皆さんこんにちは。お久しぶりのエンジニアブログ執筆となります、C&I統括本部テクノロジーイノベーションの近藤です。
今回は、Unityに画像分類モデルを組み込んで、Webカメラに写したものを判定するアプリを作成してみました。
- 作成するアプリケーションの概要
- 開発環境
- 作業手順
3.1 モデルを作る
3.2 Unityへの組み込み前準備
3.3 Unity組み込み - 最終成果物
- 終わりに
5.1 課題
5.2 今後の展望
1. 作成するアプリケーションの概要
- Webカメラに映った特定のものを判別するアプリ
複数の小鳥のクリップを識別して、どのクリップが映っているかを表示するアプリ
2. 開発環境
- Unity2021.3.18f1
UnityBarracuda 3.0.1 - Anaconda 23.7.2
Python 3.11.5
3. 作業手順
3-1.モデルを作る
Googleが提供しているTeachable Machineというサービスを使って、画像分類モデルを作成します。
https://teachablemachine.withgoogle.com/

こちらのサービスを使うと、
i. Webカメラを使って分類したい画像を撮影する
ii. 撮影したデータを使ってモデルをトレーニングする
iii. エクスポートする
というたったの3手順で機械学習モデルを作成することができます。とっても便利ですね!
今回は画像分類プロジェクトを使いますが、他にも音声やポーズを学習させることができます。
今回は、かわいい小鳥のクリップ画像を分類するモデルを作成します。
3-1-1. モデルタイプの選択

トップページの作ってみるボタンを押すと、モデルの種類を選ぶ画面に遷移します。
今回は画像プロジェクトを選びましょう。

画像プロジェクトを選ぶと、標準モデルか埋め込みモデルを作るか聞かれます。
今回は標準画像モデルを選択します。
3-1-2. 画像の登録
次に、分類したい画像を用意します。
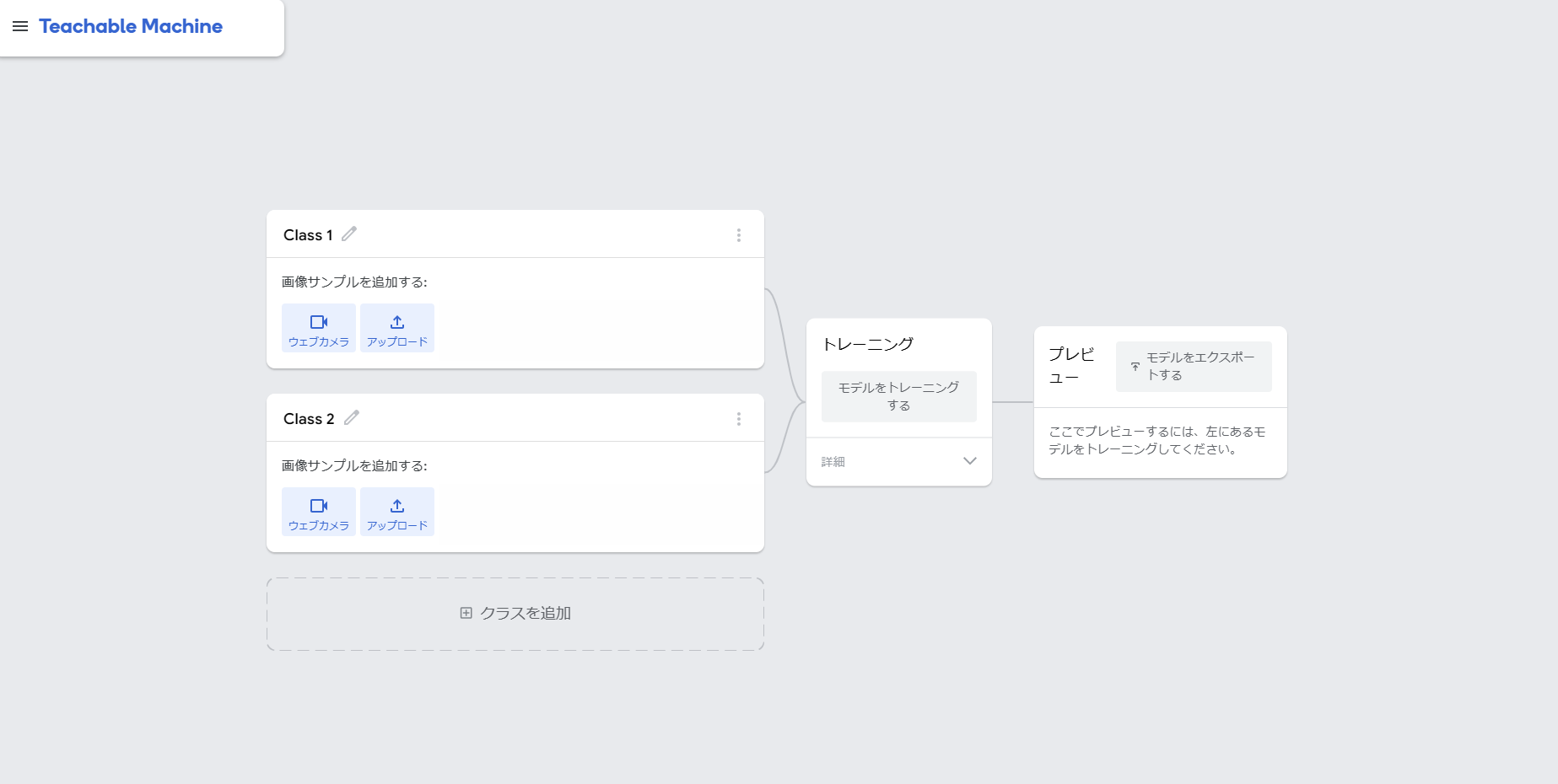
Class1 Class2と書いてある所には、識別したい物体のラベルを入れます。
それぞれのノードごとに、「画像サンプルを追加する」という項目があります。
画像はウェブカメラから撮影もできますが、アップロードも可能です。
今回はお手軽に、ウェブカメラから撮影して用意してみましょう。
ウェブカメラを選択すると、現在PCにつながっているカメラのプレビュー画面が表示されます。長押しして録画を押下すると、録画している間、ウェブカメラから画像を撮影してくれます。

