ChatGPTどうやって使う...?
この記事は
- ChatGPTが利用できるようになったけど、次何すればいいですか?
- アイデアはあるけどプロンプトエンジニアリング, LangChain, RAGとか全然よく知らない
- 手っ取り早く、業務自動化を体験したい!
といった方々に向けて、具体的なハンズオン形式でChatGPTによる業務改善体験する例をご紹介することで、ご自身で検証していく際の助力となることを目指しています!
開発を試す手順
個人の主観にはなりますが、ChatGPTが使えるようになったら試すべき手順は以下をお勧めします:
| 試すべきこと | 開発負荷(体感) | 備考 |
|---|---|---|
| 1. Webの対話アプリをお試しする | 0.5時間 | |
| 2. プロンプトを改善する | 2時間 | 世に言うプロンプトエンジニアリング |
| 3. 応用手法の検討 | 48時間 | より先進的なChatGPTの応用としてRAG,ReAct, function calling等手法を検討 |
| 4. (アプリに組み込む) | 96時間 | LangChain(python,typescriptで使用可能)フレームワーク推奨 |
まず、やりたいことを言語化してみて簡単な手法からできないか検討しましょう。
いきなり「RAGをpython flaskサーバで実装して検証して〜」と開発コストの高い手法を試す必要はないです。何だったらRAG、ReActといった最新手法も、中身はChatGPTのプロンプトをいじったり、複数・繰り返し使うだけのものが多いです。
対話アプリやプロンプトの改善だけでどれくらいやりたいことが自動化できるのかまずは検証を始めてみましょう。
0. 事前準備
今回はお題として
- 「メールの自動応答をChatGPTにやらせたい」
というテーマでChatGPTによる業務効率化の検証をしてみたいと思います。
また、この記事では以下の情報をご自身の環境と読み替えてください。
APIキー(サブスクリプションキー): hogehoge
エンドポイント: https://fugafuga.com
1. Web対話アプリをお試し
まずは試しましょう!
注意
会社の場合は機微情報を入力しないこと&オプトアウトの設定(自身の入力データをAIの学習に利用されない設定)が適切なことを確認しましょう。
最終的には
- 日程調整
- 業務内容を理解した文面の生成
- 返信の要否判断
等さまざまな機能を入れたいと思いますが、ぐっとこらえて最初の一歩として 「忘年会の調整メールの返信メッセージが生成できるか?」 を対話アプリ上でケース検証してみます。(ご自身で試される場合は自身の業務を想定した文面例を使うとよいでしょう。)
(1)
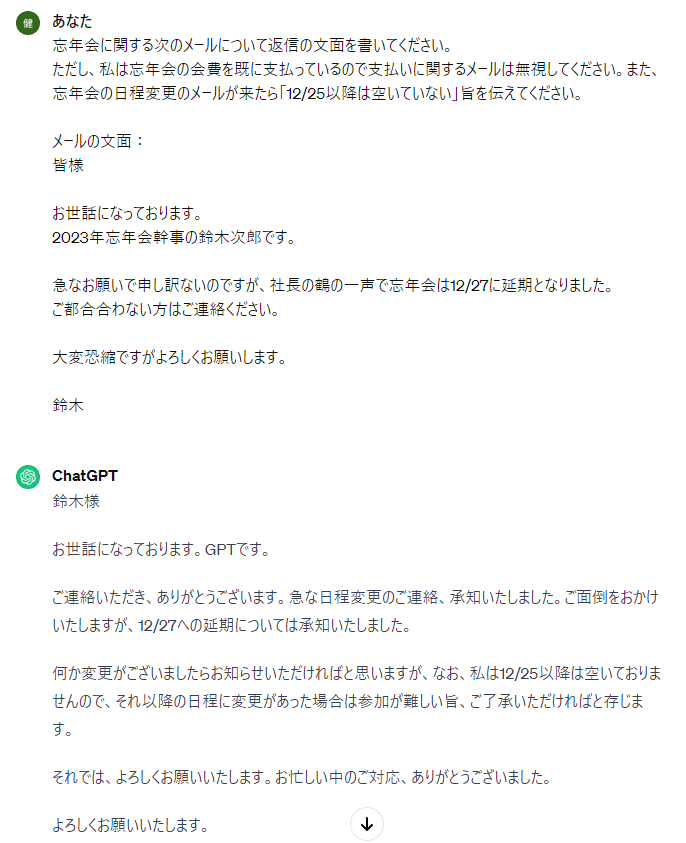
↑やや日本語に不自然さは残るものの、参加できない旨を伝えられています!
