IPFactory Advent Calender 2022 24日目の記事です。
重回帰分析
重回帰分析とは機械学習モデルを作成する際の説明変数(特徴量)が二つ以上存在する回帰分析を意味します。
また、説明変数が一つである回帰分析を単回帰分析と呼びます。
多重共線性
多重共線性とは重回帰分析の際の説明変数(特徴量)の中に相関の高い組み合わせが存在することです。
説明変数は他にも様々な呼び方が存在します。
- 特徴量
- 独立変数
- 予測変数
説明変数は独立変数とも呼ばれるように他の説明変数と相関があってはいけません。
では、なぜ説明変数との間に相関があってはいけないのでしょうか。
コードを見ながら解析していきたいと思います。
#pandasのimport
from google.colab import drive
drive.mount('/content/drive')
import pandas as pd
%cd /content/drive/MyDrive/Colab Notebooks/LT_work
#csvファイル読み込み
df = pd.read_csv('LT.csv')
df #Jupyter Notebookなどではこれだけで実行できます。print(df)と同義です。
今回は目的変数が「家賃」で説明変数が「面積」「築年数」「駅からの距離(分)」であるデータフレームを扱います。
家賃 面積 築年数 駅からの距離
0 55000 19.8 16 10
1 53000 23.1 19 13
2 71000 29.0 16 5
3 60000 32.1 20 12
4 62000 20.1 10 5
5 56000 23.5 12 10
6 64000 21.1 2 4
7 55000 25.7 21 10
8 57000 19.6 16 8
9 59000 15.4 18 10
10 73000 24.9 9 2
11 50000 23.0 39 18
12 53000 23.7 18 11
13 65000 19.9 5 3
14 55000 21.0 18 12
15 42000 22.5 36 20
16 72000 24.3 1 2
17 66000 27.0 15 6
18 55000 21.1 17 7
19 51000 18.9 34 13
多重共線性を確認する前に説明変数を「面積」「築年数」に絞ってモデルに学習させていきたいと思います。
df_part = df[['家賃', '面積', '築年数']]
df_part
家賃 面積 築年数
0 55000 19.8 16
1 53000 23.1 19
2 71000 29.0 16
3 60000 32.1 20
4 62000 20.1 10
5 56000 23.5 12
6 64000 21.1 2
7 55000 25.7 21
8 57000 19.6 16
9 59000 15.4 18
10 73000 24.9 9
11 50000 23.0 39
12 53000 23.7 18
13 65000 19.9 5
14 55000 21.0 18
15 42000 22.5 36
16 72000 24.3 1
17 66000 27.0 15
18 55000 21.1 17
19 51000 18.9 34
df_part.dtypes #データの型の確認
家賃 int64
面積 float64
築年数 int64
dtype: object
全て数値型なので扱えそうです。
学習に使用するライブラリをimportしてモデルに学習させていきます。
# データ分割(訓練データとテストデータ)のためのインポート
from sklearn.model_selection import train_test_split
#import sklearn.model_selection.train_test_split
# 重回帰のモデル構築のためのインポート
from sklearn.linear_model import LinearRegression
# 目的変数にpriceを指定、説明変数にそれ以外を指定
X = df_part.drop('家賃', axis=1)
y = df_part['家賃']
# 訓練データとテストデータに分ける
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=77)
# 重回帰クラスの初期化と学習
model = LinearRegression()
model.fit(X_train, y_train)
# 決定係数を表示
print('決定係数(train):{:.3f}'.format(model.score(X_train, y_train)))
print('決定係数(test):{:.3f}'.format(model.score(X_test, y_test)))
# 回帰係数と切片を表示
print('\n偏回帰係数\n{}'.format(pd.Series(model.coef_, index=X.columns)))
print('切片: {:.3f}'.format(model.intercept_))
決定係数(train):0.649
決定係数(test):0.823
偏回帰係数
面積 582.887852
築年数 -580.043607
dtype: float64
切片: 55607.793
決定係数(test)を確認すると(0.823)とそこそこ良い精度が出ています。(1.0がMAXです。)
ここで重要なのは偏回帰係数です。今回のモデルから次のような数式が成り立ちます。
ŷ = 582.887852$\color{red}{\rm X1}$1 +(-580.043607)$\color{Blue}{\rm X2}$2 + 55607.7933
