こちらの書籍を読んだので備忘録です。
https://www.amazon.co.jp/dp/B00LHFOTF4/ref=dp-kindle-redirect?_encoding=UTF8&btkr=1
手順
1、どこに問題があるのかを調べる
2、なんで問題が起きているのかを調べる
3、対応(≒実装)する
4、テストして修正の確認
そりゃそうだろうと怒られそうですが、上記にしたがって書いていきます。
1、どこに問題があるのかを調べる
調べるときは「はさみうちの原理」で調べた方が良いです。
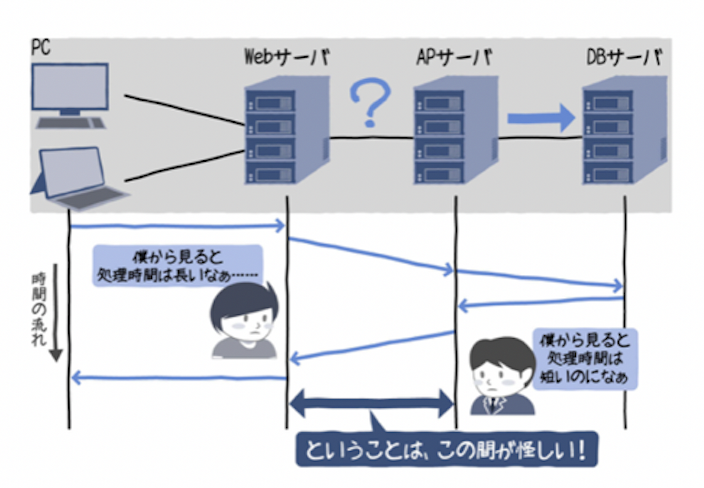
書籍より抜粋
上記のようなシステムを考える場合、レスポンスが遅いところをピックアップしながら探します。
調査する際には様々なコマンドが使えます。
2~4、原因の調査=>対応=>テスト
問題が起きている箇所が特定できたら「そこでどんな処理を行なっているのか」を調べます。
この際遅くなっている原因はソート等のアルゴリズム、DBへの書き込み、キャッシュの有無等様々な要素が絡みます。
対応するときの定石として、「大きいものから一つずつ解決する」というものがあります。
大きい問題に埋もれて別の問題が隠れている可能性があるのと、
解決したと思ったらそれが原因で別の問題が起きる可能性があるためです。
なので
原因の調査=>対応=>解決したと思ったらテスト
を繰り返すことになります。
対応する際のよくあるパターン
解決パターンとして使える考え方をまとめます。
できるだけ再利用する
DBのコネクションプール、Webのキープアライブ、APサーバーのスレッドプール等、再利用できる仕組みは多数あります。
パフォーマンスの改善につながるので、できるだけ利用するようにしましょう
設定をほどほどにする
コネクションプールの最大数、メモリサイズ、スナップショットの間隔など、自分で設定できるものがありますが、大きい方がいいからといってあまり大きくしすぎると他を圧迫することがあります。
設定する際には他との兼ね合いを見ながら少しずついじりましょう
まとめて処理をする
ログの書き出し、DBへの書き込みなど、回数に比例して時間がかかる処理に関しては、バッチを使う等してまとめてやった方が早いことがあります。
ただし、これもほどほどにしないと大量のデータ更新が起こることになり、かえって遅くなるケースもあります。
高速化と並列化
CPUのクロック数、コア数を上げる等がこれにあたります。
ただ、高速化は万能ですが並列化に関しては適してるかどうかの吟味が必要です。
並列にしても遊んでいるスレッドがあれば効果は得られませんし、処理の順番、デッドロックに気をつける必要があります。
スケールアップとスケールアウト
同一サーバーのパフォーマンスを上げるのがスケールアップ、稼働サーバー自体を増やすのがスケールアウトです。
APサーバー等、各々の処理が独立しているものはスケールアウト向けですが、そうでないものはスケールアップの方が向いてます。
局所性
データの処理に偏りが出ることを局所性といい、時間的、空間的、逐次的の3種類があります。
時間的局所性
最近アクセスされたデータは近いうちにまたアクセスされるという考え方です。
キャッシュはこの考え方を使っています。
空間的局所性
使われたデータの近くにあるデータほど使われる可能性が高いという考え方です。
ブロックやページ、エクステント等「塊」で処理する利点がここにあります。
逐次的局所性
使われたデータの隣が使われることが多いという考え方です。
これらの局所性を考えることでパフォーマンスが向上することが多々ありますが、
開発環境で本番環境並みの局所性を再現するのはとても難しいです…
現場で用いられるテクニック
上記の考え方を実現するために、どう実装/対応すればよいのかをまとめます。
ループ、サーバー間の問い合わせの省略
例えば、
for(int i = 0; i < 100; i++){
selectById(i);
}
より、
List<Integer> idList;
for(int i = 0; i < 100; i++){
idList.add(i);
}
selectByIdList(idList);
の方が早いことがあります。
前者は100回データの問い合わせが発生するのに対し、後者は一回しか問い合わせが発生しないからです。
また、多くのデータを取ってくる方が結果的にフルスキャンで早く済むこともあります。
よく使うデータはキャッシュ化
言わずもがなですかね…
よく使うデータはいちいちDBに問い合わせするよりは、APサーバー内においておいた方が余計な通信を減らせます。
同期を非同期に変える
同期処理は他の処理が終わるまで待つことになるため、独立した処理なら非同期の方が良いことがあります。
また非同期処理なら同期処理で使ってたぶんのリソースを他の部分に咲くこともできます。
ただ管理は大変になるのでそこは注意。
帯域制御
リクエストが一定まで増えたら帯域制御によって受け付けず、「すいません混んでます」のような画面に飛ばすことも重要です。
こちらはコストも関わってくると思いますが、待ち行列理論のグラフのように全体が重くなるよりはマシという考え方になることが多い気がします。
LRU方式
Least Recently Usedの略で、しばらく使われなかったデータをすてる仕組みです。
DBMSやストレージの内部でよく使われます。
ただ、「洗い替え」とも呼ばれるデータの総入れ替え処理等、たまにしか使われないデータにキャッシュが汚される可能性もありますので、そこは注意です。
処理の分割 or ロック粒度の細分化
ロックを大きくしすぎると必要以上に他の処理が待たされることがあります。
安全性の面からロックは大事ですが、必要なぶんだけロックしているか確認した方が良いです。
負荷分散、ラウンドロビン
複数のサーバーで処理をする際、遊んでいるサーバーが出ないように均等に割り振る仕組みをラウンドロビンといい、これを行う機器をロードバランサと呼びます。
AWS等で採用されており、これをすることによって負荷が分散され、スケールアウトの恩恵が大きくなります。
まとめ
基本的には、
・不必要な通信を減らす
・待たなければいけないところは最小限に
・それでもだめなら負荷をどこかに分散させる
といった対策になります。