(2)
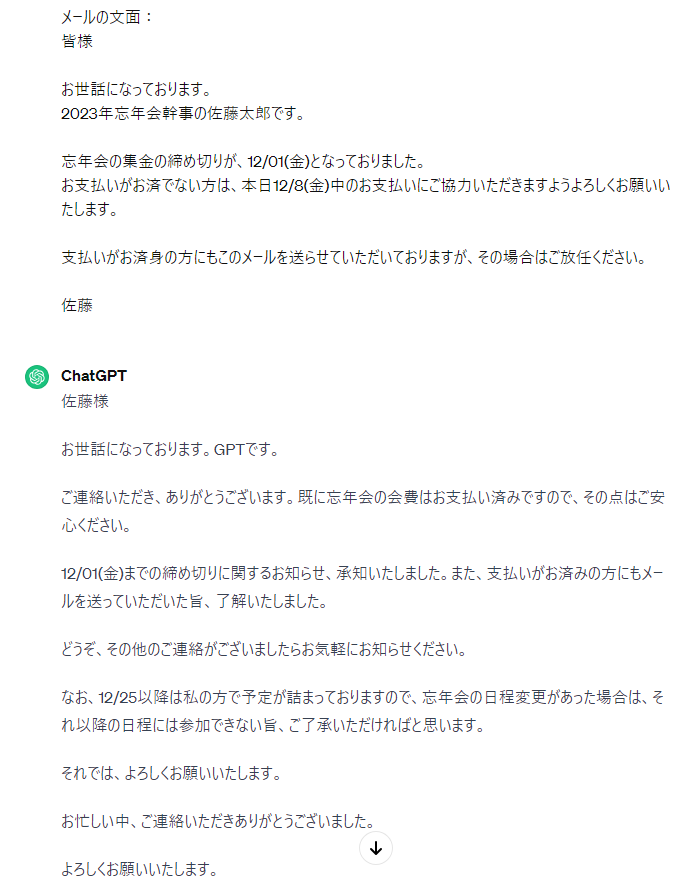
「支払いに関するメールは無視して」と指示したものの、プロンプト冒頭の命令を引きずって、回答メールを生成してしまっています。日本語も少し不自然ですね。
(3)
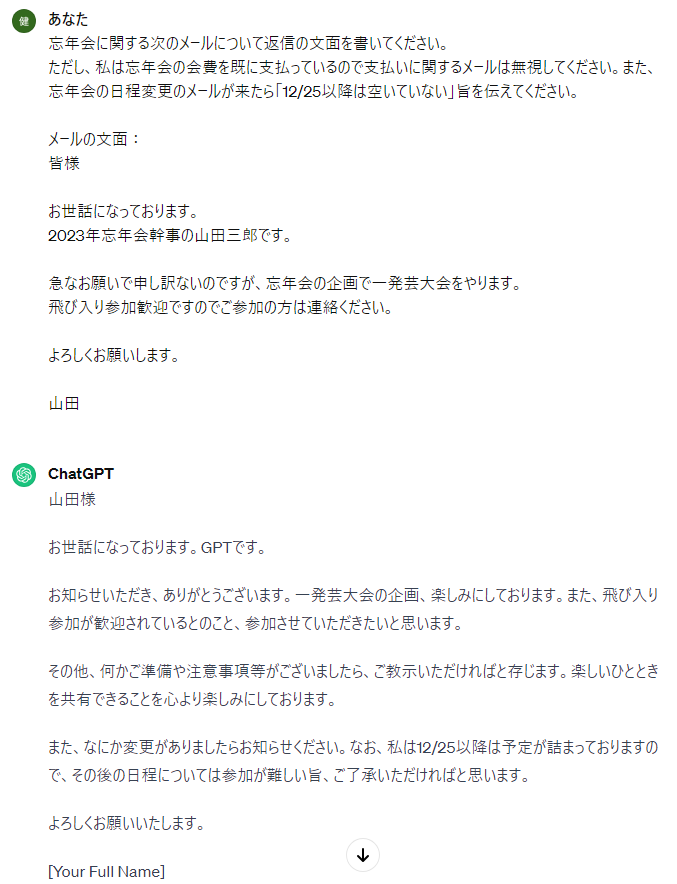
対処方法を指示していない「一発芸大会飛び入り参加のお誘い」に対してChatGPTが勝手に参加を表明しててわろたw。ChatGPTが対処する質問の範囲を制限して、予期していないメールには反応しないよう工夫をする必要がありそうです。
以上、少し試してみたところ「文面は基本よさそう」「けれど答えなくていいメールにもたまに返信してる」「そういえば、どの範囲までメールで自動返信させるべきだっけ?」といった長所・短所・課題等見えてくるかと思います。
2. プロンプトを改善
簡単に課題や改善点が見えてきたら、次に試すのが プロンプトの改良(=プロンプトエンジニアリング) です。
こちらの教科書にもある通り、ChatGPTは指示の与え方次第で我々の理想的な振る舞いに近づけることができます。
2-1. プロンプトの改善方針
1.では「文面を書いてください、ただし私は~で、また、~をしてください。」といった指示の出し方をしてみました。ですがChatGPTへの命令には、精度が上がるいくつかの経験則があります:
- 壱:「指示は冒頭に!次に文脈!フォーマットも忘れるな!」
