論文紹介・画像引用・GIF引用
NVIDIAより2019.3.18提出
https://arxiv.org/pdf/1903.07291v1.pdf
https://github.com/NVlabs/SPADE
https://www.youtube.com/watch?v=MXWm6w4E5q0&feature=youtu.be
https://gadgets.evolves.biz/2019/03/20/nvidia_smartpaintbrush/
本研究について
・セマンティックセグメンテーションマスクからリアルな画像への変換
・エンコーダーを使うことでスタイルの選択も可能
・SPADE(後述)という正規化層を加えることによって、少ないパラメータで意味情報を捉えた画像合成ができるようになった
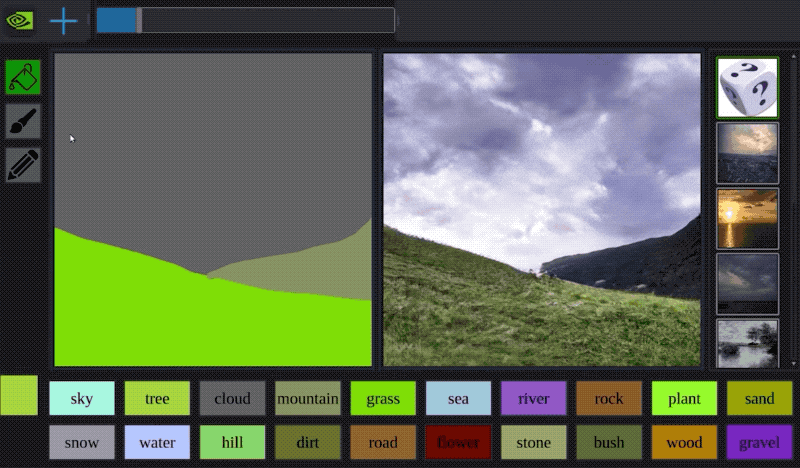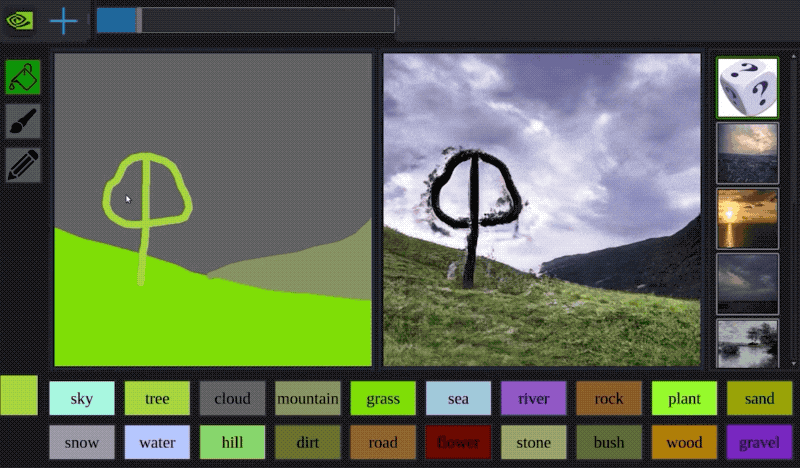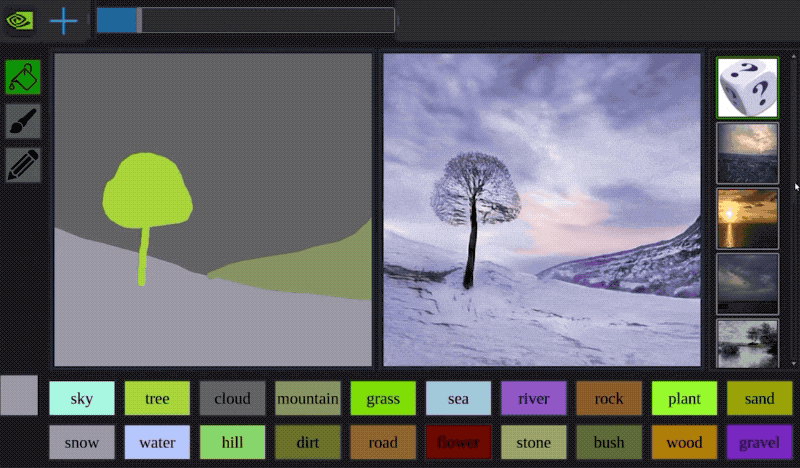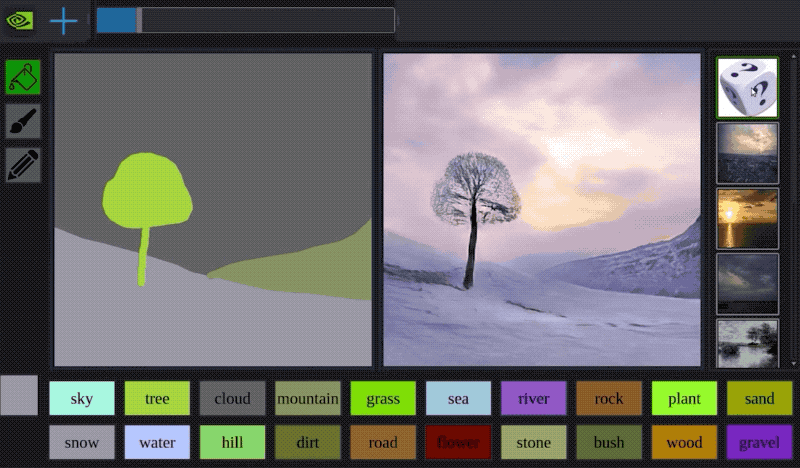
欲しい画像を簡単につくれる

・ユーザーがセグメンテーションマスクを描くことで、それに対応する画像を生成することができる
・画像の全体的な見た目を調整するために、スタイル画像の選択もできる
これは入力のノイズをimage encoderによって計算されたスタイル画像の埋め込みベクトルにすることで可能になる(後述)
SPADE
SPatially-Adaptive (DE)normalization →SPADE
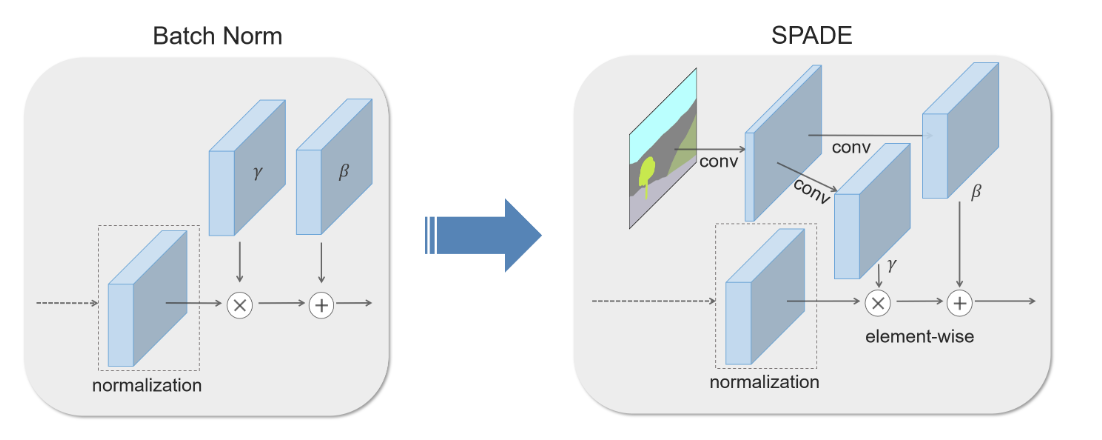
SPADEの流れ
①出力をチャンネルごとに正規化する(上図のnormalization)
②セマンティックマスクから計算された$\gamma$と$\beta$で各ピクセルの値をスケーリング・バイアスをかける(上図のelement-wise)
パラメータ(γとβ)の特徴
$\gamma_{c,y,x}^{i}(m)$と$\beta_{c,y,x}^i(m)$について
・学習によって得られるパラメーター
・位置($c,y,x$)によって異なる値を持てる
・$\gamma$と$\beta$はセグメンテーションマスクから計算されるため、意味情報を合成画像に加えることができる
計算式から見るSPADE
$n\in{N},c\in{C^i},y\in{H^i},x\in{W^i}$での出力の値は以下のようになる
i番目の層の出力を正規化(平均を引いて標準偏差で割る)して、$\gamma$でスケーリング、$\beta$でバイアスをかけている
$$\gamma_{c,y,x}^{i}(m)\frac{h_{n,c,y,x}^i-\mu_c^i}{\sigma_c^i}+\beta_{c,y,x}^i(m) (1)$$
$m$:セマンティックセグメンテーションマスク
$N$:バッチサイズ
