ResNet実装
ボトルネック、ピラミッドなどは含んでいないシンプルなもの
含んだもののコードは後述
def _shortcut(inputs, residual):
# _keras_shape[3] チャンネル数
n_filters = residual._keras_shape[3]
# inputs と residual とでチャネル数が違うかもしれない。
# そのままだと足せないので、1x1 conv を使って residual 側のフィルタ数に合わせている
shortcut = Convolution2D(n_filters, (1,1), strides=(1,1), padding='valid')(inputs)
# 2つを足す
return add([shortcut, residual])
def _resblock(n_filters, strides=(1,1)):
def f(input):
x = Convolution2D(n_filters, (3,3), strides=strides,
kernel_initializer='he_normal', padding='same')(input)
x = BatchNormalization()(x)
x = Activation('relu')(x)
x = Convolution2D(n_filters, (3,3), strides=strides,
kernel_initializer='he_normal', padding='same')(x)
x = BatchNormalization()(x)
return _shortcut(input, x)
return f
def resnet():
inputs = Input(shape=(32, 32, 3))
x = Convolution2D(32, (7,7), strides=(1,1),
kernel_initializer='he_normal', padding='same')(inputs)
x = BatchNormalization()(x)
x = Activation('relu')(x)
x = MaxPooling2D((3, 3), strides=(2,2), padding='same')(x)
x = _resblock(n_filters=64)(x)
x = _resblock(n_filters=64)(x)
x = _resblock(n_filters=64)(x)
x = MaxPooling2D(strides=(2,2))(x)
x = _resblock(n_filters=128)(x)
x = _resblock(n_filters=128)(x)
x = _resblock(n_filters=128)(x)
x = GlobalAveragePooling2D()(x)
x = Dense(10, kernel_initializer='he_normal', activation='softmax')(x)
model = Model(inputs=inputs, outputs=x)
return model
model = resnet()
adam = Adam()
model.compile(optimizer=adam, loss='categorical_crossentropy', metrics=['accuracy'])
model.summary()
ResNet, Wide ResNet, PyramidNet
色々な名前がついているが、層の枚数とフィルターの数を変えただけ
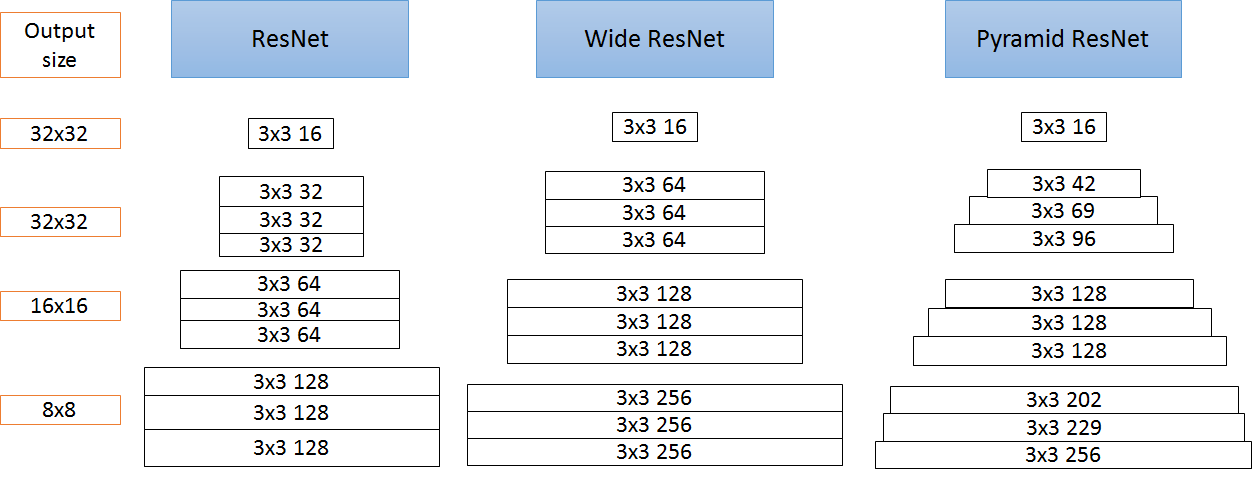
PyramidNet(Bottleneck)
x = _resblock(n_filters1=8, n_filters2=32)(x)
x = _resblock(n_filters1=12, n_filters2=48)(x)
x = _resblock(n_filters1=16, n_filters2=64)(x)
x = _resblock(n_filters1=20, n_filters2=80)(x)
x = _resblock(n_filters1=24, n_filters2=96)(x)
x = _resblock(n_filters1=28, n_filters2=112)(x)