- 弐:「やりたいことは、ChatGPTが強い小タスクに落とし込むべし!」
-
参:「指示は細かく、具体的であるほど良き!」
それぞれ簡単に見ていきましょう。
壱:「指示は冒頭に!次に文脈!フォーマットも忘れるな!」
# Bad プロンプト
"""Teplizumabは、Ortho Pharmaceuticalと呼ばれるニュージャージー州の薬剤会社に由来します。
そこでは、科学者たちはOKT3という抗体の初期バージョンを生成しました。
分子はもともとマウスから採取され、T細胞の表面に結合し、その細胞殺傷能力を制限することができました。
1986年に、腎臓移植後の臓器拒絶を防止するために承認され、これにより、人間の使用に許可された最初の治療用抗体となりました。
上の文章についてOKT3はどこから採取されたもの?
"""
# Good プロンプト
"""以下の文脈に基づいて質問に答えてください。回答が不明な場合は、「回答不明」と回答してください。
文脈:Teplizumabは、Ortho Pharmaceuticalと呼ばれるニュージャージー州の薬剤会社に由来します。そこでは、科学者たちはOKT3という抗体の初期バージョンを生成しました。分子はもともとマウスから採取され、T細胞の表面に結合し、その細胞殺傷能力を制限することができました。1986年に、腎臓移植後の臓器拒絶を防止するために承認され、これにより、人間の使用に許可された最初の治療用抗体となりました。
質問:OKT3はもともとどこから採取されたものですか?
