背景
最近Ryzen 9 7950xを載せたPCを作ったのですが思ったより数値計算の速度が出なかったので、よく出てくる基本的な演算性能を調べてみました。今回は巨大なベクトルの内積の計算速度を対象とします。なお筆者はHigh-performance computingの専門家ではないので以下には間違いが含まれているかもしれません。
測定対象
10億次元のベクトルの内積を倍精度で計算する以下のプログラムの計算速度を測ります。特にOpenMPを用いた並列化のよりどの程度速くなるかを主眼としています。
#include <vector>
#include <iostream>
#include <omp.h>
#include <chrono>
#include <ios>
#include <iomanip>
template<typename RealType>
void vec_inner_prod(const std::int64_t dim, const std::int32_t num_thread) {
std::vector<RealType> vv(dim);
RealType val = 0.0;
#pragma omp parallel for num_threads(num_thread)
for (std::int64_t i = 0; i < dim; ++i) {
vv[i] = static_cast<RealType>(i)/dim;
}
const auto start = std::chrono::system_clock::now();
#pragma omp parallel for reduction(+: val) num_threads(num_thread)
for (std::int64_t i = 0; i < dim; ++i) {
val += vv[i]*vv[i];
}
const std::chrono::duration<double> elapsed_seconds = std::chrono::system_clock::now() - start;
std::cout << std::setfill('0') << std::right << std::setw(2) << std::fixed << std::setprecision(5);
std::cout << num_thread << " " << elapsed_seconds.count() << "[sec]: " << val << std::endl;
}
int main() {
const std::int64_t dim = 1000000000;
const auto max_threads = omp_get_max_threads();