x = _resblock(n_filters1=32, n_filters2=128)(x)
x = _resblock(n_filters1=36, n_filters2=144)(x)
x = _resblock(n_filters1=40, n_filters2=160)(x)
x = MaxPooling2D(strides=(2,2))(x)
x = _resblock(n_filters1=44, n_filters2=176)(x)
x = _resblock(n_filters1=48, n_filters2=192)(x)
x = _resblock(n_filters1=52, n_filters2=208)(x)
x = _resblock(n_filters1=56, n_filters2=224)(x)
x = _resblock(n_filters1=60, n_filters2=240)(x)
x = _resblock(n_filters1=64, n_filters2=256)(x)
Bottleneckアーキテクチャ

Bottleneckアーキテクチャのいいところ
・パラメータを少なくできる
左図のパラメーター数:336464+336464≒70k
右図(ボトルネック)のパラメーター数:25664+643364+64*256≒70k
ボトルネックにすることで64dimとほぼ同じパラメーター数で256dimを使える
def _resblock(n_filters1, n_filters2, strides=(1,1)):
def f(input):
x = Convolution2D(n_filters1, (1,1), strides=strides,
kernel_initializer='he_normal', padding='same')(input)
x = BatchNormalization()(x)
x = Activation('relu')(x)
x = Convolution2D(n_filters1, (3,3), strides=strides,
kernel_initializer='he_normal', padding='same')(x)
x = BatchNormalization()(x)
x = Activation('relu')(x)
x = Convolution2D(n_filters2, (1,1), strides=strides,
kernel_initializer='he_normal', padding='same')(x)
x = BatchNormalization()(x)
return _shortcut(input, x)
return f
モジュール
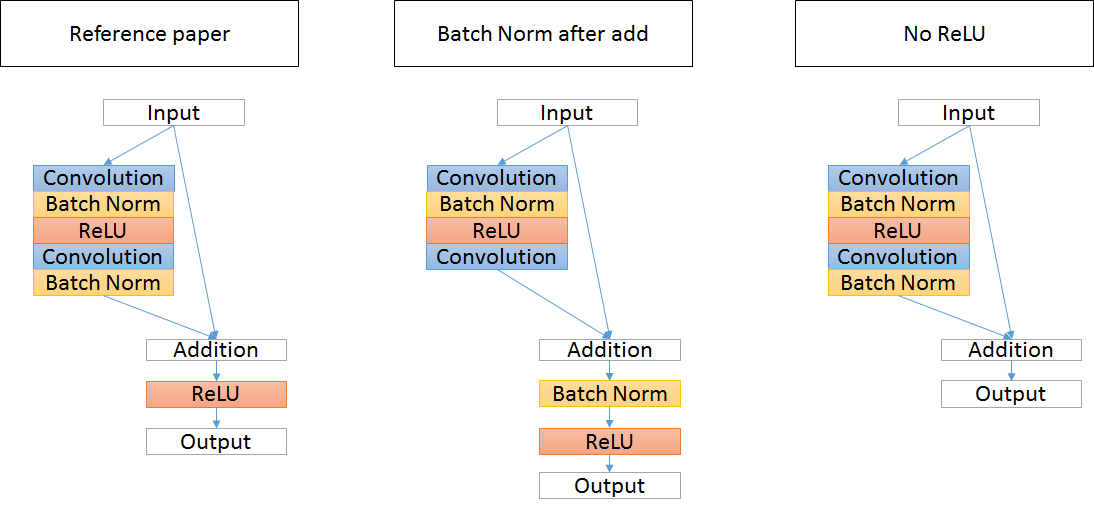
Reference paperの形よりもNo ReLUの形の方が良いらしい
実際に比較してみた(どちらもピラミッド型でボトルネック)データ:cifar10
Reference paper
モジュール(Reference paper)
def _resblock(n_filters1, n_filters2, strides=(1,1)):
def f(input):
x = Convolution2D(n_filters1, (1,1), strides=strides,
kernel_initializer='he_normal', padding='same')(input)
x = BatchNormalization()(x)
x = Activation('relu')(x)
x = Convolution2D(n_filters1, (3,3), strides=strides,
kernel_initializer='he_normal', padding='same')(x)
x = BatchNormalization()(x)
x = Activation('relu')(x)
x = Convolution2D(n_filters2, (1,1), strides=strides,
kernel_initializer='he_normal', padding='same')(x)
x = BatchNormalization()(x)
x = _shortcut(input, x)