回答:"""
必ずこうである必要もないのですが、冒頭に命令を端的に書いた方がよいという話1 があったり、自身で見やすくする上でも、再現性を高める上でも、フォーマットの統一をするのがおすすめです。
弐:「やりたいことは、ChatGPTが強い小タスクに落とし込むべし!」
ChatGPTは元々"自然言語処理"の研究分野で生まれたモデル由来の製品です。このモデルは学習の段階で 文章の「要約」「質問応答」「情報抽出」「分類」「対話」「コード生成」 などのタスクを"より人間らしく精度よく解けるよう"に訓練されています(例)。従って、我々がChatGPTに何か業務課題を解決させる際もこれらのタスクに当てはまるよう課題を設計するべきです。
参:「指示は細かく、具体的であるほど良き!」
ChatGPTへの命令は細かく、多数要求してよいです。
# Bad プロンプト
"""メールの内容を教えてください。良い知らせかどうかも教えてください。"""
# Good プロンプト
"""
メールの内容を2,3文に要約して、日本語で説明してください。
また、メールを「良い知らせ」と「悪い知らせ」の二つに分類してください。
さらに、そう判断した理由について簡潔に教えてください。
"""
案外、自分で最初プロンプトを書いていると 「説明が足りなかった」「指示にそもそも曖昧な部分がある」 など気づくことがあります。指示は社会人1年目の新人さんにもわかるくらい明確に書きましょう。
2-2. 実際にプロンプト改善して精度を上げてみる
以上のルールに従ってタスクやプロンプトを整理してみましょう。先ほどの検証例では「良い回答も出せるけど、意図しない回答をしたり、関係ない質問にも答えてしまった」という反省がありました。そこで今回は以下を意識してみます:
- タスクの具体化&変更
- タスク:忘年会のメールが(支払い/予定/それ以外)の3つに自動で分類できるか?
- 指示の詳細化
- 冒頭に指示、条件、役割を複数提示。フォーマットも意識する。

以下、先ほどと同じメールを送った時のChatGPT回答です。
(1)
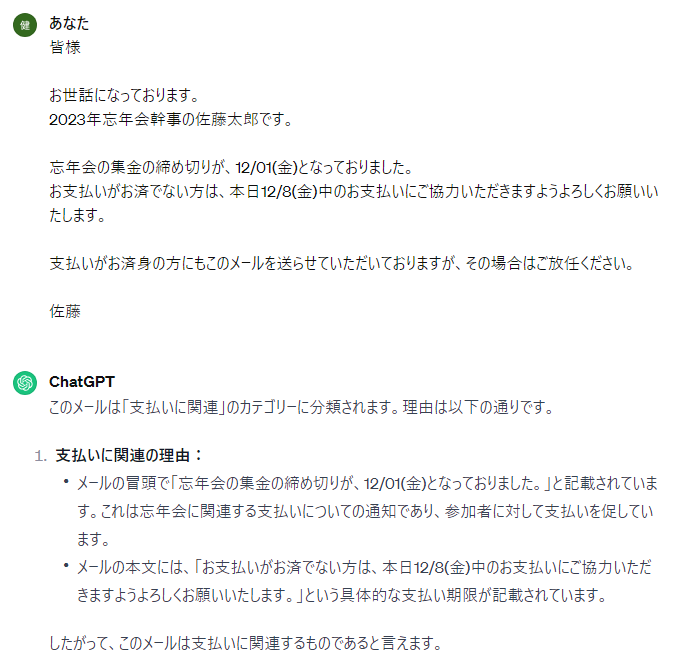
(2)
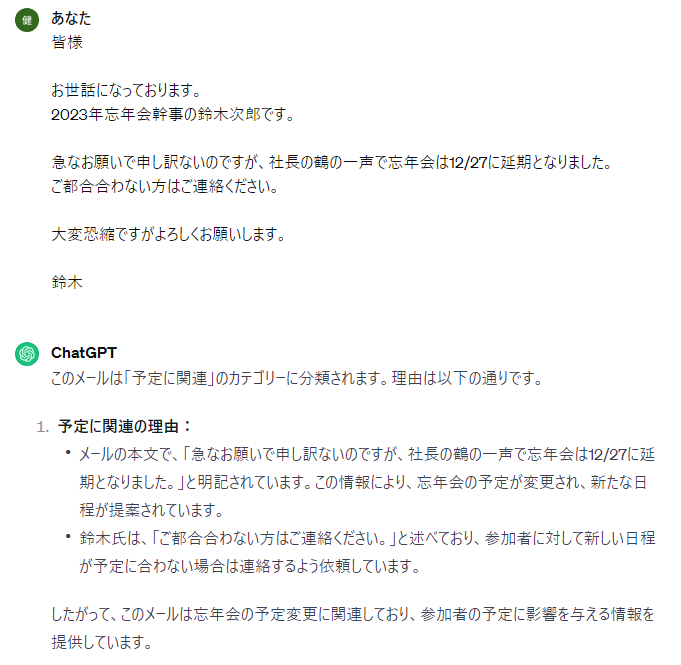
(3)
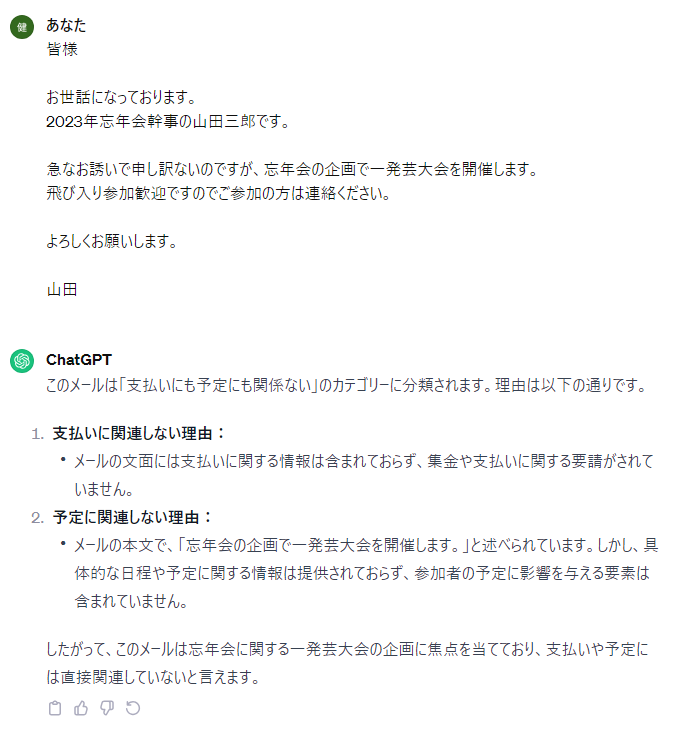
先ほどの曖昧なタスクとは打って変わり、メール分類に関しては非常に精度よく、全問正解していることが分かります。この結果を利用すれば「1.メールを分類する→2.各分類ごとに処理を分岐」という流れでアプリを組み立てることでより業務の精度を上げることができそうです!
3. 応用手法やツールを組み合わせて精度向上
