初めに
今回はSVMを使って世界人口を予想しようと思います。
前回、pythonで世界経済を予想するという記事を書いたのですが、これは一次関数が当てはまってSVMでやる意味がないように思えたので、よい題材を探しました。
世界人口は近年(と言ってもここ100年くらい)急激に増加しており、一次関数が当てはまらないと思われます。
データを手に入れる
こちらのpdfに世界人口の推移が載っていますのでこれを使います。
今回は古いデータを含めると学習がうまくいかなかったので1850年
より前のデータは含めませんでした。
ソースコード
pythonで世界経済を予想するを元に作りました。
import sys
from sklearn.svm import SVC
from sklearn import svm
import numpy as np
import copy
import matplotlib.pyplot as plt
from sklearn.model_selection import GridSearchCV
from sklearn.kernel_ridge import KernelRidge
from sklearn.metrics.pairwise import rbf_kernel
from sklearn.linear_model import Ridge
args = sys.argv
def regression_main():
# model = svm.SVR(kernel='rbf', C=1e3, gamma=0.1)
data=[]
with open(args[1],"r",encoding="utf-8") as f:
data=[e.replace("\n", "") for e in f.readlines()]
data=[[float(e) for e in e.split(",")] for e in copy.deepcopy(data) ]
in_data=[e[:-1] for e in data]
label_data=[e[-1] for e in data]
print(in_data,label_data)
tuned_parameters = [
{'kernel': ['rbf'], 'gamma': [10**i for i in range(-6, 6)], 'C': [3]}#,
# {'kernel': ['linear'], 'C': [1, 10, 100, 1000]}
]
# model = GridSearchCV(svm.SVR(), tuned_parameters, verbose=1,cv=5, scoring="mean_squared_error")
model =svm.SVR(kernel='rbf',gamma=0.00001,C=1e3)
model.fit(in_data,label_data)
plt.scatter([e[0] for e in in_data], [e for e in label_data])
test_in_data=[[e] for e in range(int(min([e[0] for e in in_data])),int(max([e[0] for e in in_data])),1)]
# test_in_data=[[e] for e in range(2100)]
plt.plot([e[0] for e in test_in_data], model.predict(test_in_data))
plt.show()
while True:
user_input=input("end?>")
if user_input=="end":break
user_in_data=[]
for i in range(len(in_data[0])):
t=float(input(">"))
user_in_data.append(t)
print(model.predict([user_in_data])[0])
def main():
print("1:label\n2:回帰")
n=int(input(">"))
if n==1:
#label_main()
if n==2:
regression_main()
上記を実行すると、
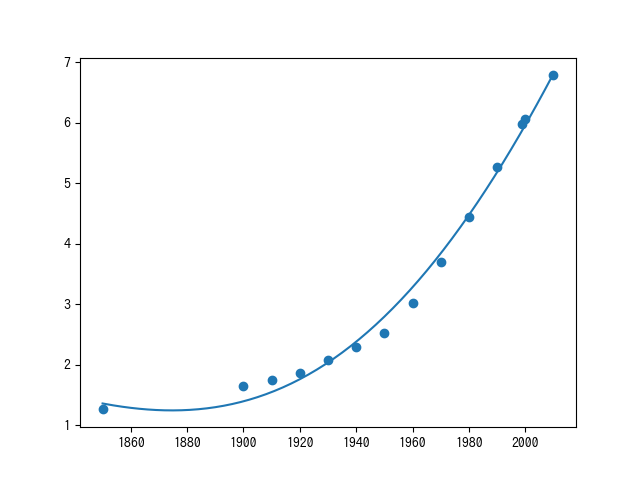
こうなりました。
一次関数は当てはまらない形になっています。
予想する
2050と入力してみます。
結果は10.8245358213と出てきました。(単位は10億人です。つまり108億2453万5821人のことです)
国連が予測では98億人なので誤差はありますが予想できました。
まとめ
今回はSVMを使った意味がありました。
このモデルだと2100年はうまく予想できませんでした。
本来、SVMなどを使わず、ロジスティック方程式などを活用したほうが良かったと思います。