$h^i$:i番目のconvolution層の正規化前の出力
$C^i$:i番目のconvolution層のチャンネル
$H^i・W^i$:i番目のconvolution層の出力マップの高さと幅
$\mu_c^i$:チャンネル$c$の平均
$\sigma_c^i$:チャンネル$c$の標準偏差
平均と標準偏差を求める式は下記のようになる
$$\mu_c^i=\frac{1}{NH^iW^i}\sum_{n,y,x}h_{n,c,y,x}^i (2)$$
$$\sigma_c^i=\sqrt{\frac{1}{NH^iW^i}\sum_{n,y,x}(h_{n,c,y,x}^i)^2-(\mu_c^i)^2} (3)$$
SPADEの構成
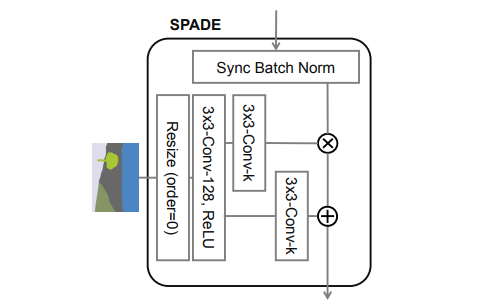
3x3-Conv-k:3×3のフィルタ、フィルタセット数(出力のチャンネル数)が$k$の意味
$\gamma$の要素積と$\beta$の要素和ができるように、セグメンテーションマップをnearest-neighborダウンサンプリングでリサイズして解像度を合わせる
SPADEと既存の正規化層の関係
SPADEを少し変えると既存の正規化層になる
Conditional Batch Normalization層
①セグメンテーションマスク$m$をクラスラベルに変える
②パラメーターを空間不変にする
\gamma_{c,y1,x1}^{i}\equiv\gamma_{c,y2,x2}^{i}, \beta_{c,y1,x1}^i\equiv\beta_{c,y2,x2}^i, \\y_{1},y_{2} \in {\{1,2,...,H^{i}\}}, x_{1},x_{2} \in {\{1,2,...,W^{i}\}}
→SPADEからConditional BN層になる
AdaIN
①セグメンテーションマスクを画像に変える
②パラメーターを空間不変にする
③バッチサイズを1にする
→SPADEからAdaINになる
SPADE generator
入力:セマンティックマスクとランダムベクトル → 出力:画像
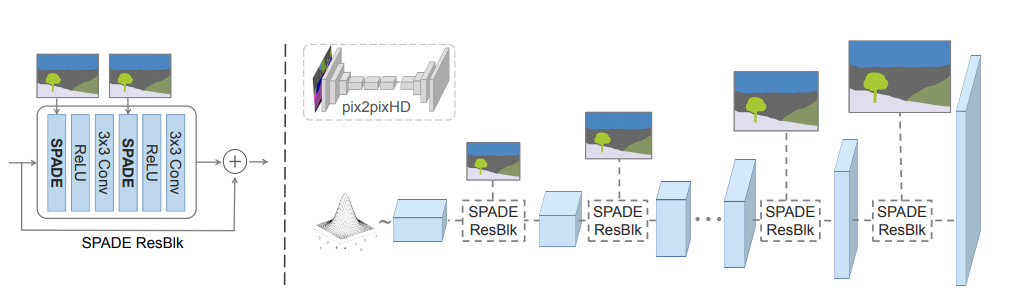
SPADEの$\gamma$と$\beta$がセグメンテーションマスクの意味情報をエンコードしているため、generatorの入力層にはセグメンテーションマスクを与える必要はない
そのため、SPADEを使うgeneratorはエンコーダーがない形でも使える
→パラメータ数が減る
入力として受け取るランダムベクトルは生成画像の多様性を生み出す役割を持つ
SPADE ResBlkの構成
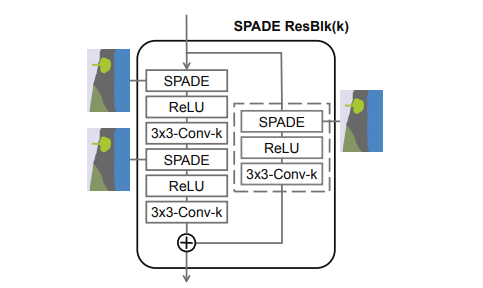
ResBlkの前後でチャンネル数が変わった場合でも足し合わせができるように、スキップ構造にもconvolution層を使う
SPADE generatorの構成
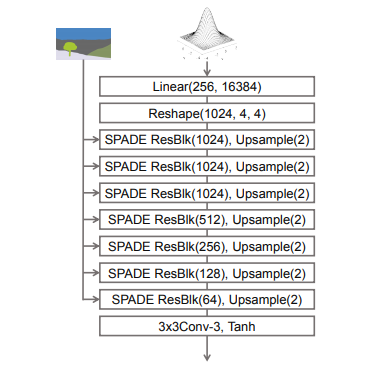