ここまでプロンプトを変えるだけでも必要な情報を汲み上げて「人間が文章を読む作業」がいくらか自動化できたことが分かったかと思います。が、当然「こんな不安定じゃビジネスには使えん!」「全然高度な処理できない!」と思われる方もいらっしゃるでしょう。この粒度まで課題整理できたら、最新の応用手法を次に検討しましょう。
3-0. 環境構築
最新の手法を使ってアプリ開発や検証を行う上ではpython(, typescript)の環境整備がもはや必須といえるでしょう。というのも、「ChatGPTやその他大規模言語モデル(LLM)の出力結果を再度使用して、より複雑な処理を行う」「チャットの履歴を保持する」「DBやクラウドサービスと連携する」といったテキスト処理アプリ開発に必須な共通の作業を実行してくれる Langchain というライブラリが大変便利だからです。
ただし、このLangchainは現状 python, javascript(typescript)しかサポート していないため、ChatGPTアプリ開発に臨むうえではまず開発環境の構築を乗り越える必要があります。
$ # langchainはライブラリの更新が異常に早いので注意
$ pip install langchain==0.0.349
以降はpythonにてlangchainをインストールしたものと仮定して話を進めます。
3-1. ChatGPTの判断でプログラム実行(function calling)
ChatGPTの判断結果から何か処理をしてほしい場合を考えます。例えば先ほどの忘年会の例なら「支払いに関するメールだと判断できたら通知を飛ばしたい」とか「予定に関するメールだと判断できたら、私の空き時間に関する情報を返信に加えたい」等です。このようにChatGPTの文章理解の結果をトリガーに関数を呼び出す機能が function calling と呼ばれています。
以下のコードで試してみます:
from langchain.agents import initialize_agent, Tool
from langchain.agents.mrkl import prompt
from langchain.chat_models import AzureChatOpenAI
from langchain.prompts.chat import (
ChatPromptTemplate,
HumanMessagePromptTemplate,
SystemMessagePromptTemplate,
)
from langchain.schema import HumanMessage, SystemMessage
def send_email_to_someone():
# ここにメールを送る処理
print("You sent email!")
