初めまして、フィリピン在住のオンシオと申します。
英語がペラペラなことと、ピアノが弾けるとが私のアピールポイントです。
この度は、私の初作品である、G7の国旗の識別をするAIアプリを制作いたしました。
初めて制作した画像分類モデルの制作工程を、本記事にまとめます。
G7とは「Group of 7」の略称で、アメリカ、イギリス、フランス、ドイツ、イタリア、カナダ、日本の7カ国で構成された先進国首脳会議(政治フォーラム)のことです。
開 発 環 境:GoogleColaboratory
使 用 言 語:Python
使用モジュール:tensorflow 2.9.2(Googleの機械学習用オープンソースライブラリ)
♦制作工程
1.使用データの準備
2.画像の前処理
3.モデルの定義
4.モデルの学習
5.モデルの評価
6.モデルの保存
工程1. 使用データの準備
データ収集方法:i crawler(スクレイピングツール)
収集データ内容:アメリカ国旗、イギリス国旗、フランス国旗、ドイツ国旗、
イタリア国旗、カナダ国旗、日本国旗、各約100枚ずつ。
7カ国の国旗の画像は、下記の通り i crewler を使い収集いたしました。
!pip install icrawler
from icrawler.builtin import BingImageCrawler
# Bing用クローラーの生成
bing_crawler = BingImageCrawler(
downloader_threads=4,
storage={'root_dir': '/content/drive/MyDrive/NationalFlag/Canada'})
# クロールの実行
bing_crawler.crawl(
keyword="国旗 日本.",
max_num=100)
mux_numは100に設定しましたが、その中から学習に望ましくない画像を数枚ずつ削除いたしました為、実施に使用できた画像は各国旗とも95枚~100枚程度です。
2.画像の前処理
使用する7カ国の国旗の全ての画像を、縦50px × 横50pxにリサイズいたしました。
下記コードはJapanのものですが、同じfor分を各国旗で7回まわしました。
for i in range(len(path_Japan)):
img = cv2.imread('/content/drive/MyDrive/NationalFlag/Japan/' + path_Japan[i])
b,g,r = cv2.split(img)
img = cv2.merge([r,g,b])
img = cv2.resize(img, (50,50))
Japan.append(img)
# 以下省略。
各国旗のリストをNumpy配列にまとめます。
X = np.array(America + England + France + Germany + Italy + Canada + Japan)
y = np.array([0]*len(America) + [1]*len(England) + [2]*len(France)+ [3]*len(Germany) + [4]*len(Italy) + [5]*len(Canada) + [6]*len(Japan))
permutationとarrangeを使い、Xとyのデータをシャッフルします。
rand_index = np.random.permutation(np.arange(len(X)))
X = X[rand_index]
y = y[rand_index]
前処理した画像を、学習用8割、テスト用2割に分けます。
X_train = X[:int(len(X)*0.8)]
y_train = y[:int(len(y)*0.8)]
X_test = X[int(len(X)*0.8):]
y_test = y[int(len(y)*0.8):]
正解ラベルをone-hotの形に指定します。
y_train = to_categorical(y_train)
y_test = to_categorical(y_test)
3.モデルの定義
モデルに、VGG16(学習済モデル)を使い、転移学習をします。
VGG16は、畳み込み13層+全結合層3層=16層の、ニューラルネットワークの学習済みモデルです。
input_tensor = Input(shape=(50, 50, 3))
vgg16 = VGG16(include_top=False, weights='imagenet', input_tensor=input_tensor)
Sequentialをインスタンス化し、VGG16のoutputを受け取り、7クラス分類するモデルを定義する。
top_model = Sequential()
top_model.add(Flatten(input_shape=vgg16.output_shape[1:]))
top_model.add(Dense(256, activation='relu'))
top_model.add(Dropout(0.5))
top_model.add(Dense(7, activation='softmax'))
vgg16と、top_modelを連結します。
model = Model(vgg16.inputs, top_model(vgg16.output))
vggの層の重みを変更不能(固定)にします。
for layer in model.layers[:19]:
layer.trainable = False
誤差関数はcategorical crossentropy、最適化はSGDにし、モデルをコンパイルします。
model.compile(loss='categorical_crossentropy',
optimizer=optimizers.SGD(lr=1e-4, momentum=0.9),
metrics=['accuracy'])
4.モデルの学習
モデルの学習を行います。
※GoogleColaboratoryを使う場合は、ランタイムのタイプをGPUにし高速で行うと良い。
history = model.fit(X_train, y_train, batch_size=100, epochs=10, validation_data=(X_test, y_test))
5.モデルの評価
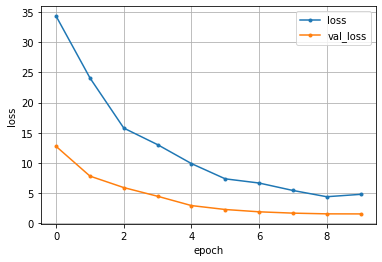
モデルを評価し、可視化します。
loss=history.history['loss']
val_loss=history.history['val_loss']
epochs=len(loss)
plt.plot(range(epochs), loss, marker = '.', label = 'loss')
plt.plot(range(epochs), val_loss, marker = '.', label = 'val_loss')
plt.legend(loc = 'best')
plt.grid()
plt.xlabel('epoch')
plt.ylabel('loss')
plt.show()
val_lossが右肩下がりになっており、エポックを重ねるごとに正解値と予測値とのズレの大きさ(損失)が減っていることが確認できます。
6.モデルの保存
学習したモデル(重み)を保存します。
model.save('/content/drive/MyDrive/model.h5')
Webアプリに実装
GithubとRenderを使用して、作った学習モデルをWebアプリに実装します。
動作確認
こちらのカナダ国旗の画像を使って、動作確認をしてみました。

「これは Canada です」と返って来ました。日本国旗とカナダ国旗は紛らわしいのではないかと心配しておりましたが、無事に正解することができました。

感想
アプリを制作するだけでなく、制作工程をQiitaにまとめることにより、改めて引数の中身を確認したり、コードの理解を深めることができました。
また、今回はデータセットを使わずに、国旗画像を自分で取集することにより、クロールを行ったり、その中から使えない画像を判断し手作業で削除する作業を経験することもでき、とても満足しております。
画像の識別だけでなく、Cドゥア、Dモール、Eドゥアなど、あらゆる音階や色々な度数の和音の識別をできるアプリを制作することが、私の最終目標です。
お婆ちゃんになる前に実現できるよう、今後も機械学習のお勉強を頑張りたいと思います。