どうもこんにちは。
今回は、前回に引き続き、SageMakerを使用してモデルのトレーニングを実行してみました。
BERTモデルってなに?
BERTは、NLP(自然言語処理)モデルの一種で、以下のような処理を行うことができます。
- 翻訳
- テキスト分類
- 質問応答
NLP(自然言語処理)
NLP(自然言語処理)は、話し言葉や書き言葉をコンピューターで分析、処理する技術です。
ChatCPTなどにも使用されている技術です。
NLP(自然言語処理)モデル
NLP(自然言語処理)モデルには以下のような種類があります。
- GPT-3
- CPT-4
- T5
- ELMo
Transformerについて
Transformerとは、2017年に発表された”Attention Is All You Need”という自然言語処理に関する論文の中で初めて登場した深層学習モデルです。それまで主流だったCNN、RNNを用いたエンコーダーデコーダーモデルとは違い、エンコーダーとデコーダーをAttentionというモデルのみで結んだネットワークアーキテクチャです。それによって、機械翻訳タスクにおいて速いのに精度が高いという特徴を持ち、非常に使い勝手のよいものとなっています。
BERTなどの強力なNLP(自然言語処理モデルの研究の多くは、このTransformerの上に構築されています。
今回のモデルトレーニングの想定ケース
今回は、ユーザの入力したコメントがどの感情に分類されるのかをトレーニングさせていこうと思います。
準備
S3
今回は、S3に作成したトレーニングデータを保存します。
そのため、「sagemaker~」から始まるバケットを作成して置いてください。
また、手順ごとにコードブロックを分けて記述してください。
実装手順
1. SageMakerのノートブックインスタンスの作成からノートブックを作成