def send_email_by_ChatGPT_judge(email_content: str):
# OpenAIとの通信オブジェクト。今回はAzure OpenAIに接続する場合の例を示す。
model = AzureChatOpenAI(
openai_api_base="https://fugafuga.com",
openai_api_version="2023-03-15-preview",
openai_api_key="hogehoge",
openai_api_type="azure",
deployment_name="gpt-4-turbo",
)
# ChatGPTの判断で実行できる処理を登録する。ここではsend_email_to_meを実行できることになる。
tools = [Tool(name = "Email", func=send_email_to_someone, description="実行すると私にメールが届く")]
# 上記modelをベースに、toolを使って返答するAI、通称agentを作成する
agent = initialize_agent(
tools,
model,
# 以下は日本語で返答するのに必要
agent_kwargs=dict(suffix='Answer should be in Japanese.' + prompt.SUFFIX),
# 以下はdebug時に便利なオプション
verbose=True,
return_intermediate_steps=True
)
response = agent({"input": email_content})
return response
この関数を実行してみると以下のようになります:
> email_content = """あなたは私の代わりにメールを分析するAIです。
ただし、以下の情報をもとに回答をする必要があります。
- 支払い:私は忘年会の支払いを11/30に既に済ませています。忘年会の支払いに関してもう返事はしません。確認の必要もありません。
- 予定:私は12/25以降予定が詰まっているため、これ以降に忘年会が開催される場合参加できません。
- あなたは与えられたメールを「支払いに関連」「予定に関連」「支払いにも予定にも関係ない」の3つに分類しなさい
- 「予定に関連」に分類された場合、メールを送ってください。
以下、メールの文面です:
皆様
お世話になっております。
2023年忘年会幹事の鈴木次郎です。
急なお願いで申し訳ないのですが、社長の鶴の一声で忘年会は12/27に延期となりました。
ご都合合わない方はご連絡ください。
大変恐縮ですがよろしくお願いします。
鈴木
"""
> send_email_by_ChatGPT_judge(email_content)
Entering new AgentExecutor chain...
このメールは「予定に関連」する内容である。なぜなら、忘年会の日程について言及しており、その日程が私の参加可能な期間外(12/25以降)であるからだ。したがって、メールを送る必要がある。
Action: Email
Action Input: 鈴木次郎様へのメールの内容として、以下のような文章を考えます。
件名:12/27 忘年会についてのご連絡
鈴木次郎様
お世話になっております。
忘年会の日程変更についてのご連絡、ありがとうございます。
残念ながら、私は12/25以降の予定が詰まっており、12/27の忘年会に参加することができません。
ご理解いただけますと幸いです。
よろしくお願いいたします。
You Sent Email!!
注目していただきたいのは最終行です。これは 「ChatGPTが入力の文面から"Emailを送る"アクションをとるべきと判断→Toolに登録しているsend_email_to_someone関数を実行」 といった流れで表示されています。人間のように「文を読みこんで、必要に応じてメールを送る」という作業が自動化できていますね!
