今回はテンプレートを活用してDeepResearchエージェントを構築すること
その上でDifyの活用用途について考えてみることにしました。
Difyとは
端的に言うとノーコード生成AIアプリケーション構築ツールとなります。
タグ説明をみて頂くのが早いです。
タグ説明より引用
Difyは、2023年に登場した、AIアプリケーションを構築するためのオープンソースプラットフォームです。Backend-as-ServiceとLLMOpsの概念を融合させ、開発者や非技術者が生成AIアプリケーションソリューションを効率的に開発できるようにしています。
DeepResearchテンプレートを理解する
Difyにはいくつかの用途別テンプレートが準備されています。
医療機関向けのCSチャットボットや変わったところでは投資分析エージェントなど。
今回は最近大変お世話になっている、DeepResearchが自前で作れるということで
DeepResearchテンプレートを使ったエージェントを作成してみることにしました。
テンプレートを選択すると、このようにワークフローが展開されます。何をどの程度
いじればよいのかわからないので、ざっと各ノードの意味を読解することにします。
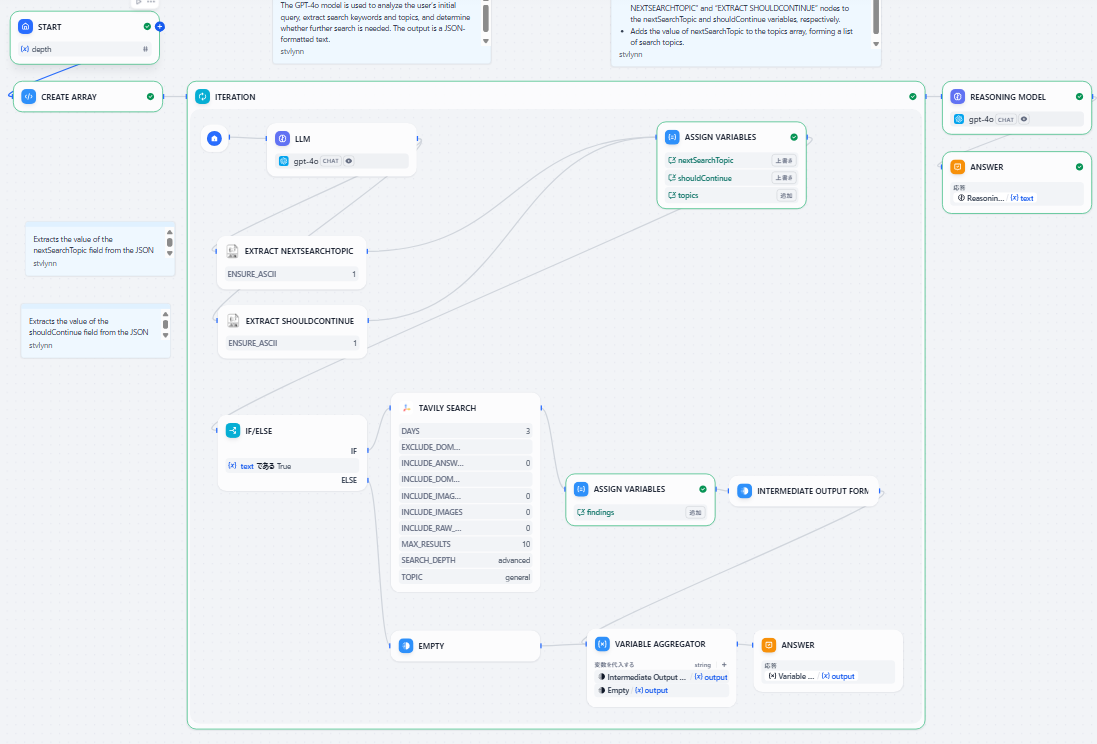
このワークフローは、大きく分けて「①初期設定」「②反復調査」「③最終的な回答生成」の3つのフェーズで構成されています。
① 初期設定フェーズ (START → CREATE ARRAY)
START (開始)
ワークフロー全体の開始点です。
depth(深さ)という、調査を何回繰り返すかの基準となる数値を入力として受け取ります。
CREATE ARRAY (配列作成)
STARTで受け取ったdepthの数値をもとに、反復処理を制御するための配列を作成します。
② 反復調査フェーズ (ITERATION)
ここが調査の中核部分です。指定された回数、またはAIが必要だと判断する限り、以下のサイクルを繰り返します。
LLM (大規模言語モデル)
役割: 調査の司令塔です。デフォルトではgpt-4o-miniが使われていました。
処理: ユーザーの初期クエリや、前のサイクルで得られた検索結果を分析します。その上で、「次に何を検索すべきか(nextSearchTopic)」と「調査をまだ続けるべきか(shouldContinue)」を判断し、JSON形式で出力します。
EXTRACT NEXTSEARCHTOPIC / EXTRACT SHOULDCONTINUE (情報抽出)
役割: LLMが出力したJSONから、必要な情報を取り出します。
処理: nextSearchTopic(次の検索トピック)と shouldContinue(継続フラグ:True/False)の値をそれぞれ抽出します。
ASSIGN VARIABLES (変数割り当て - 上)
役割: 抽出した情報を整理し、記録します。
処理:nextSearchTopicとshouldContinueをそれぞれ変数に保存します。
nextSearchTopicの値をtopicsというリスト(配列)に追加し、これまでの検索トピックの履歴を保持します。
IF/ELSE (条件分岐)
役割: 調査を続けるかどうかの分岐点です。
処理: shouldContinue変数の値がTrueであればTAVILY SEARCHへ進み、Falseであれば反復調査を終了し、最終的な回答生成フェーズへ移行します。
TAVILY SEARCH (ウェブ検索)
役割: 実際のウェブ検索を実行します。
