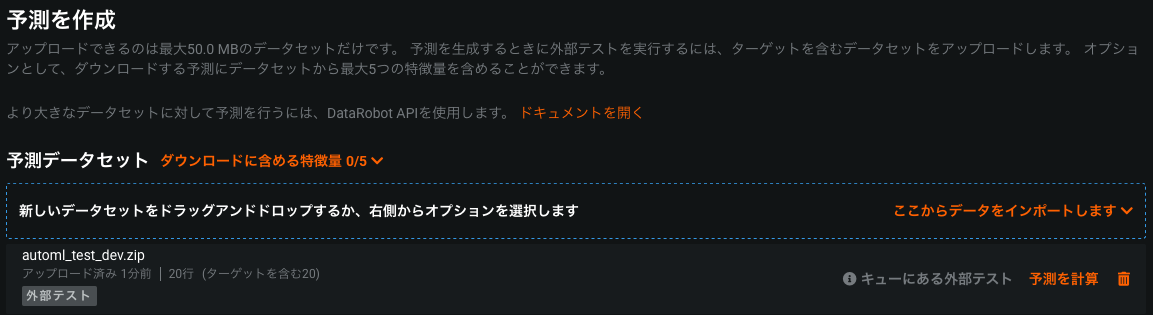
暫くしたら、「予測を計算」が「予測をダウンロード」になるので、ダウンロード
結果はこんな感じでcsv出力されました
row_id,Prediction,PredictedLabel
0,3.327158484838446e-05,0
1,0.003198503349000495,0
・
・
・
18,0.9965373958298681,1
19,0.9999377093989212,1
モデルの精度を出すために、ぱぱっとPython書いて正解率を導出しましょう
(今回は行数が少ないので目で見て正解率わかっちゃいますが(^◇^;)
まず、予測に使ったテストデータに(人手で)正解ラベルを付与します
こんな感じ↓
img, label
画像パス1, 0
画像パス2, 0
・
・
画像パス19, 1
画像パス20, 1
csvを一行毎に処理して、
AutoMLで予測されたlabelとテストデータのlabelがどれくらい一致したかを正解率として導出しましょう
こんな感じ↓
import pandas as pd
df1 = pd.read_csv('./test/fishimg_test_calc_correct.csv')
df2 = pd.read_csv('./test/automl.csv')
count = 0
for corr, pred in zip(df1["label"], df2["PredictedLabel"]):
if corr == pred:
count += 1
print(f'正解率: {count/dominator}')
精度は100%でした!(過学習???)
とりあえずAutoMLを最後まで動かすことが目的でしたので、この結果はアテにせず笑
次は、より大きなデータセットで挑戦してみましょう
⑤データセットの量を大きくして、再実験
データ詳細
はじめに今回のデータセットの詳細をお伝えします
学習用: 2072枚(カレイ1036枚, カジカ1036枚)
テスト用: 100枚(カレイ50枚, カジカ50枚)
⓵〜④の一連の作業をして、予測精度を出したところ、
95%の正解率となりました…!!!!
考察
精度が良すぎる理由
モデルの精度が良すぎて怪しい気がしたので自分なりに原因を考えてみました
恐らくなのですが、学習用とテスト用のデータの割り振りが甘いところがあったのが原因だと思います
今回、データ拡張のために左右反転の画像もデータセットにしているのですが、学習用の画像を反転させた画像をテスト用に使うのはアウトなのだと思います

上の内容を考慮してデータセットを作成したら、きっと正しい精度になるのではないかと思います
考察が正しいかどうかコメントいただけると嬉しいです…
まとめ
- AutoMLを使って魚の画像分類
- 精度良すぎた → 学習用データとテストデータの割振に問題あり?
感想
DataRobotによる夏祭りイベントstep2は時間に余裕を持って終わらせることができました(前回は期日5分前に終わった)
AutoMLの存在も知らない情弱でしたので、今回初めてDataRobot社のAutoMLに触れてみて、身を持ってその便利さを理解する事が出来ました!UIが洗練されていて使いやすかった……
ただ、自分の無知により、機能的によくわからないところも多々あったので、ちゃんと調査したいと思います!
こりゃあハナから自分でプログラムを組むのがばからしく感じたりもしてきそうですね…、勿論中身を理解するには自分でソースコードを書くのが一番だとは思いますが…
最後になりますが、イベント自体はめちゃくちゃ楽しかったです!
今後も自分がやりたいテーマでいろいろな記事を投稿できたらな、と思います!
ではでは!🙌