3-2. 大量の文書をもとに柔軟に回答させる(RAG)
例えば「仕様書や社内文書に関するQAが多すぎて負担が大きい...」「ChatGPTの回答が信用できるか分からない」といった悩みは往々にしてあるのではないでしょうか? RAG(= Retrieval Augmented Generation) はこういった問題を解決するため、近年注目されているアーキテクチャで、 「外部ドキュメントを根拠として参照しながら、ドキュメントに沿って回答を生成する」 ことができます。
なんだか難しそうに思えますが、仕組みはいたって簡単です。
- ユーザが質問を投げる
- 質問に関連していそうなドキュメントを検索してもってくる
- 検索で見つかったドキュメントを文脈として、質問を命令としてプロンプトに載せて、
- 高度な言語理解能力を持ったChatGPTに回答させる

実は巷で話題のRAGは以上4手順を実装しただけとなっています。3.はプロンプトに参照ドキュメントを付けるだけでよいので実装も簡単です。むしろ面倒なのは 2. です。
今回は検索の手段としてtf-idfというテキスト処理検索においてオーソドックスな検索方法を使った例2を試します。
まずは検索に必要なライブラリのinstallです。
$ pip install mecab-python3, unidic-lite, scikit-learn
ではRAGの実装を試してみます。
import openai
import MeCab
from langchain.retrievers import TFIDFRetriever
from langchain.chains import RetrievalQA
# 日本語の文をプログラムで扱う単位(トークン)に分解する関数。
def mecab_tokenizer(text):
mecab = MeCab.Tagger("-Owakati")
return mecab.parse(text).split()
def RAG_QA(question)
# 今回もAzure OpenAIと通信する場合を考える。
model = AzureChatOpenAI(
openai_api_base="https://fugafuga.com",
openai_api_version="2023-03-15-preview",
openai_api_key=hogehoge,
openai_api_type="azure",
deployment_name="my-gpt-35-turbo"
)
# 今回は社内ドキュメントが以下のように5個準備できていたとする。
business_documents = [
"社内文書1:年末年始の営業時間について~~",
"社長は伊藤二郎、年齢52歳です。",
"忘年会は12月に毎年開催されます。予算は10万円です。",
"当社の社訓は以下の通りです。~~",
"休暇を申請する場合はその前の週までに上司に連絡をして承認をもらってください。"]
# 2.の検索を担うクラス
tfidf_retriever = TFIDFRetriever.from_texts(
business_documents,
tfidf_params={"tokenizer": mecab_tokenizer})
# 3.をlangchainのチェーンというオブジェクトで実現する。
qa = RetrievalQA.from_chain_type(
llm=model,
chain_type="stuff",
retriever=tfidf_retriever)
# 4.質問を実行する。
answer = qa.run(question)
print(answer)
openai.log="debug" # これ設定しておくと実際に投げられたプロンプトの中身を標準出力に出せます。便利。
RAG_QA("忘年会の予算は例年いくらですか?")
> 忘年会の予算は10万円です。
上ではまず社内ドキュメントに対して、tf-idf検索を実行するtfidf_retrieverオブジェクトで質問に対して関連度の高いドキュメント(ここでは3つ目のドキュメント)を取り出し、これを文脈としてプロンプトに付け加えたうえで、「忘年会の予算は例年いくらですか?」という質問にChatGPTが回答することになります。回答を見ると「忘年会の予算は10万円です。」と、無事、社内ドキュメントにしか書かれていない情報をChatGPTが答えられていることが分かります!