ある程度の枚数が撮影出来たら、Class1を任意の名前に変更し、次の分類画像を用意します。
今回はもう一つの分類画像を用意します。

用意した結果がこちらです。クラスを追加を押すと、さらに分類画像を追加できます。一旦今回は2つでやってみましょう。
3-1-3. トレーニング&プレビュー
画像が用意出来たら、次は中央の「モデルをトレーニングする」を押しましょう。トレーニングしている間は、タブを切り替えず、開いたままにする必要があります。
トレーニング出来たら、右端のプレビューが表示されます。
ウェブカメラに、先ほど学習させた物体を映してみると…

カメラに映った物体を識別していますね!
3-1-4.モデルのエクスポート
最後に、作ったモデルのエクスポートを行います。
今回はTensorFlowSavedModelでエクスポートします。

変換が完了すると、モデルがDLされます。
これで自作モデルを作ることができました。
DLしたファイル一式は分かりやすいところに移動しておきましょう。
3-2.Unityへの組み込み前準備
3-2-1.モデルの形式変換
今回Unityに学習モデルを組み込むにあたって、UnityBarracudaを利用します。UnityBarracudaとはUnity 用のニューラルネットワークの軽量な Unity Technologies 製の推論ライブラリです。
UnityBarracudaが対応しているモデル形式はONNXになるため、先ほど作った
TensorFlowSavedModelを、ONNX形式に変換しましょう。
変換ツールはいくつかあるのですが、今回はtf2onnxを使います。
Anacondaに変換用仮想環境を作り、tf2onnxをインストールします。
tf2onnxは、python3.7-3.10の環境をサポートしていますので、必ずその環境で使いましょう。
※インストール手順は割愛します。
インストール出来たら、コマンドを使ってモデルを変換してみましょう。
python -m tf2onnx.convert --saved-model [展開したsavedmodelファイルのうち、savedmodel.pbファイルがあるディレクトリまでのパス] --output [出力先パス(末尾.onnxのファイル名含む)] --opset 13
例:python -m tf2onnx.convert --saved-model hogehoge\model.savedmodel --output hogehoge\piyochan_model.onnx --opset 13