この数式から読み取れること
- 面積に比例する
- 築年数に反比例する
次に説明変数同士の相関を確認します。
df_part.corr()#説明変数間の相関
家賃 面積 築年数
家賃 1.000000 0.302515 -0.773819
面積 0.302515 1.000000 -0.012750
築年数 -0.773819 -0.012750 1.000000
多重共線性は説明変数に注目するので今回の場合であれば「面積」と「築年数」の相関を確認します。
相関は -0.012750となっているので問題はなさそうです。
さて、今度は先ほど説明変数から外した駅からの距離(分)を追加して考えていきたいと思います。
データフレームはこんな感じです。
家賃 面積 築年数 駅からの距離
0 55000 19.8 16 10
1 53000 23.1 19 13
2 71000 29.0 16 5
3 60000 32.1 20 12
4 62000 20.1 10 5
5 56000 23.5 12 10
6 64000 21.1 2 4
7 55000 25.7 21 10
8 57000 19.6 16 8
9 59000 15.4 18 10
10 73000 24.9 9 2
11 50000 23.0 39 18
12 53000 23.7 18 11
13 65000 19.9 5 3
14 55000 21.0 18 12
15 42000 22.5 36 20
16 72000 24.3 1 2
17 66000 27.0 15 6
18 55000 21.1 17 7
19 51000 18.9 34 13
先ほど同様に学習させていきます。
# データ分割(訓練データとテストデータ)のためのインポート
from sklearn.model_selection import train_test_split
#import sklearn.model_selection.train_test_split
# 重回帰のモデル構築のためのインポート
from sklearn.linear_model import LinearRegression
# 目的変数にpriceを指定、説明変数にそれ以外を指定
X = df.drop('家賃', axis=1)
y = df['家賃']
# 訓練データとテストデータに分ける
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=77)
# 重回帰クラスの初期化と学習
model = LinearRegression()
model.fit(X_train, y_train)
# 決定係数を表示
print('決定係数(train):{:.3f}'.format(model.score(X_train, y_train)))
print('決定係数(test):{:.3f}'.format(model.score(X_test, y_test)))
# 回帰係数と切片を表示
print('\n回帰係数\n{}'.format(pd.Series(model.coef_, index=X.columns)))
print('切片: {:.3f}'.format(model.intercept_))
決定係数(train):0.874
決定係数(test):0.908
回帰係数
面積 509.347696
築年数 180.677482
駅からの距離 -1741.097890
dtype: float64
切片: 59492.377
決定係数(test)を確認すると(0.908)とかなりモデルの精度が上がっていることがわかります。
わーい!!!機械学習余裕じゃん!
なわけないですね。
モデルを数式に置き換えましょう。
ŷ = 509.347696$\color{red}{\rm X1}$1 + 180.677482$\color{Blue}{\rm X2}$2 + (-1741.097890)$\color{Green}{\rm X3}$4 + 59492.3773
この数式から読み取れること
- 面積に比例する
- 築年数に比例する
- 駅からの距離(分)に反比例する
問題なさそうで…
ん?
よくないですね。
二つ目の築年数に比例するというのはおかしな話です。年数が経つほど家賃が高くなっているわけです。場所によってはこのようなこともあり得るでしょう。
しかし、今回は歴史的な背景などは一切考慮していないので、この数式は今回のデータの本質にそぐわないと言えるでしょう。
説明変数の相関を確認してみましょう。
df.corr()
家賃 面積 築年数 駅からの距離
家賃 1.000000 0.302515 -0.773819 -0.902120
面積 0.302515 1.000000 -0.012750 -0.049631
築年数 -0.773819 -0.012750 1.000000 0.895848
駅からの距離 -0.902120 -0.049631 0.895848 1.00000
ここで確認してほしいのが「築年数」と「駅からの距離(分)」の相関です。
(0.895848)と異常に高いことがわかります。
これが多重共線性です。
$\color{red}{\rm このように説明変数間に相関の高い組み合わせが存在することによって、}$
$\color{red}{\rm 重回帰モデルにおける偏回帰係数の推定ができなくなったり推定精度が低くなることがあります。}$
今回はモデルの精度が非常に良かったのですが、そもそも学習用データも評価用データも少なすぎるので、たまたま良い結果が出ただけです。
膨大なデータに対して評価を行えば大きく外れた値を予測すると思われます。
さて、まとめに入りたいと思います。
このように、タジュウキョウセンセ...
