FOSS4G Advent Calendar 2015 二個目 の記事での,2回目です。
1回目はこちら -> 初めてのCartoDB その1: shp と csv を読み込む
CartoDB と PostGIS
CartoDB は PostgreSQLというデータベース管理システムを基礎につくられています。
その PostgreSQL の空間情報拡張機能が PostGIS で,大きな空間情報に対して頑健な処理ができる点は DB ならではです。
また,SQL による再利用可能な処理の記述も魅力的です。
PostGIS の壁
しかし,PostGIS のインストールは OS によっては少し大変で,本来サーバの役割をするものなのでデータもその端末に縛られがちです。
また,描画機能がないため,QGIS 等の他のツールが必要になります。
CartoDB で始めよう
CartoDB であれば,webサービスを使えばインストールに悩む必要はなく,いろんな端末からアクセス可能です。
また,CSS で管理できる描画はとても洗練されています。
なので,CartoDB は PostGIS の API としてもおすすめなのです。
前回のあらすじ
埼玉県の行政区域の shp と いきものログのスズメ報告の csv を CartoDB に読み込みました。
また,テーブル結合の機能を使い,市区町村名で属性結合しました。
その際,行政区域データが区名だけなのに対し,スズメデータは市+区名で表現されているため,一部がうまく結合されず別の行になってしまいました。
そこで「その2」では,PostGISの機能を駆使して,データを思い通りに結合して,データの視覚化を行ってみます。CartoDBを使えば,誰でもデータを視覚化できる側面と,PostGISの機能を駆使した高度なデータ解析と視覚化もできることがわかっていただければ嬉しいです。
SQL によるテーブル結合
行政区域データを選択し,サイドバーの [SQL] ボタンを開くと,
SELECT * FROM n03_15_11_150101
と入力されています。
- はすべての列を表すので,この SQL は「行政区域データからすべての列を選択しなさい」という意味になります。
この文章を編集しながら,目的のデータを抽出していきましょう。
まずは,前回と同じ結果を再現します。
SELECT * FROM n03_15_11_150101 FULL JOIN ikilog_suzume_saitama_utf8 ON n03_004 = county