ノートブックインスタンスのタイプはml.t3mediumを使用しました。
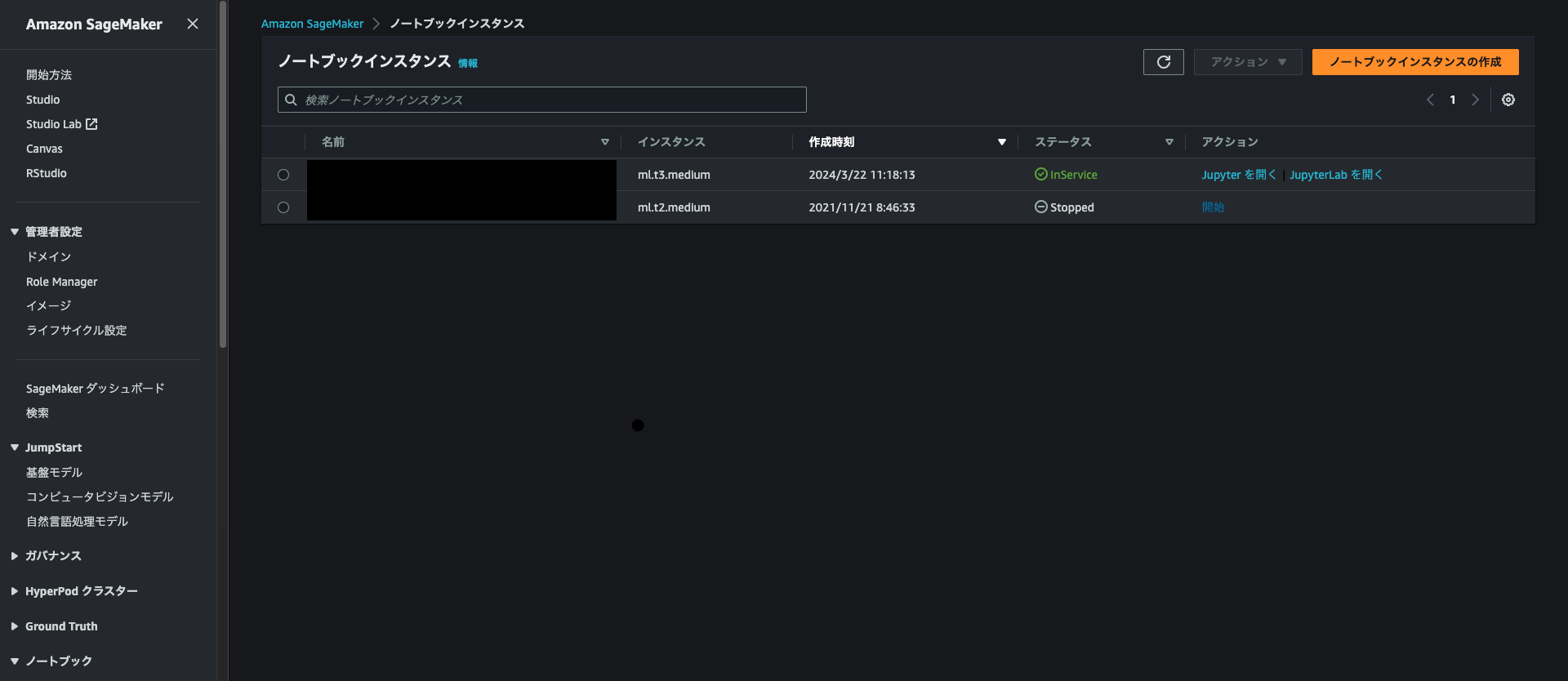
2. JupyterLabを開く
作成したノートブックインスタンスがinServiceになったらJupyterLab を開くリンクをクリックします。
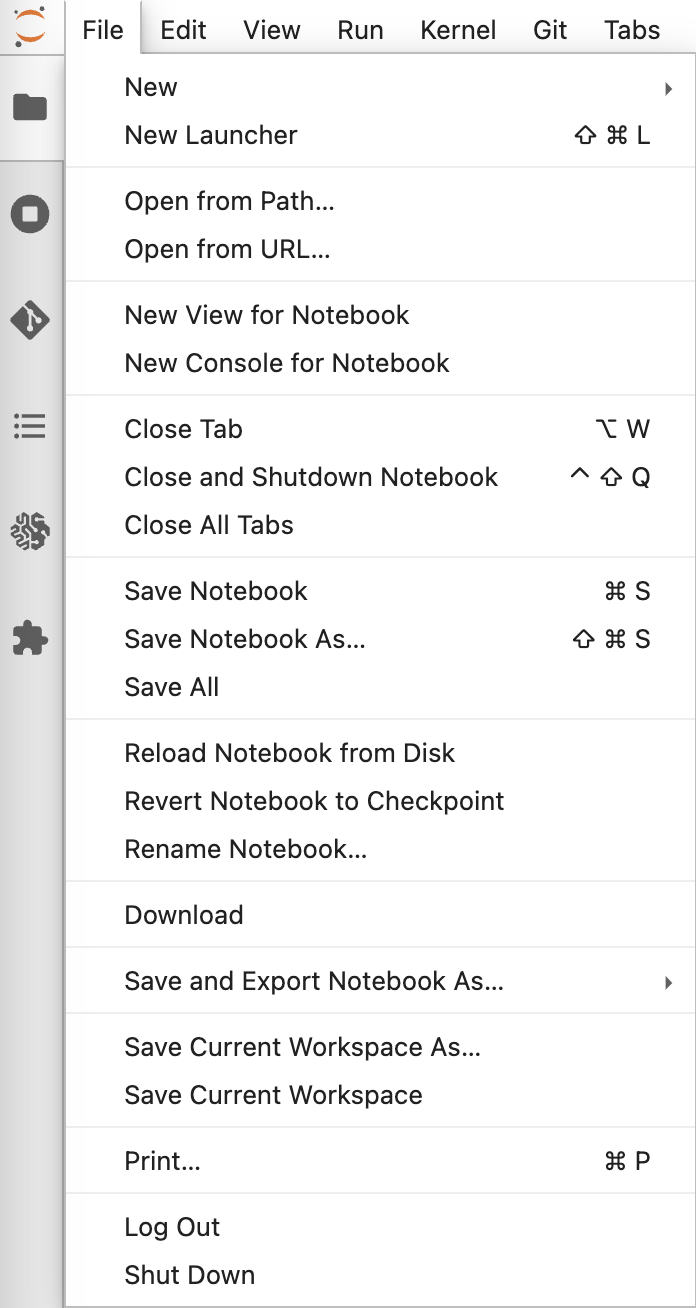
3. 新しいノートブックを開く
[File]>[New]>[Notebook]から新しくノートブックを立ち上げます。
この時、conda_python3を選択してください。
4. スクリプトを作成
トレーニングを行うためのスクリプトを保存します。
4-1. scriptsフォルダを作成
手動でも以下のコマンドでも問題ありません。
mkdir scripts
4.2. train.pyを作成
- scriptsフォルダにtrain.pyという名前のファイルを作成
- train.pyに以下のコードをコピペして保存
from transformers import AutoModelForSequenceClassification, Trainer, TrainingArguments, AutoTokenizer
from sklearn.metrics import accuracy_score, precision_recall_fscore_support
from datasets import load_from_disk
import random
import logging
import sys
import argparse
import os
import torch
if __name__ == "__main__":
parser = argparse.ArgumentParser()