3-3.Unity組み込み
モデルも用意出来たので、いよいよUnityに組み込んでいきましょう。
3-3-1.UnityBarracudaをインストールする
UnityBarracudaをインストールします。
インストールの仕方は、UnityEditor>Window>PackageManagerを開き、左上の「+」ボタンを押下します。
するといくつかメニューが出現するので、「Add package from git URL」で、UnityBarracudaのリポジトリURLを入力して「Add」を押しましょう。

インストールが完了すると、Package一覧にUnityBarracudaが追加されます。
3-3-2.モデルをインポートする
Projectウィンドウから、Asset>Resourcesのフォルダを作ります。
その中に、先ほど変換したonnxファイルと、savedmodelファイルに入っていたlabel.txtというファイルをドラッグアンドドロップで追加します。
3-3-3.結果表示用UIを作る
次に、ウェブカメラの画像を画面に表示し、結果を表示できるようなUIを作ります。
Hierarchyを右クリックして、UI>RawImageと、UI>Text(Legacy)を追加します。Textには「ここに結果を表示するよ」と仮の文章を入れます。


3-3-4.推論&表示用のスクリプトを用意する
スクリプトを用意します。一つはWebCam.cs
もう一つはClassifier.csです。
WebCam.cs
using System.Collections;
using System.Collections.Generic;
using UnityEngine;
using UnityEngine.UI;
// Webカメラ
public class WebCam : MonoBehaviour
{
// カメラ
RawImage rawImage; // RawImage
WebCamTexture webCamTexture; //Webカメラテクスチャ
// 推論
public Classifier classifier; // 分類
public Text uiText; // テキスト
private bool isWorking = false; // 処理中
WebCamDevice[] devices;//PCにつないでいるウェブカメラデバイスのリスト
private string webCamName ;
// スタート時に呼ばれる
void Start ()
{
//Webカメラの取得
devices = WebCamTexture.devices;
//PC付属のカメラが[0]のカメラのため、USB接続の外付けカメラを指定するために[1]のカメラ名を取得
webCamName = devices[1].name;
// Webカメラの開始
this.rawImage = GetComponent<RawImage>();
this.webCamTexture = new WebCamTexture(
webCamName,
Classifier.IMAGE_SIZE, Classifier.IMAGE_SIZE, 30);
this.rawImage.texture = this.webCamTexture;
this.webCamTexture.Play();
}
// フレーム毎に呼ばれる
private void Update()
{
// 画像分類
TFClassify();
}
// 画像分類
private void TFClassify()
{
if (this.isWorking)
{
return;
}
this.isWorking = true;
// 画像の前処理
StartCoroutine(ProcessImage(result =>
{
// 推論の実行
StartCoroutine(this.classifier.Predict(result, probabilities =>
{
// 推論結果の表示
this.uiText.text = "";
for (int i = 0; i < 2; i++)
{
this.uiText.text += probabilities[i].Key + ": " +
string.Format("{0:0.000}%", probabilities[i].Value) + "\n";
}
// 未使用のアセットをアンロード
Resources.UnloadUnusedAssets();
this.isWorking = false;
}));
}));
}
// 画像の前処理
private IEnumerator ProcessImage(System.Action<Color32[]> callback)
{
// 画像のクロップ(WebCamTexture → Texture2D)
yield return StartCoroutine(CropSquare(webCamTexture, texture =>
{
// 画像のスケール(Texture2D → Texture2D)
var scaled = Scaled(texture,
Classifier.IMAGE_SIZE,
Classifier.IMAGE_SIZE);
// コールバックを返す
callback(scaled.GetPixels32());
}));
}
// 画像のクロップ(WebCamTexture → Texture2D)
public static IEnumerator CropSquare(WebCamTexture texture, System.Action<Texture2D> callback)
{
// Texture2Dの準備
var smallest = texture.width < texture.height ? texture.width : texture.height;
var rect = new Rect(0, 0, smallest, smallest);
Texture2D result = new Texture2D((int)rect.width, (int)rect.height);
// 画像のクロップ
if (rect.width != 0 && rect.height != 0)
{
result.SetPixels(texture.GetPixels(
Mathf.FloorToInt((texture.width - rect.width) / 2),
Mathf.FloorToInt((texture.height - rect.height) / 2),
Mathf.FloorToInt(rect.width),
Mathf.FloorToInt(rect.height)));
