概要
デザイナーが作ったモックアップ画像からコードを自動生成する、
Screenshot-to-code-in-Keras
というプログラムがニュースになっていたので、
どのくらいの精度があるのか試していきます。
今回はクラウド上で行うのでPCは何でもOKです。
一応以下ではOSはAmazon Linux、Python のバージョンは2.7で行っています。
準備1. Floydhub編
Floydhubというクラウドのサービスを利用していきます。
登録自体はメールアドレスだけで無料で簡単にできました。
(ただし無料プランだとGPU利用時間に制限があるようです)
登録後、ターミナルに以下のコマンドを打ちFloydhubにログインします。
pip install floyd-cli
floyd login
すると以下のように聞かれるので「y」と答えます。
Authentication token page will now open in your browser. Continue? [Y/n]: y
その次に「認証トークンを貼って」と言われるので、Floydhubの「CLI token」ページからトークンをコピペします(認証トークンはメールアドレスの確認を終えていないと出ません)。
Please copy and paste the authentication token.
This is an invisible field. Paste token and press ENTER:
これでFloydhubが使えるようになったので、
リポジトリをインストールしたい場所でgit cloneします。
git clone https://github.com/emilwallner/Screenshot-to-code-in-Keras
次にScreenshot-to-code-in-Keras/floydhubディレクトリに移動し、floyd initします。
cd Screenshot-to-code-in-Keras/floydhub
floyd init quick-start
これでFloydhub用の下準備は整いました。
準備2. 画像編
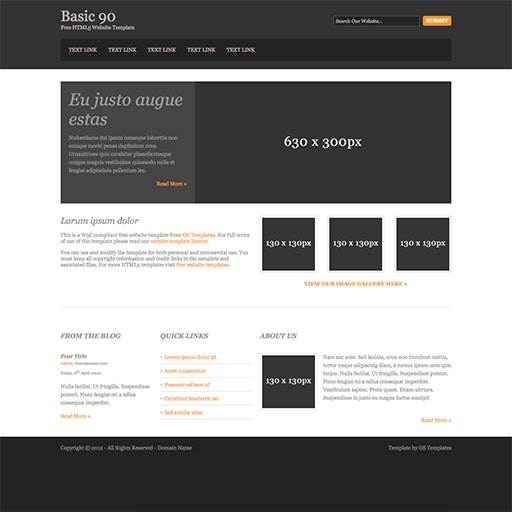
次にモックアップ画像の準備ですが、今回試すバージョンはある程度決まったフォーマットにしか対応していないようなので、
とりあえずデフォルトで入っている画像をそのまま使用します。
準備3. 実行ファイルの修正編