# hyperparameters sent by the client are passed as command-line arguments to the script.
parser.add_argument("--model_name_or_path", type=str, default='bert-base-uncased')
parser.add_argument("--task_name", type=str, default='text-classification')
parser.add_argument("--do_train", type=bool, default=True)
parser.add_argument("--do_eval", type=bool, default=True)
parser.add_argument("--train_batch_size", type=int, default=20)
parser.add_argument("--eval_batch_size", type=int, default=20)
parser.add_argument("--num_train_epochs", type=int, default=4)
parser.add_argument("--learning_rate", type=float, default=5e-5)
parser.add_argument("--output_dir", type=str, default='/opt/ml/model')
# Data, model, and output directories
parser.add_argument("--output_data_dir", type=str, default=os.environ["SM_OUTPUT_DATA_DIR"])
parser.add_argument("--model_dir", type=str, default=os.environ["SM_MODEL_DIR"])
parser.add_argument("--n_gpus", type=int, default=os.environ.get("SM_NUM_GPUS", 0))
parser.add_argument("--training_dir", type=str, default=os.environ["SM_CHANNEL_TRAIN"])
parser.add_argument("--test_dir", type=str, default=os.environ["SM_CHANNEL_TEST"])
args, _ = parser.parse_known_args()
# Set up logging
logger = logging.getLogger(__name__)
logging.basicConfig(
level=logging.getLevelName("INFO"),
handlers=[logging.StreamHandler(sys.stdout)],
format="%(asctime)s - %(name)s - %(levelname)s - %(message)s",
)
# load datasets
train_dataset = load_from_disk(args.training_dir)
test_dataset = load_from_disk(args.test_dir)
logger.info(f" loaded train_dataset length is: {len(train_dataset)}")
logger.info(f" loaded test_dataset length is: {len(test_dataset)}")
# compute metrics function for binary classification
def compute_metrics(pred):
labels = pred.label_ids
preds = pred.predictions.argmax(-1)
precision, recall, f1, _ = precision_recall_fscore_support(labels, preds, average="weighted")
acc = accuracy_score(labels, preds)
return {"accuracy": acc, "f1": f1, "precision": precision, "recall": recall}
# download model from model hub
model = AutoModelForSequenceClassification.from_pretrained(args.model_name_or_path, num_labels=5)
tokenizer = AutoTokenizer.from_pretrained(args.model_name_or_path)
# define training args
training_args = TrainingArguments(
output_dir=args.output_dir,
num_train_epochs=args.num_train_epochs,
per_device_train_batch_size=args.train_batch_size,
per_device_eval_batch_size=args.eval_batch_size,
evaluation_strategy="epoch",
logging_dir=f"{args.output_dir}/logs",
learning_rate=float(args.learning_rate),
do_train=args.do_train,
do_eval=args.do_eval
)
# create Trainer instance
trainer = Trainer(
model=model,
args=training_args,
compute_metrics=compute_metrics,
train_dataset=train_dataset,
eval_dataset=test_dataset,
tokenizer=tokenizer,
)
# train model
trainer.train()
# evaluate model
eval_result = trainer.evaluate(eval_dataset=test_dataset)
# writes eval result to file which can be accessed later in s3 ouput
with open(os.path.join(args.output_data_dir, "eval_results.txt"), "w") as writer:
print(f"***** Eval results *****")
for key, value in sorted(eval_result.items()):
writer.write(f"{key} = {value}\n")
# Saves the model to s3
trainer.save_model(args.model_dir)
5. 必要なライブラリをインポート
以下をコピペしてください。
# 必要ライブラリインストール
import boto3
import pandas as pd
# テストデータ用ライブラリ
from sklearn.datasets import load_iris
import random, io, json
from datetime import datetime, timedelta
from io import StringIO
import os
# SageMaker用ライブラリ
import sagemaker
from sagemaker import model_uris, script_uris, hyperparameters
from sagemaker.serializers import CSVSerializer
from sagemaker.estimator import Estimator