嘘です。まだ終わりません。
以前のLT大会の際、素人のフリをした先輩からこんな質問をいただきました。
f先輩「多重共線性を見分ける際の数値は相対的に判断するのか、絶対的に判断するのかどうなんでしょうかね」(多分こんな感じ)
Ogi[…わからん(心の声)]
盲点でした。定量的な視点で解説しているのに閾値についての説明がないのは論外でした。
ということで、調べました。
どうやら多重共線性を判定する際には、相関係数では不適切であり、代わりに分散拡大要因(Variance Inflation Factor: VIF)を用いて判定することが推奨されているそうです。ではなぜ相関係数では不適切なのでしょうか。
それは、相関係数が2変数間の関係だけしか見ていないからです。
多変量解析の分析なら、多変量の相関で考えるべきなので、2変数間の関係しかみれない相関係数だと、不十分なのです。
それに対してVIFは全ての変数を使って計算していますので、多変数間の相関も考慮してくれます。
また、正確に基準が定まっているわけではないようですが、VIFの値が$\color{red}{\rm 10}$を超えると多重共線性を認めていると言えるそうです。
ただVIFが10というのも、かなり甘めの基準であるようです。
本来多変量解析は説明変数(独立変数)同士が全く相関していない状態であることが望ましいようです。
VIFを使ってみた
まずは、駅からの距離(分)を説明変数から除いた状態で検証します。
#statsmodelsのvifをインポート
from statsmodels.stats.outliers_influence import variance_inflation_factor
import matplotlib.pyplot as plt
#vifを計算する
vif = pd.DataFrame()
vif["VIF Factor"] = [variance_inflation_factor(X.values, i) for i in range(X.shape[1])]
vif["features"] = X.columns
#vifを計算結果を出力する
print(vif)
#vifをグラフ化する
plt.plot(vif["VIF Factor"])
VIF Factor features
0 3.708043 面積
1 3.708043 築年数

VIFが10は超えていないので、多重共線性は認められないと言えます。
次に駅からの距離(分)を説明変数に加えて検証していきます。
VIF Factor features
0 4.065405 面積
1 20.420843 築年数
2 22.247159 駅からの距離
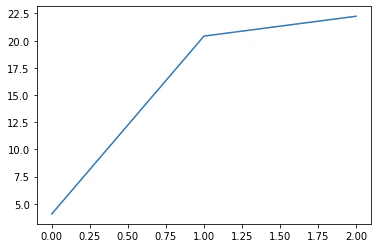
あ~アウトですね。
10を超えてしまいましたね。VIFを用いて再度多重共線性を確認することができました。
このようにVIFを用いて多重共線性を定量的に判断するというのが質問の回答になります。
まとめ
なんかいろいろ書きすぎて何について書いていたんだかもう忘れました。
それより本当はもっと面白いネタ記事を書きたかったんですよ。
クリスマス前の破局率とかなんとかかんとか。
数値データないかな~ってずっと探してたんですよ。でも全然良いのなくて...
facebookのでーた
facebookもなんかショーもないこと調べてるし、暇かよ働け
そんな感じで考えに考えた末何の成果も得られませんでした!!
引用元:進撃の巨人

最後に
というわけで、もうクリスマスですね。いい感じの締めの言葉が思いつかなかったので、伝説的名言とやらから厳選していい感じに締めたいと思います。
最後まで読んでいただきありがとうございます。m(__)m
それでは、良いクリスマスを。
ジョン・レノン
そう、これがクリスマス。僕たちは何をしてきたのか?また1年が終わり、新しい年が今始まったばかり。だから、メリークリスマス。みんなが笑顔になりますように。近くにいる人たちにも大切な人たちにも。年老いた人にも若い人にも。
マザー・テレサ
兄弟にほほえみかけ、助けの手を差し伸べるたびに、それがクリスマスなのです。
ヘンリー・ヴァン・ダイク
最高のクリスマスプレゼントは一番お金をかけたものではなく、一番多くの愛がこもっているもの。
小沢一敬/セカオザ(スピードワゴン)
イエスの生まれた日にノーは言わせない。
Ogi*****
リア充〇発しろ
引用元:HUNTER×HUNTER