これは,「n03_004 と county が一致するものは 行政区域データとスズメデータを結合し,すべての列を選択しなさい」という意味です1。
Apply query をクリックし,実行してみると…

エラーになりました(笑)
cartodb_id という列が両方にあって,特定できないのが原因です。
では,必要な列の名前を列記して,抽出することにします。
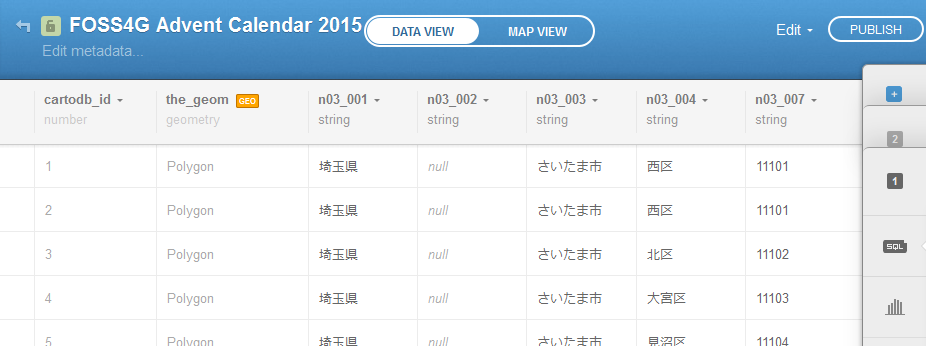
1列目の cartodb_id は CartoDB がつけたシリアルNo です。
2列目の the_geom には,Polygon の位置と形(ジオメトリ)が格納されています。
この列を指定することで,空間情報を選択することができます。
このとき,隠された the_geom_webmercator という列も一緒に指定してください2。
位置情報を持たないスズメデータは the_geom 列が null になっているので,選択する必要はありません。
両方に同じ名前がある場合は,テーブル名.列名 で指定が可能です。長いときはエイリアスを使いましょう。
SELECT
t1.the_geom, t1.the_geom_webmercator, n03_003, n03_004,
registrantID, year, month, day, eventRemarks, stateProvince,
county, individualCount
FROM n03_15_11_150101 t1 FULL JOIN ikilog_suzume_saitama_utf8 t2
ON n03_004 = county
今度は実行でき,前回のテーブル結合と同じ結果が得られました。
しかし,まだ 市+区 のデータが結合していないので,SQL の編集を続けます。
スズメデータの county と同じにするため,行政区域データの n03_003 と n03_004 を || で連結させます。
また,n03_003 が null だと,結合後も null になってしまうため,coalesce で,null のときは '' に置換します。
今回は市区町村での比較をしたいので,INNER JOIN を使い county が空白な県レベルのデータ等,一致しないデータは除外しましょう。
SELECT
t1.the_geom, t1.the_geom_webmercator, n03_003, n03_004,
registrantID, year, month, day, eventRemarks, stateProvince,