・入力はランダムベクトル
・セマンティックマスクは入力層に与えるのではなく、各SPADE ResBlkに与える
・nearest neighborアップサンプリングを使って解像度を大きくしていく
SPADEの良いところ

SPADE:意味情報を捉えたテクスチャを生成
pix2pixHD:正規化層による意味情報の損失により、入力の内容に関係なく同じ出力になる
一様なセグメンテーションマスク(上図のような画像全体が同じ意味情報のとき)に従来の様な正規化層が適用されると、意味情報を洗い流してしまう傾向がある
従来の正規化層が良くない理由
例)上図のような単一のラベルからなるセマンティックマスクの入力を
convolutionと正規化層のモジュールで処理する場合を考えてみる
①convolotion層
convolution層で入力が処理されても、同じラベルは同じ値になる
今回の場合は一様な入力のため、すべてのピクセルが同じ値を持つ
イメージ)skyが入力=すべてのピクセルの値が5、grassが入力=すべてのピクセルの値が10
②従来通りの正規化層
①の出力を正規化する(平均を引いて標準偏差で割る)
skyの場合
すべての値が5のため、平均も5 → 正規化後の値は0になる
grassの場合
すべての値が10のため、平均も10 → 正規化後の値は0になる
正規化された値は、セマンティックラベルが何であってもすべての値が0になってしまう
=意味情報を失っている
意味情報を捉えるSPADE
SPADEを使ったgeneratorの場合は
前回の出力だけが正規化されて、SPADEの入力であるセグメンテーションマスクは正規化されない
→正規化と意味情報の反映の両立が可能
多様な画像合成

入力:セマンティックマスクとランダムベクトル(スタイル画像をエンコードしたもの)→出力:画像
エンコーダーとSPADEありのgeneratorを組み合わせることで上図の様な画像合成ができる
セグメンテーションマップの中にある画像は本物画像
画像合成の流れ
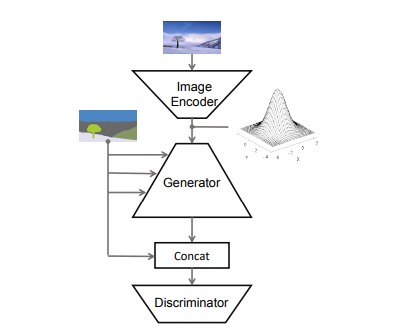
①Image Encoderが入力画像を潜在表現にエンコードする
誤差逆伝播ができるようにreparameterization trickを使うため、平均と分散を出力とする
②reparameterization trickでサンプリングした潜在表現をgeneratorの入力とする
③generatorの各SPADE ResBlkへセグメンテーションマスクを入力する
④discriminatorはセグメンテーションマスクとgeneratorの出力をconcatenationしたものを入力にして、偽物として識別することを目的とする
Image Encoder
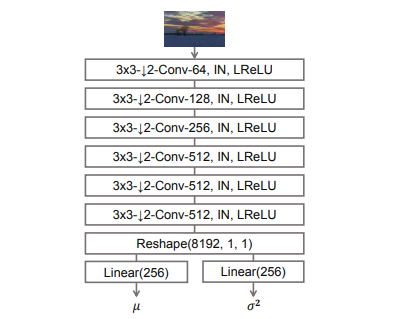
・本物画像を平均$\mu$と分散$\sigma^2$にエンコード
・画像のスタイルを捉える
