超解像(super resolution)とは
解像度を高くすること。
ただ解像度を高くするのではなく、人が見ても不自然に感じないように解像度を高くする。
SRCNNとは
超解像(super resolution)にディープラーニングとして、CNN(畳み込みニューラルネットワーク)を活用したものです。
全体像は以下通りです
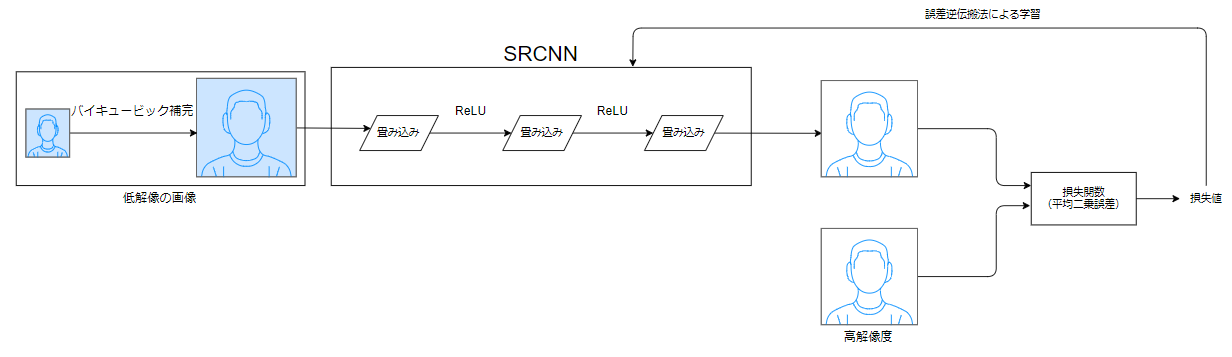
特徴は以下の通りです
- モデル入力前にバイキュービック補完で画像を拡大
- モデル構造は三層の畳み込み層で構成
- 損失関数は最小二乗誤差を採用
モデル構造
モデル構造は比較的単純な三層構造です。
畳み込み層とReLU活性化関数を組み合わせて作成します
class SRCNN(nn.Module):
def __init__(self, num_channels=1):
super(SRCNN, self).__init__()
self.conv1 = nn.Conv2d(num_channels, 64, kernel_size=9, padding=9 // 2)
self.conv2 = nn.Conv2d(64, 32, kernel_size=5, padding=5 // 2)
self.conv3 = nn.Conv2d(32, num_channels, kernel_size=5, padding=5 // 2)
self.relu = nn.ReLU(inplace=True)
def forward(self, x):
x = self.relu(self.conv1(x))
x = self.relu(self.conv2(x))
x = self.conv3(x)
return x
----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
Conv2d-1 [-1, 64, 32, 32] 5,248
ReLU-2 [-1, 64, 32, 32] 0
Conv2d-3 [-1, 32, 32, 32] 51,232
ReLU-4 [-1, 32, 32, 32] 0
Conv2d-5 [-1, 1, 32, 32] 801
================================================================
Total params: 57,281
Trainable params: 57,281
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.00
Forward/backward pass size (MB): 1.51
Params size (MB): 0.22
Estimated Total Size (MB): 1.73
----------------------------------------------------------------
損失関数
平均二乗誤差を採用しています。
式は以下の通りです
$ MSE = \frac{1}{N}\sum^{N}_{n=1}(p_i - y_i)^2 $
モデルで生成した画像と高解像度画像のピクセル値の二乗誤差を最小にするように学習します
学習
モデルに通す前に画像をバイキュービック補間で拡大する必要があります。
拡大する方法は以下のようにResize時に使用する拡大法をバイキュービック補間に指定するだけです
transforms.Resize((64,64), interpolation="bicubic")
学習自体は特に特別なことは行いません
srcnn.train()
criterion = nn.MSELoss()
for epoch in range(epoch_num):
for train,data in dataloader:
train = train.to(device)
data = data.to(device)
optimizer.zero_grad()# 勾配をゼロに設定
prediction = srcnn(train)# 予測
loss = criterion(prediction, data)# 損失の計算
loss.backward()# 誤差を逆伝搬させる
optimizer.step()# 勾配降下法を用いての学習
補足
画像の補完について
最近傍補間(ニアレストネイバー Nearest neighbor)
- 最も近い座標の画素値を求めたい座標の画素値とすること
- $ Dst(x,y) = Src([x+0.5], [y+0.5]) $
- Dst(x,y):任意の座標の画素値
- Src(x,y):元々の画像の画素値
- x+0.5:xに0.5を足して切り捨てる
- y+0.5:yに0.5を足して切り捨てる
双一次補間(バイリニア補間 Bilinear)
- 周辺4画素をもとに直線的に近似します
- x方向、y方向に対して以下のように求めたい座標に挟んでいる座標の画素値の比率を求めることで近似します
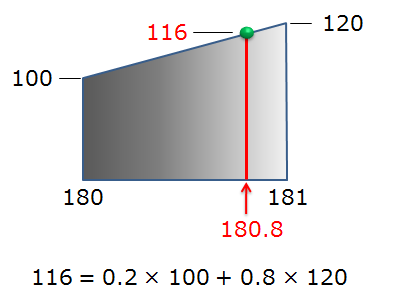
図は画素の補間(Nearest neighbor,Bilinear,Bicubic)より
双三次補間(バイキュビック補間 Bicubic)
- 周辺16画素をもとに三次式で補完して画素値を求めます
- 先ほどまでは、求めたい座標に挟んでいる座標の画素値の比率をもとに画素値を求めていましたが、比率ではなく周辺画素値をもとに曲線的に求めることで画素値を近似します
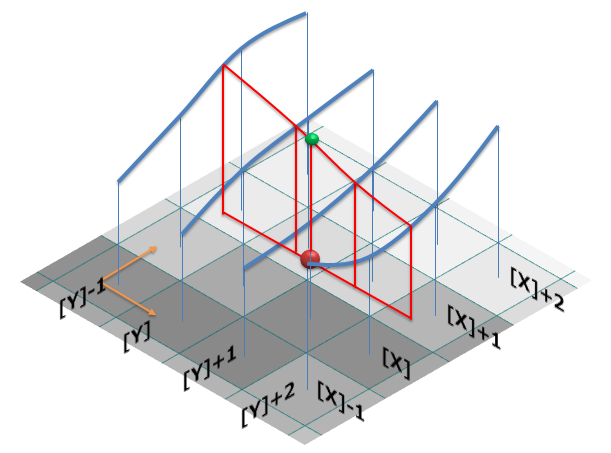
図は画素の補間(Nearest neighbor,Bilinear,Bicubic)より
解像度とは
画像の密度のことです。
単位はdpi(dot per inch)となり、「一インチにどれだけドットが含まれているか?」という意味になります
解像度が高いということは、1インチあたりにおけるドット数が多いと同意義になります
例として、10dpiと20dpiでは20dpiのほうが高解像度となります