1.はじめに
早速、下のHTMLをみて欲しい。
地獄のようなHTML。存在しないタグがあったり、入れ子はめちゃくちゃでエディタによってはエラーを吐きまくるだろう。
では、これを実際に動かすと?
<html>
<mytag>
</mytag>
<div>
<h3>
</div>
zigoku no HTML
</h3>
</html>
きっとh3の効いていない「zigoku no HTML」が表示される。
ツールを開けばタグが補完・修正されていることもわかる。Why???
この記事は、HTMLがなぜテキトーに書いても動くのかと思い、改めてHTMLのパーサーについて調べてみた記事です。
あとHamee Advent Calendar202011日目の記事です。
書いてあること
- HTMLのパーサー処理
- HTMLのトークン化アルゴリズム
書いてないこと
- HTMLの書き方的なこと
2.HTMLとは
まずはMDN web docs:HTMLの基本をみてみましょう。
HTML はプログラミング言語ではありません。マークアップ言語と言って、コンテンツの構造を決めるものです。 HTML は 要素 の集まりでできています。要素とは様々なコンテンツがどのように見えるか、またどのように動くかを表現するためにタグで囲まれたまとまりです。
そうです。HTMLはプログラミング言語ではなく、コンテンツの構造を示す「要素」の集まりなのです。
また、これらの要素は「開始タグ」「終了タグ」「コンテンツ」から構成されます。
<h3>hello qiita</h3>
- 開始タグ :
<h3> - 終了タグ :
</h3> - コンテンツ :
hello qiita
3.HTMLパーサー
HTMLは一般的なトップダウン・ボトムアップ構文解析では解析できません。
はじめにで記したように、HTMLパーサーはエラーを補完・修正します。
また、JavaScriptの影響で要素が追加されるため、再入可能である必要があります。
そういった解析の複雑さゆえ、HTML5では2つのアルゴリズムを用いて解析を行なっています。
- トークン化アルゴリズム
- ツリー構築
3.1.トークン化アルゴリズム
トークン化は字句解析で、与えられた字によって状態を遷移させトークンを作成していきます。
<h3>hello qiita</h3>
トークンが発行される流れは以下の通りです。
- 最初の状態は「データ状態」です。
- 「データ状態」で「<」が与えられると「タグオープン状態」へ遷移します。
- 「タグオープン状態」で文字列を与えると「タグネーム状態」となり、一定の文字列を処理していきます。
- 「タグネーム状態」で「>」を与えると「データ状態」へと戻り、トークンが発行されます。
このような動作がEOFまで続きます。
上のHTMLの場合、以下のように状態が遷移していきます。
本記事で上げた以外の状態もあります。興味のある方は参考資料2をご覧ください。
|与える文字列|状態|
|---|---|---|
| |データ状態
|<|タグオープン状態|
|h|タグネーム状態|
|3|タグネーム状態||
|>|データ状態(トークン発行)||
|h|文字トークン発行||
|e|文字トークン発行||