yield return null;
result.Apply();
}
yield return null;
callback(result);
}
// 画像のスケール(Texture2D → Texture2D)
public static Texture2D Scaled(Texture2D texture, int width, int height)
{
// リサイズ後のRenderTextureの生成
var rt = RenderTexture.GetTemporary(width, height);
Graphics.Blit(texture, rt);
// リサイズ後のTexture2Dの生成
var preRT = RenderTexture.active;
RenderTexture.active = rt;
var ret = new Texture2D(width, height);
ret.ReadPixels(new Rect(0, 0, width, height), 0, 0);
ret.Apply();
RenderTexture.active = preRT;
RenderTexture.ReleaseTemporary(rt);
return ret;
}
}
Classifier.cs
using System;
using Unity.Barracuda;
using System.Linq;
using UnityEngine;
using System.Collections;
using System.Collections.Generic;
using System.Text.RegularExpressions;
// 分類
public class Classifier : MonoBehaviour
{
// リソース
public NNModel modelFile; // モデル
public TextAsset labelsFile; // ラベル
// パラメータ
public const int IMAGE_SIZE = 224; // 画像サイズ
private const int IMAGE_MEAN = 127; // MEAN
private const float IMAGE_STD = 127.5f; // STD
// private const string INPUT_NAME = "input"; // 入力名
private const string INPUT_NAME = "sequential_3_input"; //★ 入力名
private const string OUTPUT_NAME = "sequential_5"; //★出力名
// 推論
private IWorker worker; // ワーカー
private string[] labels; // ラベル
private int waitIndex = 0;
// スタート時に呼ばれる
void Start()
{
// ラベルとモデルの読み込み
this.labels = Regex.Split(this.labelsFile.text, "\n|\r|\r\n")
.Where(s => !String.IsNullOrEmpty(s)).ToArray();
var model = ModelLoader.Load(this.modelFile);
Debug.Log(labels[0]);
Debug.Log(labels[1]);
// ワーカーの生成
this.worker = WorkerFactory.CreateWorker(WorkerFactory.Type.ComputePrecompiled, model);
}
// 推論の実行
public IEnumerator Predict(Color32[] picture, System.Action<List<KeyValuePair<string, float>>> callback)
{
// 結果
var map = new List<KeyValuePair<string, float>>();
// 入力テンソルの生成
using (var tensor = TransformInput(picture, IMAGE_SIZE, IMAGE_SIZE))
{
// 入力の生成
var inputs = new Dictionary<string, Tensor>();
inputs.Add(INPUT_NAME, tensor);
// 推論の実行
var enumerator = this.worker.ExecuteAsync(inputs);
// 推論の実行の完了待ち
while (enumerator.MoveNext())
{
waitIndex++;
if (waitIndex >= 20)
{
waitIndex = 0;
yield return null;
}
};
// 出力の生成
var output = worker.PeekOutput(OUTPUT_NAME);
for (int i = 0; i < labels.Length; i++)
{
map.Add(new KeyValuePair<string, float>(labels[i], output[i] * 100));
}
}
// ソートして結果を返す
callback(map.OrderByDescending(x => x.Value).ToList());
}
// 入力テンソルの生成
public static Tensor TransformInput(Color32[] pic, int width, int height)
{
float[] floatValues = new float[width * height * 3];
for (int i = 0; i < pic.Length; ++i)
{
var color = pic[i];
floatValues[i * 3 + 0] = (color.r - IMAGE_MEAN) / IMAGE_STD;
floatValues[i * 3 + 1] = (color.g - IMAGE_MEAN) / IMAGE_STD;
floatValues[i * 3 + 2] = (color.b - IMAGE_MEAN) / IMAGE_STD;
}
return new Tensor(1, height, width, 3, floatValues);
}
}
★入力名と★出力名は、インポートしたモデルのInspecterから確認できます。
画像中央部のInputsとoutputsに記載されているので、その文字を指定しましょう。