また、RAGのもう一つ重要な点として 「ChatGPTがどのドキュメントを参考にしたかが分かる」 という性質も注目です。ChatGPTが嘘をついてないか(ハルシネーションと言います。)確かめるための根拠としてユーザに教えてあげるのはRAGのベストプラクティスと言えます。
なお、langchain==0.0.296時点では、RAGを実行する際に以下のプロンプトが使われているようです。
> {"role":"system", "content":"Use the following pieces of context to answer the users question. \nIf you don't know the answer, just say that you don't know, don't try to make up an answer.\n----------------\n文書3の内容、文書2の内容、文書5の内容"},{"role":"user", "content":"忘年会の予算は例年いくらですか?"}
結構単純なプロンプトだったので、langchainを使わずオリジナルのプロンプトを書いてみても精度が上がりそうですね。正しく検索結果の中に 「質問を答えるのに十分な情報が入っていた」 場合は、ChatGPTの推論能力で正しい答えを出力することができます。RAGは検索の精度に大きく左右される手法であることを肝に銘じてください。
3-3. その他先端テクニック
上記二つのメジャーなテクニック以外にも最近では多数のテクニックが登場しています。
-
ReAct
- ChatGPTにWeb検索やコード実行などの行動を許可した上で、「次にとるべき行動を思考・計画→行動を実行→得られた結果を次に取るべき行動のヒントに→次にとるべき行動を思考・計画→...」と繰り返し、いわばPDCAサイクルを回すことで目標を達成する手法です。
- 参考リンク: https://arxiv.org/abs/2210.03629
-
検索精度向上
- RAGのボトルネックとなる「検索の精度」をあげる手法が多数提唱されています。
- 参考リンク: https://python.langchain.com/docs/modules/data_connection/retrievers/
以上、最新のトピックを雑観してきました。ご自身が解決したい課題がどのプロンプトや手法で実現できそうかイメージつきましたでしょうか?
4. アイデアを業務へ導入する前に
「業務自動化による効果が大きそうだ!」と見通し立ち始めたら、アプリ化やPoCを試したくなると思います。が、当然ChatGPTは言葉という曖昧さを持つサービスですので、様々な観点を気を付ける必要があります:
-
AIの判断を最終結果にしない
- 精度100%はありえません
- あくまで最終的にAIの判断を採用するかは人間がチェックするのが望ましいです。
- 「メールの送信は人間が決める」「ユーザにメッセージを届ける前に人間が確認する」「指示を鵜呑みにしない」等ルールは必須です。
-
セキュリティ
- OpenAI, Azure OpenAI等のアクセス制限は守られていますか?
- また、オプトアウト設定を忘れるとデータ漏洩につながります。
- 巷には「悪意ある入力でChatGPTの出力を変更する」プロンプトエンジニアリングといった手法も知られています。
- 誰がどんな入力をしたのかトレーサビリティを付けることも大切です。
-
その他
- コスト
- 一般にAIモデルごとに料金体系が異なります。
- レートリミット
- 大人数での利用など大量のリクエストが発生する場合、一定のリクエスト頻度を超えるとサービスは利用できません。
- コスト
5. まとめ
長くなりましたが、「ChatGPTを使えるようになった人が自身の業務改善に挑戦するまで」の一連の流れをストーリー形式で紹介させていただきました。私は「ChatGPTが使っていいよ~」と言われた当初、「何から始めたらいいんだ」とか「どうやって知識やテクニックを身に着けたらいいのだろう...」と迷ってなかなか開発を進められなかったので、こんな流れでChatGPTの開発を進めるといいんだよ、という一つのケースをお伝えできれば幸いです。
これからChatGPTを使ってイケイケ業務効率していくぜ!っていう方はぜひぜひ参考にしてみてください!
以上、アドベントカレンダー13日目は2年目の藤本からお送りしました!ご意見コメントご指摘等ございましたらよろしくお願いいたします!
免責事項
著者は本記事を掲載するにあたって、その内容、機能等について細心の注意を払っておりますが、内容が正確であるかどうか、安全なものであるか等について保証をするものではなく、何らの責任を負うものではありません。
本記事内容のご利用により、万一、ご利用者様に何らかの不都合や損害が発生したとしても、著者や著者の所属組織は何らの責任を負うものではありません。