for (std::int32_t r = 1; r <= max_threads; ++r) {
vec_inner_prod<double>(dim, r);
}
}
実行環境
ちょうど手元にあった以下のPCを用いて上記内積計算の速度を測定しました。
| CPU | コア数 | メモリ | メモリ帯域幅 | |
|---|---|---|---|---|
| 自作PC | Ryzen 7950x | 16 core 32 threads | DDR5-5600 32GB×2 | 89.6 GB/sec |
| Mac Studio | Apple M1 Max | 10 core 10 threads | 64GB | 400 GB/sec |
| MacBook Air | Apple M2 | 8 core 8 threads | 16GB | 100 GB/sec |
| MacBook Pro | Intel Core i7 | 4 core 8 threads | LPDDR4X-3733 32GB | 59.7 GB/sec |
MacBook Proは2020年モデルです。
OSについては自作PCのみUbuntu 22.04.1 LTSで、他は全てMacOS 13.1です。
結果
コンパイラ
コンパイルは
- 自作PC:
g++ -std=c++17 -O3 -fopenmp - Mac:
g++ -std=c++17 -O3 -Xpreprocessor -fopenmp -lomp
としました。g++ -vを叩くと、
- 自作PC:
gcc version 11.3.0 - Mac:
Apple clang version 14.0.0
と表示されます。
計算速度
スレッド数ごとの計算速度です。
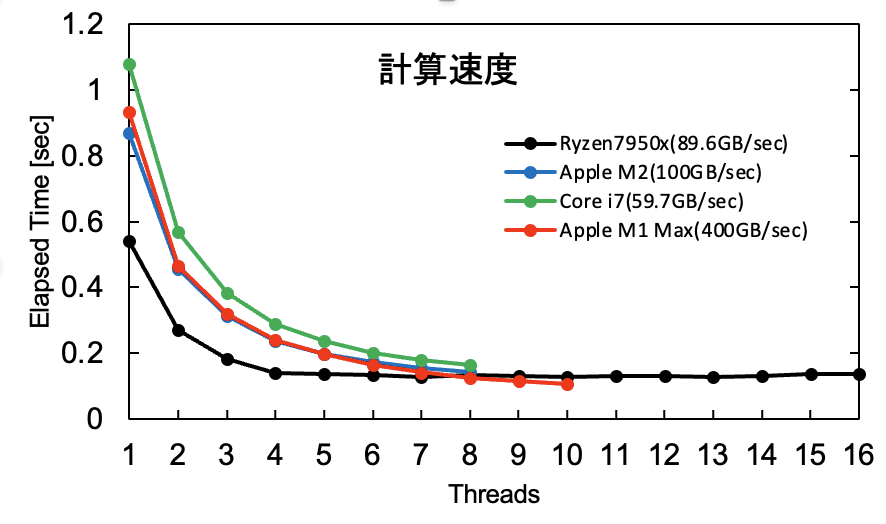
シングルスレッドではRyzen 7950x < M2 < M1 Max < Core i7の順に速く、順当にCPUの性能が反映されているようです。
マルチスレッドではRyzen 7950xが4スレッドでサチっていてそれ以上スレッドを増やしても速度が上がっていません。
9並列あたりでM1 Maxに抜かれています。メモリ速度がボトルネックになっているのかもしれません。
Ryzen 7950xはスレッド数を増やしていくと、おおよそ0.13 secに収束しており、10億次元の倍精度配列をこの速度で読みだしたとすると、1*8 GB/0.13 sec=61.5 GB/secとなり、理論性能が89.6 GB/secなのでだいたいこんなもんなのかもしれせん。一方でApple M1 Maxは理論性能が400 GB/secあるはずなのでまだ余裕があるはずです。
以下にシングルスレッドに対する速度向上率を示します。
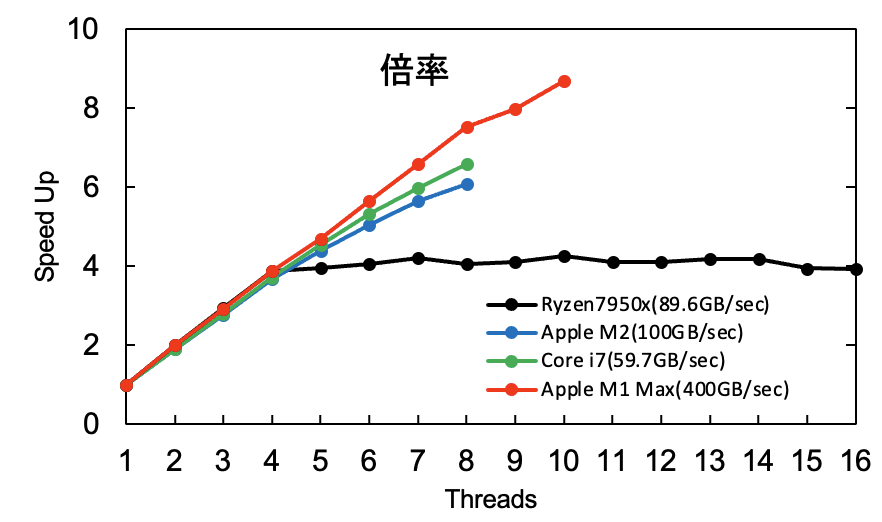