最後に、 実行するファイルであるScreenshot-to-code-in-Keras/floydhub/HTML/HTML.ipynbを2か所書き換えました。
一つ目は、190行目にある画像ファイル名。
今回使用する"90.jpg"に書き換えます。
190 "test_image = img_to_array(load_img('resources/images/90.jpg', target_size=(299, 299)))\n",
もう一つは、131行目にあるepochsの数字を増やして精度を高めます。
131 "model.fit([image_data, X], y, batch_size=64, shuffle=False, epochs=300)"
※注意 300エポックだと実行に1時間40分くらいかかりました。下手すると無料時間分を超えてしまう可能性があるので、適宜調整してください。
これで準備は完了です。
実行
floydhubディレクトリで以下のコマンドを実行するとインスタンスが立ち上がります。
(無料だと2時間しか使えないので終わったらシャットダウンすることをおすすめします)
floyd run --gpu --env tensorflow-1.4 --data emilwallner/datasets/imagetocode/2:data --mode jupyter
成功すると、ブラウザのFloydhubの「Jobs」ページにjobが追加されています。
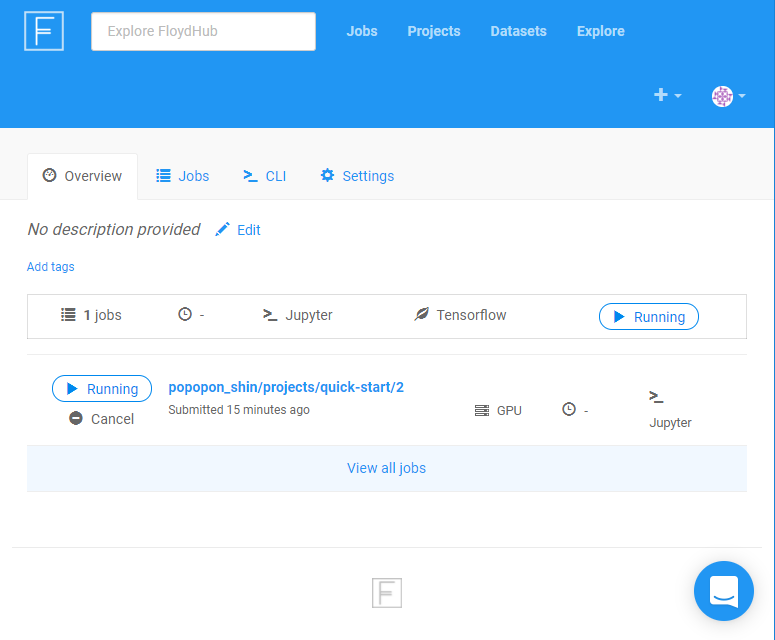
job内のoverviewタブの中からJupiter notebookにアクセスできるので、HTML.ipynbを探して開きます。
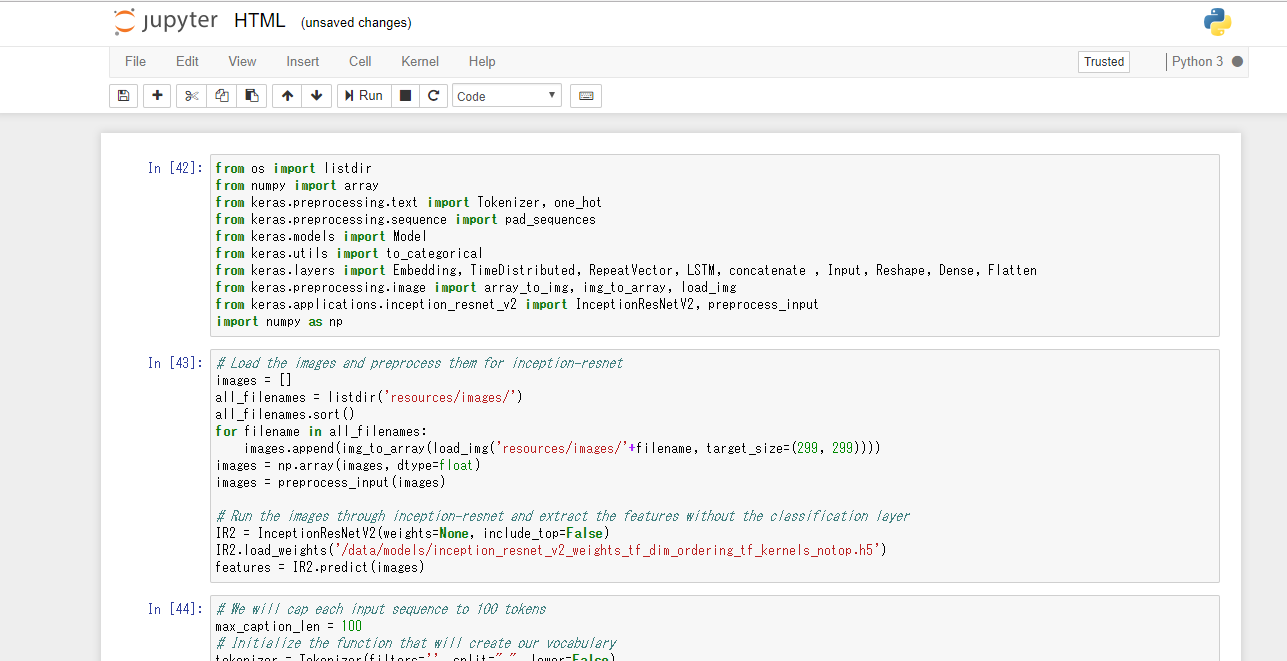
一番上のメニューの「cell」から「Run All」を選ぶと、スクリプトが実行されます。
300エポックはかなり時間がかかるので気長に待ちましょう。
結果
以下のようなサイトが生成されました(jsfiddle)。
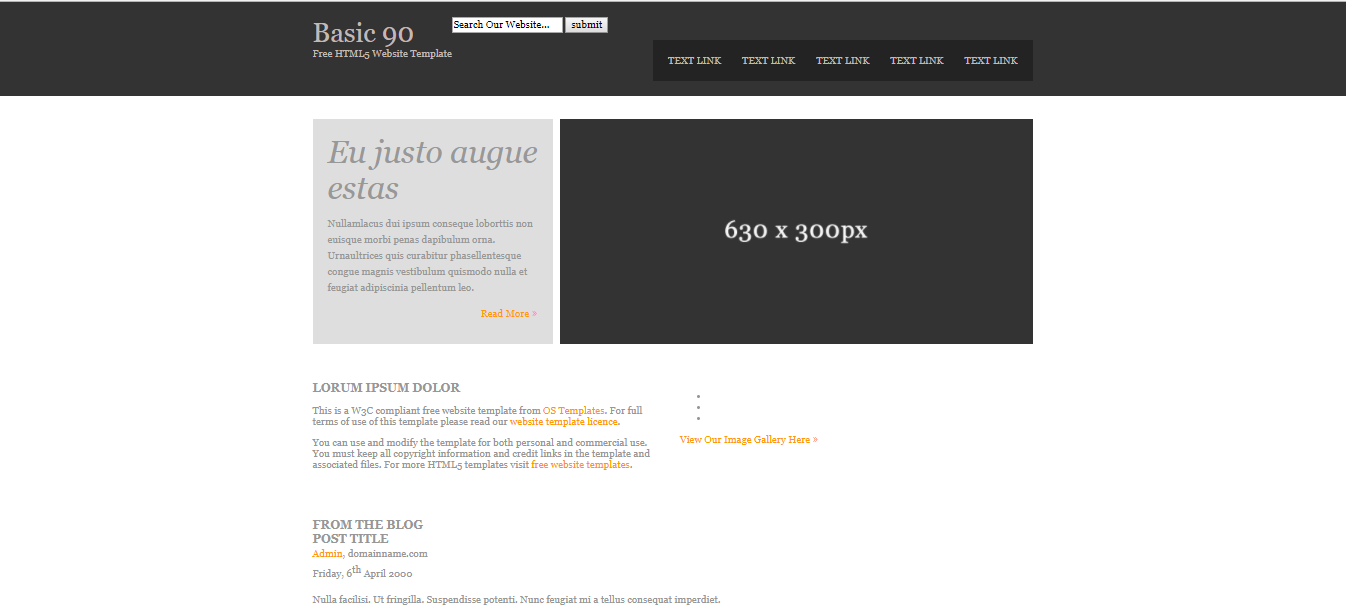
元の画像とは微妙に異なりますが、結構それっぽいものができました。
ソースを見てもあまり変なところはないようです。
エポック数をより増やせば、さらにモックのものに近づくと思われます。
今回はあらかじめ用意された画像を用いましたが、
好きな画像から生成できるバージョンもあるようなので、
気が向いたらまた試してみたいと思います。