・Image Encoderありのフレームワークの時は、目的関数にKL Divergenceを加える
$$L_{KLD}=D_{KL}(q(z|x)||p(z))$$
$p(z)$:事前分布・ガウス分布
$q(z|x)$:学習によって得られる平均と分散から決められる分布・xを生み出すzの分布
Generator
・reparameterization trickによって計算されたランダムベクトルを入力とする
・エンコードされたスタイルとSPADEから得られるセマンティックマスクの意味情報を組み合わせた画像を生成する
・nearest neighborアップサンプリングを使って解像度を大きくしていく
Discriminator

・セグメンテーションマップと画像をconcatenationしたものを入力とする
・PatchGAN(パッチごとに本物かどうかの識別をする)に基づいたdiscriminatorのため、最終層はconvolution層になる
・マルチスケールdiscriminatorを使う
実験
データセット
・COCO-Stuff
・ADE20K
・ADE20K-outdoor
・Cityscapes
・Flickr Landscapes
評価指標
合成画像に対してセマンティックセグメンテーションを実行し、予測マスクが正解マスク(入力)とどのくらい合致しているかを比べる
リアルな合成画像であれば、学習済みのセマンティックセグメンテーションモデルは正解と同じラベル予測をするはず
セグメンテーションの精度を測るために以下の指標を使う
・mean Intersection-over-Union (mIoU)
・pixel accuracy (accu)
合成画像と本物画像の分布の距離を測るために以下の指標を使う
・Frechet Inception Distance (FID)
ベースライン
・pix2pixHD
GANベースの条件付き画像合成のSOTA
・CRN
低解像度から高解像度まで繰り返し出力を調整するディープネットワークを使用
・SIMS
本物画像からセグメントを合成し、境界を調整するセミパラメトリックアプローチ
スコア比較

・すべてのデータセットで現在のSOTAであるpix2pixHDを大幅に上回るスコアになっている
SIMSのFIDスコアが良い理由
SIMSでは本物画像のデータセットからの画像パッチをつなぎ合わせることで画像合成を行っている
→本物画像のパッチを使っているため、合成画像の分布は本物画像の分布と合致しやすい
SIMSのセグメンテーションスコアが悪い理由
画像を生成する上で欲しいパッチ(例えば特定のポーズをとっている人)がデータセット内に存在しないこともある
→意味情報が異なるオブジェクトをコピーする傾向
画像比較


・本研究の生成画像は鮮明でリアルな画像になっている
・SIMSもきれいな画像が生成できているが、入力ラベルの意味情報を反映できていない(プールの形が変わってしまっている)
他にも以下のような多様な画像が生成できている