確かにRyzen 7950xは4スレッドでサチっています。M1 Maxが一番並列化による性能が出てますね。
Core i7は4コアしかないですが、それ以上増やしてもちゃんと計算速度が速くなっています。
また、M2はPコア4のEコア4なのでわずかに4スレッド辺りから伸びが鈍化しているようにも見えます。
同じことがPコア8のEコア2のM1 Maxでも見えるようです。
次に、コンパイルの最適化を上げて、
- 自作PC:
g++ -std=c++17 -Ofast -fopenmp - Mac:
g++-12 -std=c++17 -Ofast -fopenmp
とした場合の結果を見てみます。なおMacではg++(clang)に-Ofastを付けたら遅くなったので、Homebrewで入れたgccを使いました。
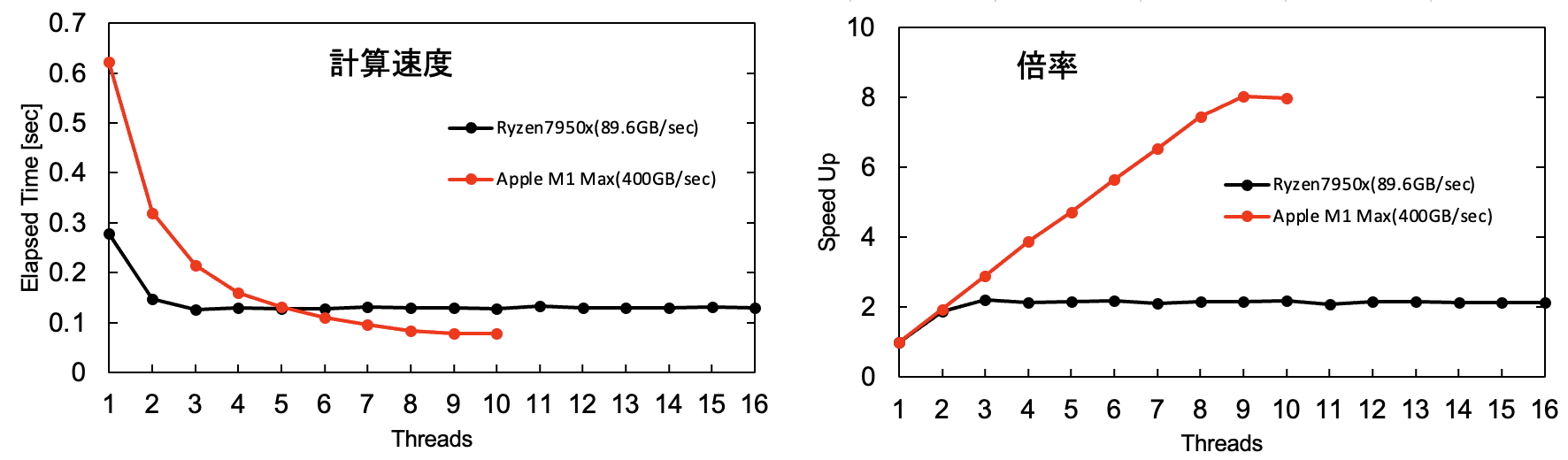
-Ofastにしたらシングルスレッドの性能が上がりました。しかし、Ryzen 7950xはやはり0.13 secくらいに収束しています。結局メモリ速度がボトルネックのようです。
6スレッドから完全にM1 Maxに抜かされています。
また、M1 Maxも9スレッド辺りでサチっています。これはEコアを使ったことが原因なのか定かではありませんが、先の結果ではEコアを使っても速度が向上していたことから、おそらくこちらもメモリ速度がボトルネックになっている可能性が高いと思います。
M1 Maxは最終的に0.077 sec程度に収束していますが、これはおおよそ104 GB/secで400 GB/secには到底及びません。
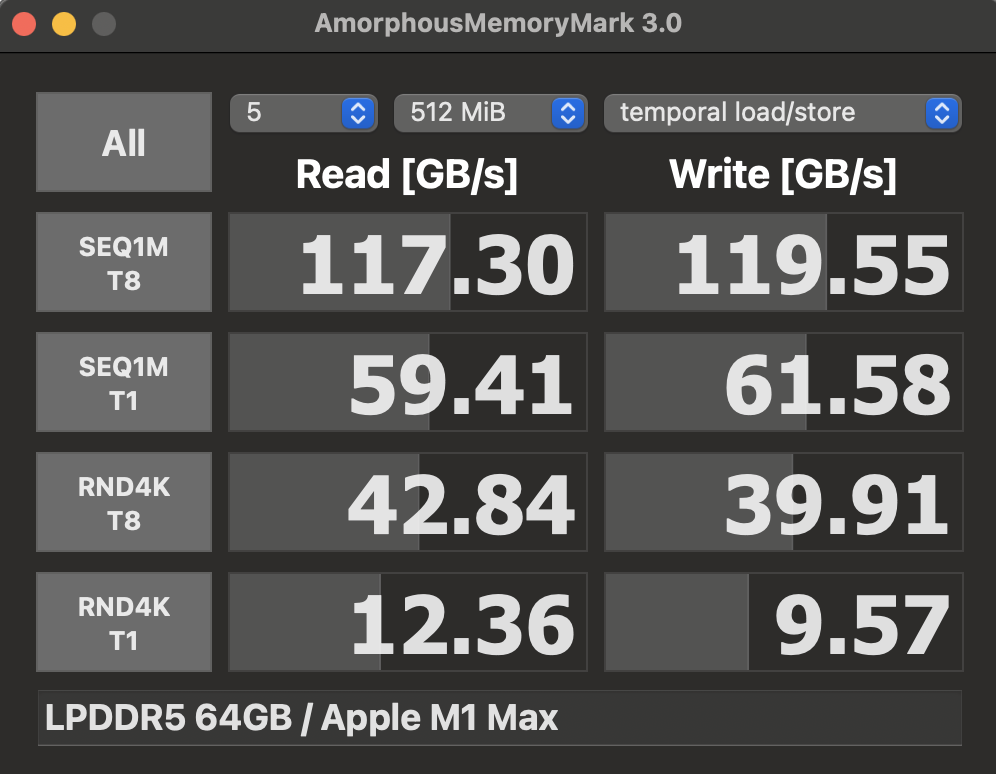
ただ、手元でAmorphousMemoryMarkによるベンチマークを取るとシーケンシャルリードがだいたいこの程度なので、これくらいが限界なのでしょうか。
終わりに
今までメモリ速度に注目したことは殆どなかったのですが、Apple Siliconすごいですね。
Macは値段が高いので数値計算用のPCとしてはコスパが悪いと思っていたのですが、
M1 Maxのメモリ帯域400 GB/secというのを自作PCで出そうと思うとDDR5-6400の8チャンネルが必要になるので、そう考えるとMac Studioはかなり安いのかもしれません。
M1 Ultraが欲しくなりました。これはメモリ帯域800 GB/secあるらしいので。
今回は、Ryzen 7950xが負けてしまいましたが、別の計算でモンテカルロシミュレーションを行ってみたところ、こちらはマルチコアの性能がかなり出ました。
内積計算は掛け算をしてるだけなので、ほとんどメモリで決まってしまうのかもしれません。
次は疎行列ベクトル積の性能評価もしてみたいですね。