county, individualCount
FROM n03_15_11_150101 t1 INNER JOIN ikilog_suzume_saitama_utf8 t2
ON coalesce(n03_003, '') || n03_004 = county
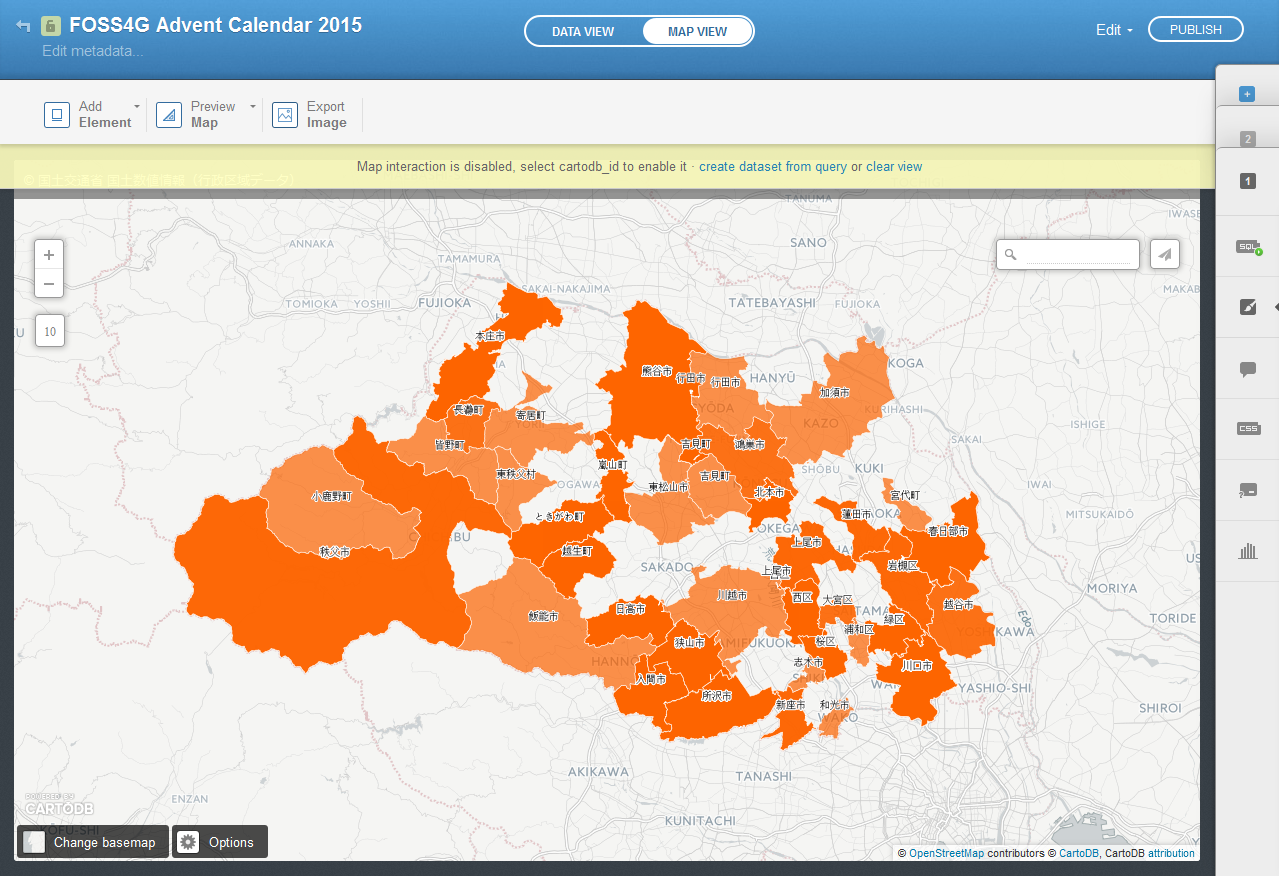
今度はうまくできました。
ところどころ,スズメ報告のない市区町村もありますが,全体的な傾向として人口の多そうな地域での報告数が多い結果となりました。
中央の create dataset from query という文字をクリックすると,この結果を新しいデータとして保存できます。
SQL による集計
先ほどは,市区町村ごとのスズメの報告数を比較しましたが,このスズメデータには個体数の情報(individualcount)も記録されています。
今度は,この個体数を合計して比較したいと思います。
SELECT
t1.the_geom, t1.the_geom_webmercator, county,
sum(individualCount) as sum_of_individualcount
FROM n03_15_11_150101 t1 INNER JOIN ikilog_suzume_saitama_utf8 t2
ON coalesce(n03_003, '') || n03_004 = county
GROUP BY t1.the_geom, t1.the_geom_webmercator, county
この値を,コロプレス や バブル に反映させて,可視化してみましょう。

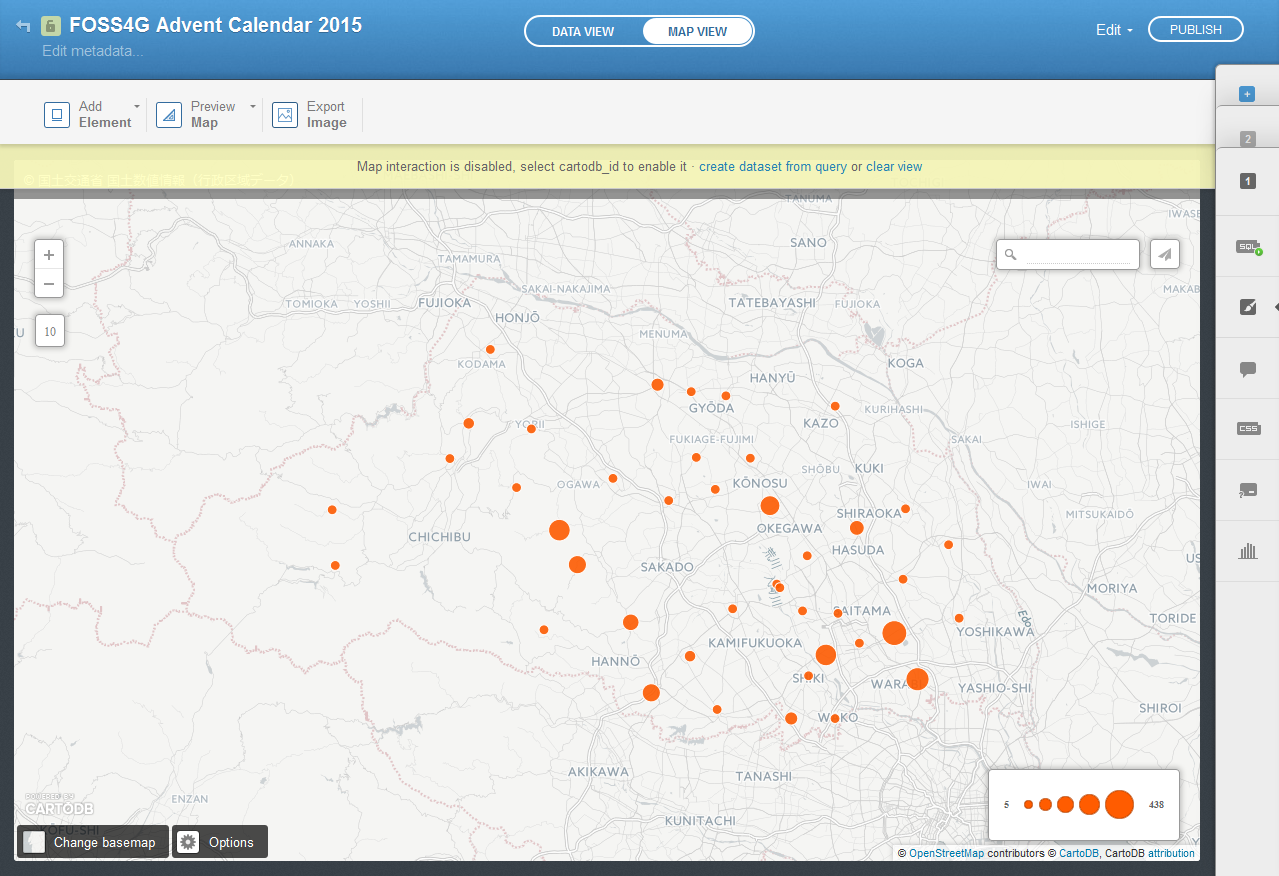
さいたま市緑区 と 川口市 における,スズメの報告個体数の合計が 438個体,405個体 と県の中で多い結果になりました。
この2地域の調査努力量が多い可能性も考えられますが,もしかすると本当にスズメが多いのかもしれません。
おわりに
今回ご紹介したように,データの整形や集計を SQL で記述しておくことで,今後データが更新されたときも再度実行するだけでよく,二度手間を防ぐことができます(=再利用可能)。
また,処理の途中の中間ファイルがあふれて,整理が大変になることもありません。
CartoDB によって,GIS に詳しくない人も含めた多くの人が本来悩むべきでないこと3から抜け出し,それぞれの課題の本質だけに集中できるようになる日は近いです♪
参考
地図DB:CartoDBに関するもっと詳細な情報を掲載しています。