# 唯一の違い
x = Activation('relu')(x)
return x
return f
Train on 40000 samples, validate on 10000 samples
Epoch 1/30
40000/40000 [==============================] - 135s 3ms/step - loss: 1.7784 - acc: 0.3414 - val_loss: 2.2185 - val_acc: 0.3103
Epoch 2/30
40000/40000 [==============================] - 121s 3ms/step - loss: 1.4657 - acc: 0.4650 - val_loss: 1.8569 - val_acc: 0.3590
Epoch 3/30
40000/40000 [==============================] - 122s 3ms/step - loss: 1.3146 - acc: 0.5253 - val_loss: 1.5861 - val_acc: 0.4394
.
.
.
Epoch 28/30
40000/40000 [==============================] - 124s 3ms/step - loss: 0.2116 - acc: 0.9250 - val_loss: 1.0974 - val_acc: 0.7137
Epoch 29/30
40000/40000 [==============================] - 122s 3ms/step - loss: 0.1917 - acc: 0.9318 - val_loss: 1.3378 - val_acc: 0.6849
Epoch 30/30
40000/40000 [==============================] - 131s 3ms/step - loss: 0.1941 - acc: 0.9319 - val_loss: 1.3868 - val_acc: 0.6912
val_loss: 1.3868 - val_acc: 0.6912
No ReLU
ボトルネックのコードと同じ
Train on 40000 samples, validate on 10000 samples
Epoch 1/30
40000/40000 [==============================] - 122s 3ms/step - loss: 1.5614 - acc: 0.4512 - val_loss: 1.5788 - val_acc: 0.4619
Epoch 2/30
40000/40000 [==============================] - 110s 3ms/step - loss: 1.2226 - acc: 0.5624 - val_loss: 1.3885 - val_acc: 0.5488
Epoch 3/30
40000/40000 [==============================] - 110s 3ms/step - loss: 1.0699 - acc: 0.6214 - val_loss: 1.2827 - val_acc: 0.5484
.
.
.
Epoch 28/30
40000/40000 [==============================] - 110s 3ms/step - loss: 0.3541 - acc: 0.8751 - val_loss: 0.8645 - val_acc: 0.7408
Epoch 20/30
40000/40000 [==============================] - 109s 3ms/step - loss: 0.3389 - acc: 0.8801 - val_loss: 0.8503 - val_acc: 0.7324
Epoch 30/30
40000/40000 [==============================] - 117s 3ms/step - loss: 0.3314 - acc: 0.8836 - val_loss: 0.7224 - val_acc: 0.7861
val_loss: 0.7224 - val_acc: 0.7861