|.|文字トークン発行||
|a|文字トークン発行||
|<|タグオープン状態||
|/|閉じタグオープン状態||
|h|タグネーム状態||
|3|タグネーム状態||
|>|データ状態(トークン発行)||
|EOF|ファイル終了トークン発行||
3.2 ツリー構築アルゴリズム
トークン化アルゴリズムで発行されたトークンを用いて、ツリーを構築します。
そして、入れ子タグの不一致や閉じタグの修正も行われます。
実際に、「はじめに」で記載した地獄のHTMLでツリーが構築されるまでを見ていきます。
ツリー構築は初期挿入状態から始まります。
<html>を受け取るとDocumentオブジェクトを親として追加し、head前状態に移行します。
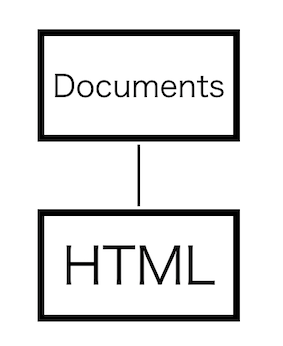
head前状態では、タグ名がhtml,headの開始タグがない場合、属性のない「head」開始タグトークンを挿入し、head後状態になります。
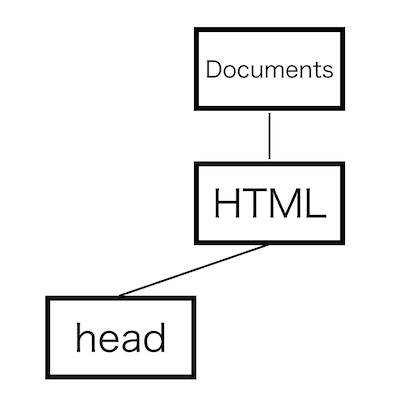
head後状態で<mytag>を受け取ると、「body」開始タグのトークンをHTMLに挿入し、「body内状態」に移行します。

「body内状態」では、様々なタグが処理されます。<mytag>のように従来存在しないタグの場合、フォーマットが宣言されていれば再構築します。
今回は宣言されていないため、再構築されないままノードに挿入し「body内状態」に戻します。
</mytag>mytag終了タグを受け取った際、現在のノードと同じ名前のタグのため、ポップし「body内状態」に戻ります。
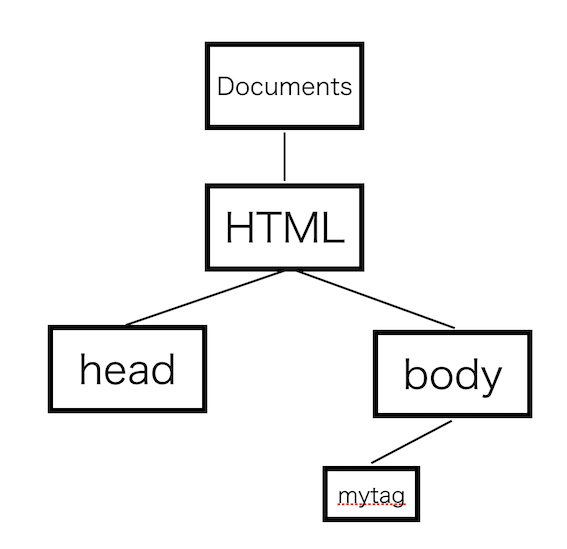
<div>、<h3>を受け取った際、先ほどのと同様にノードに挿入します。
</div>を受け取った際は、mytag終了タグとは異なる動きをします。
ツリーにはdiv開始タグとh3開始タグが連なっているため、div終了タグを挿入してもh3開始タグが間にあるためにHTMLにポップできないのです。
そのため、パーサーはこの間にある開始タグ全てに終了タグを作成し、ポップします。
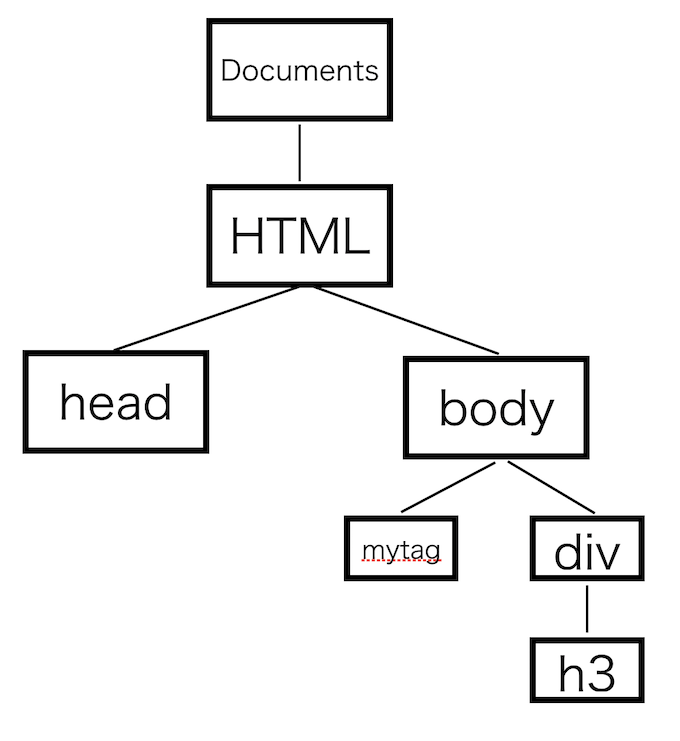
</h3>遅れてやってきた閉めタグですが、開始タグがすでにポップされツリーには無いので処理されません。
</html>を受け取った時、今回はbodyに閉じていないタグがないため「body後状態」に遷移します。
body後状態でEOLを受け取ると解析が終了します。お疲れ様でした。
おわりに
なぜHTMLのパーサーを読んでいたかと言えば、ブラウザのOSSを読もうとした時に「思えばWebブラウザって何してるの?」に端を発したものでした。
ブラウザのレンダリングフローもそうですが、こういった部分を理解するとめちゃくちゃ地味な高速化に使えたりするのでさらっと知っておくといいのかなーという感じます。ここまでやる必要はないですが。
あと今回のHTMLの補完みたいな、枯れた技術だからこそのよさってありますよね<sarcasm>。
ほぼ初記事をここまで読んでくださり、ありがとうございました。