from sagemaker.huggingface import HuggingFace
from datasets import load_dataset
from transformers import AutoTokenizer
6. データの前処理
# 感情ステータスを判定する関数
def determine_group(row):
comment = row['comment']
# negativeの判定
negative_phrases = [
'ごめんなさい', '申し訳ございません', '遺憾です'
]
if any(phrase in comment for phrase in negative_phrases):
return 1
# Neutralの判定
neutral_phrases = [
'確認いたします', '作業しています', '少々お待ちください'
]
if any(phrase in comment for phrase in neutral_phrases):
return 2
# Positiveの判定
positive_phrases = [
'とても嬉しいです', 'ありがとう', '助かりました'
]
if any(phrase in comment for phrase in positive_phrases):
return 2
# その他
return 0
7. サンプルデータ作成関数作成
def create_sample_data(num_rows):
data = []
for _ in range(num_rows):
row = {
"comment": random.choice(['本当にごめんなさい', '申し訳ございませんでした。', '誠に遺憾です', 'すぐに確認いたします', 'ただいま作業しています', 'お手数ですが、少々お待ちください。', '私はとても嬉しいです。', 'ありがとうございます。', '大変助かりました!', 'ほんとうにごめんなさい', '大変申し訳ございませんでした。', '誠に遺憾です。すみません。', 'すぐに確認します', 'ただいまから作業します', 'お手数ですが少々お待ちください。', '私はとてもハッピー。', 'ありがとう', '助かりました。'])
}
data.append(row)
return pd.DataFrame(data)
8. サンプルデータ生成
# 1000行のサンプルデータを生成
sample_data = create_sample_data(1000)
# 必要に応じてCSVファイルとして保存
sample_data.to_csv("sample_data.csv", index=False)
# severityカラムを追加してラベル付け
sample_data.insert(0, 'group', sample_data.apply(determine_group, axis=1))
9. S3へアップロードする
# フォルダがない場合に作成
os.makedirs('csv_datas', exist_ok=True)
# S3へアップロードするためにファイルをバイト列として読み込む
def upload_to_s3(file_path, bucket, object_name):
with open(file_path, 'rb') as f:
s3_client.put_object(Bucket=bucket, Key=object_name, Body=f.read())
# S3へアップロード
data_path = 'csv_datas/dataset.csv'
sample_data.to_csv(data_path, index=False)
upload_to_s3(data_path, bucket_name, 'csv_data/dataset.csv')
10. データの形式を変換する
csv_path = 'csv_datas/dataset.csv'
# CSVファイルからデータセットを読み込む
dataset = load_dataset('csv', data_files=csv_path)
dataset_dict = DatasetDict({
'train': train_head10_dataset.sample(800),
'test': test_head10_dataset.sample(200)
})
11. データのトークン化
HuggingFaceでデータを読み込んでもらうために、データセットをトークン化します。
自分はこれで3日間つまづきました。
model_name = "bert-base-uncased"
# トークナイザーの準備
tokenizer = AutoTokenizer.from_pretrained(model_name)
# トークン化関数
def tokenize_comment(batch):
return tokenizer(batch['comment'], padding='max_length', truncation=True)
# データセットのトークン化
dataset_dict = dataset_dict.map(tokenize_comment, batched=True)
# データセットから 'severity' カラムを 'labels' にリネームし、フォーマットを変換
dataset_dict = dataset_dict.rename_column("group", "labels")
dataset_dict.set_format('torch', columns=['input_ids', 'attention_mask', 'labels'])
# S3にトレーニングデータを保存
training_input_path = f's3://{bucket_name}/sample_train_data/train'
dataset_dict['train'].save_to_disk(training_input_path)
# S3にテストデータを保存
test_input_path = f's3://{bucket_name}/sample_train_data/test'
dataset_dict['test'].save_to_disk(test_input_path)
12. トレーニング実行
hyperparameters = {
'model_name_or_path': model_name,
'task_name': 'text-classification',
'do_train': True,
'do_eval': True,
'train_batch_size': 20,
'eval_batch_size': 20,
'num_train_epochs': 4,
'learning_rate': 5e-5,
'output_dir': '/opt/ml/model'
}
huggingface_estimator = HuggingFace(
entry_point='train.py',
source_dir='./scripts',
instance_type='ml.g4dn.xlarge',
instance_count=1,
role=role,
transformers_version='4.26',
pytorch_version='1.13',
py_version='py39',
hyperparameters=hyperparameters
)
huggingface_estimator.fit({'train': training_input_path, 'test': test_input_path})
13. モデルのデプロイ
モデルをデプロイします。
predictor = huggingface_estimator.deploy(1, "ml.g4dn.xlarge")
14. モデルの評価
デプロイしたモデルにコメントを投げてみます。
# 評価コード
input_comment= {"inputs":"非常に助かりました"}
predictor.predict(input_comment)
まとめ
最後に
以下を忘れずに実行してください。
# モデルとエンドポイントの削除
predictor.delete_model()
predictor.delete_endpoint()