本記事では、MFCC(メル周波数ケプストラム係数)入門の記事で見かけたDeep Learning for Audio Signal Processingの論文で特徴量抽出をMFCCからlog-mel スペクトルにして深層学習にするとよい、というヒントから実践してみた記事です。
メル尺度
メル尺度は、定性的には人間の音高の知覚的尺度です。数式的定義は次のようになります。
m = m_{o} \log\left(\frac{f}{f_o} + 1\right)
ただし、$f_o$はパラメータの一つの周波数パラメータで、$m_o$は「1000Hzは1000メル」という制約から導かれる式、
m_{o} = \frac{1000}{\log\left(\frac{1000\rm{Hz}}{fo} + 1\right)}
で算出される従属パラメータです。グラフにすると次のようになります。
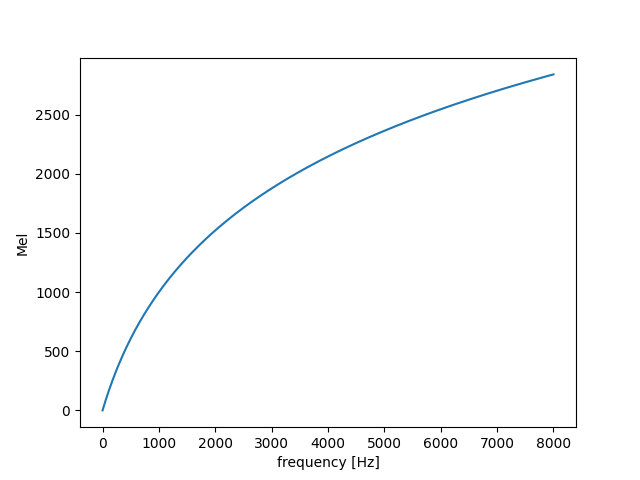
人間の聴覚は、周波数が低い音に対して敏感であり、周波数の高い音に対しては鈍感です。そのことを反映した尺度になります。
音声データの周波数をメル尺度にして、データを圧縮したMFCC(メル周波数ケプストラム係数) はここ数十年の間、音声認識の特徴量抽出としてよく使われています。
MFCCとlog-mel スペクトルの解釈の比較
ここで冒頭で紹介したlog-mel スペクトルですが、フィルタバンクで圧縮せず、ケプストラムも用いません。周波数領域をメル尺度にして、すべてのデータを特徴量とするのが今回の方法です。そのため、後者の方が理解しやすいです。
MFCCとlog-mel スペクトルのアルゴリズムの比較は次のようになります。
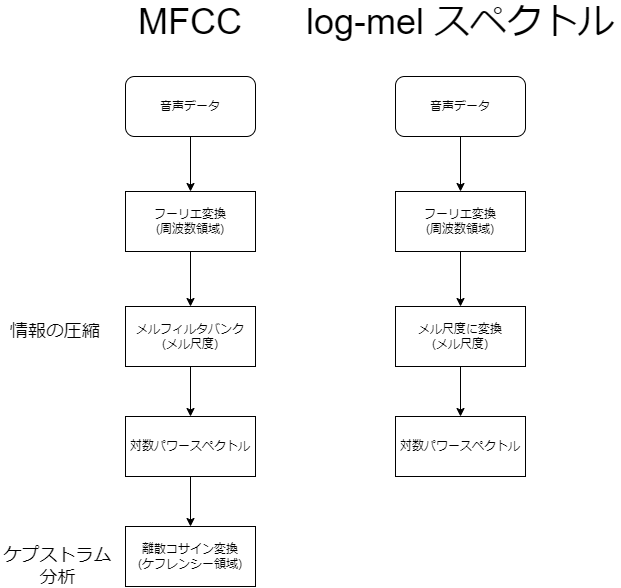
サンプリングレートが8kHzで1秒のデータだと、MFCCでは特徴量のデータ長は20程度と固定されていますが、log-mel スペクトルではナイキスト周波数を考慮し4000ものデータ長になります。
深層学習に入力する際に、情報を失わせることのない特徴量とすることがlog-mel スペクトルの狙いです。そのため、フィルタバンクは用いません。
log-mel スペクトルのサンプル
上記のlog-mel スペクトルを実装してみます。
1. 音声データをフーリエ変換する
dft = np.abs(np.fft.fft(data))[:int(N/2)]
dataオブジェクトが今回の音声データになります。
周波数に変換する際、ナイキスト周波数を考慮し、データを半分にします。
2. メル尺度に変換する
初めにメル尺度に変換する式を実装します。hz2mel関数を呼び出すと、メル尺度に変換できるようにします。
ここで上記で説明した周波数パラメータ$f_{o}$は700Hzを用いることにします。
mel = 1000
fo = 700
def calc_mo(self):
"""
Functions for determining dependent parameters of the Mel scale.
"""
return mel / np.log((mel / fo) + 1.0)
def hz2mel(self, f):
"""
Convert Hz to mel.
"""
mo = calc_mo()
return mo * np.log(f / fo + 1.0)
そして、フーリエ変換した周波数領域をメル尺度に変換します。
mel_spec = hz2mel(dft)
3. 対数パワースペクトル
最後に対数パワースペクトルに変換します。
log_mel_spec = 10*np.log10(mel_spec**2)
これで、log-mel スペクトルの特徴量ができました。MFCCでメルフィルタバンクを実装しない分、かなり簡潔に記述できます。
MFCC&SVM vs log-mel スペクトル&深層学習
MFCCを特徴量とした場合、SVM(サポートベクトルマシン)が常套手段です。そして、log-mel スペクトルを深層学習に入れた場合の正解率を比較します。
今回使用したデータセット
今回のデータセットは、Attribution-ShareAlike 4.0 International (CC BY-SA 4.0)のJakobovskiらによるFree Spoken Digit Datasetを使用しました。
【GitHub】 free-spoken-digit-dataset
6人のスピーカーが0~9の音声を約1秒間だけ発する音声が収録されており、上記のGitHubよりダウンロードできます。
【結果】正解率の比較
正解率は次のようになりました。
| 線形SVM | 深層学習 | |
|---|---|---|
| MFCC | 83.6% | -- |
| log-mel スペクトル | -- | 92.6% |
MFCCを比較すると、各段に正解率が上昇しました。
おそらくですが、MFCCは数十年前から使われているというということを考えてみると、計算資源が少なかったという歴史的背景があるかと思います。
今は富豪的プログラミングで4桁もの特徴量も数秒で結果を得られてしまいます。log-mel スペクトルといった膨大な特徴量がよしとされる時代が来ているのかもしれませんね。
結果については、次のソースコードで再現可能です。
【GitHub】log-mel_spec_DeepLearning_TEST
k分割交差検証法(k=5)を利用しているので、正解率には変動がありますのでご了承ください。それでも必ず近い値になります。
まとめ: GitHubに公開中
今回は論文の検証をしました。論文の誤読だとか、検証が間違っているとかいろいろ突っ込むところはあるかもしれませんが、参考としてこの記事を利用していただければ幸いです。
log-mel スペクトルの実装は次のGitHubのリポジトリに保管しています。よかったらご利用ください。
[【GitHub】 log-mel spectrum] (https://github.com/OkamotoDaiki/log-mel_spectrum)