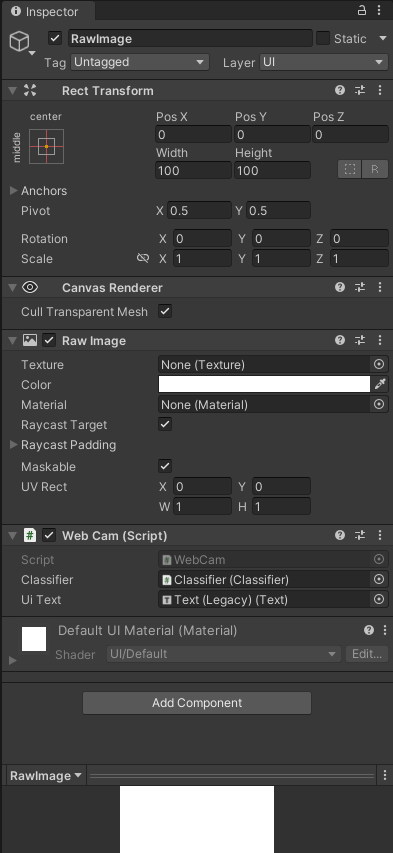
WebCam.csは先ほど作ったRawImageにアタッチします。
Classifier.csは、EmptyObjectを作って、そこにアタッチします。
アタッチした後、インスペクターから各項目をドラッグアンドドロップして、下記の通りに設定します。
Classifierオブジェクトには、ModelFileに先ほどインポートしたonnxファイルを、LabelsFileにはlabels.txtを設定します。

RawImageには、Classifierオブジェクトと、textオブジェクトを設定します。
4. 最終成果物
さて、準備は整いました。
それではPlayModeにしてみましょう。
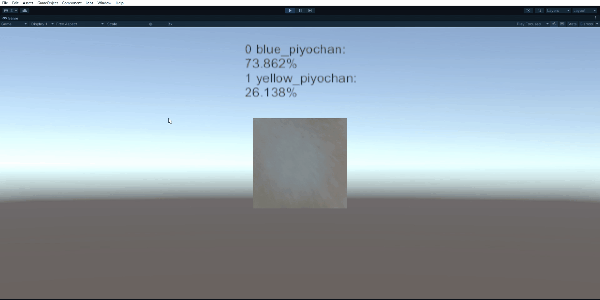
Unity上で青い鳥のクリップと、黄色い鳥のクリップを区別できていますね!
5. 終わりに
5-1. 課題
今回はゲーミングPCを使って動かしていたため、動きがカクカクしたり処理落ちを起こしたりといったことは起きませんでしたが、ここにエフェクトや他の処理を盛り込んだ時に、どれだけパフォーマンスを維持できるのかは気になるところです。
5-2. 今後の展望
Unity上で自分が作ったモデルが動かせれば、より多彩なインタラクティブコンテンツやゲームに活用できるのではないかと思います。
例えば、特定の物を探してカメラに映すとゲットできる、もの探しゲームも作れます。どんどんアイデアが膨らみますね!
私は業務外の余暇活動としてゲーム開発を行っているので、この技術をベースに新しいゲームを作りたいと思います。