人間が合成画像を見て評価した場合
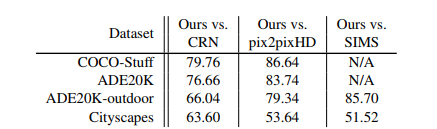
上表の数字はユーザーが本研究の方法による合成画像を選んだ割合を表す
すべてのデータセットでユーザーは本研究の方法による合成画像を選ぶ確率が高い
評価手順とルール
Amazon Mechanical Turk (AMT) を利用する
①被験者にセグメンテーションマスクと異なる方法から合成された2枚の画像(例:OursとCRN)を見せる
②セグメンテーションマスクと適切に対応している方を選んでもらう
・被験者は時間制限なく画像選択ができる
・各データセットで500の質問をランダムに作る
・各質問を異なる5人に答えてもらう
・タスク承認率が98%以上の人のみ参加できる
SPADEの効果
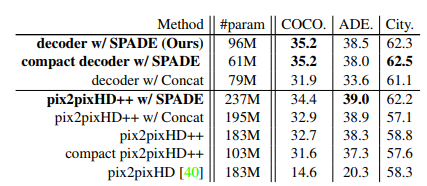
それぞれのモデルのmIoUスコア
pix2pixHD++ : pix2pixHDの性能を高めるすべての手法(SPADEを除く)を組み合わせたモデル
pix2pixHD++ w/ Concat : セグメンテーションマスクを中間層でチャンネル方向にconcatenationして入力するモデル
pix2pixHD++ w/ SPADE : pix2pixHD++とSPADEを組み合わせたモデル
compact ~ : ~のモデルのチャンネル数を減らしてパラメーター数を減らしたもの
・本研究提案のデコーダーのみのアーキテクチャでもpix2pixHD++(エンコーダーとデコーダーで構成されている)でもSPADEを追加することで性能が上がっている
・concatenationの方法ではSPADEと同様の効果は得られない
・本研究提案のデコーダー(SPADEあり)は少ないパラメーターであってもpix2pixHD++(SPADEなし)を上回る性能になる
SPADE generatorの構成を変えた場合
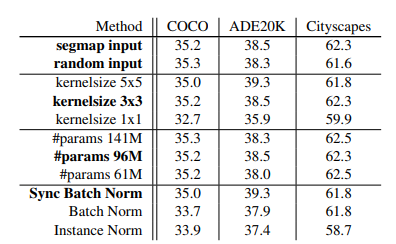
①generatorへの入力
ランダムノイズかダウンサンプリングしたセグメンテーションマップ
どちらを選択しても同じ性能
→ SPADEだけでセグメンテーションマップの情報は十分得られていることがわかる
②SPADE前の正規化層
どの正規化層でも上手く機能する
③セグメンテーションマップに使うカーネルサイズ
1×1のカーネルを使うとラベルに関しての広範な情報が利用できないため性能が落ちる
④generatorのパラメーター数
convolution層のフィルタセット数(チャンネル数)を減らすことで調整
モデルの大きさに関わらず高い性能になっている
まとめ
・SPADEを用いることでセマンティックマップの意味情報を失わなくなるため、屋内・屋外・風景・街路などあらゆるシーンの画像をリアルに生成することができる
・ユーザーがセマンティックマップを描くことで、それに対応した画像を生成できる
・スタイルの選択もできるため、より多様な画像になる