処理: LLMが指示したトピックに基づき、Tavily検索エンジンを使ってウェブを検索します。ここでは「直近3日間」「最大5件」「高度な検索」といった条件が設定されています。このあたりで出力に関するチューニングが行えそうです。
ASSIGN VARIABLES & INTERMEDIATE OUTPUT (中間結果の保存)
役割: 検索結果を一時的に保存します。
処理: 検索で得られた結果(findings)を変数に割り当て、後で集約できるように中間的な出力として保持します。このサイクルが終了すると、再び3. LLMに戻ります。
③ 最終的な回答生成フェーズ (REASONING MODEL)
反復調査が完了した後の最終ステップです。
VARIABLE AGGREGATOR (変数集約)
役割: これまでの調査結果をすべて集めます。
処理: 反復調査の各サイクルで保存されたすべての中間的な出力(検索結果)を一つにまとめます。
REASONING MODEL (推論モデル)
役割: 最終レポートを作成します。プリセットでは、deepseek-reasonerが使われています。
処理: 集約されたすべての検索結果を包括的に分析、要約し、論理的なレポートや回答を生成します。
ANSWER (回答)
役割: 最終成果物の出力です。
処理: REASONING MODELが生成したテキストを最終的な回答として出力します。
構築と動作確認
大体はテンプレートの通りで稼働させることができそうです。REASONING MODELに指定されているdeepseek-reasonerをGPTに変更し、TAVILY SEARCHで指定されている検索範囲を若干広げて、プレビュー機能で動作させてみることにしました。
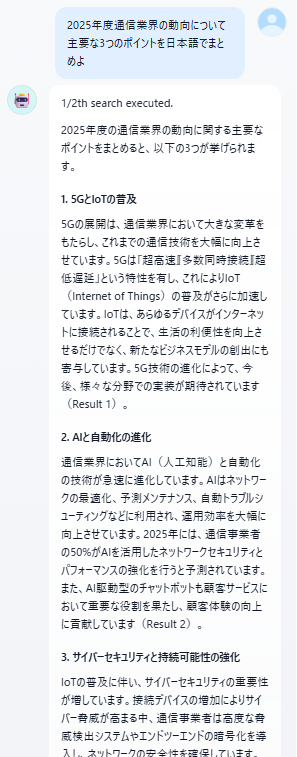
はい。概ね想定通りの出力が得られました。一方でそれほど深いアウトプットはテンプレートの状態ではしてくれなかったので、このあたりは若干のチューニングが必要となりそうです。
まとめ
エディタのUIは良い操作性です。ノードの追加や接続はクリック&ドラッグでできます。各変数の意味を理解するのに少し骨が折れるのはノーコードツールあるあるですが、LLMボットに質問すると大体回答されました。ノード間の変数のやりとりはわりと理解しやすいよう思います。
一方、フロー上で何をしているのかの理解は結局必要になります。この「理解」をするかどうかは人によりますが、本ツールはエンドユーザ向けの、市民開発を志向したアプリケーションというより、エンジニアリング寄りのアプリケーションであると理解しました。
(これは私自身に若干の誤解があり、認識を改めることができました)
冒頭のタグ説明においてもそのことがわかります。
タグ説明より引用
主な用途
スタートアップのMVP開発: AIアプリケーションのアイデアを迅速に実現
LLM技術の探索: プロンプトエンジニアリングやエージェント技術の実践
既存ビジネスへのLLM統合: 現有システムにAI機能を追加
企業向けLLMインフラストラクチャ: 中央集権的なAI管理と監視
生成AIエージェント開発におけるMOCK作成や技術探索においては非常に強力なツールとなりそうです。一方でDevinやCursor、ClineといったAIコードアシスタントも同じ用途において、非常に強力なツールです。エンジニアリング寄りのツールという立ち位置にて、本ツールをAIコードアシスタントツールに対してどのように位置づけ、活用していくのか、今後探索が求められるように感じました。