Webスクレイピングとは?
Wikiでの紹介はこうです:ウェブスクレイピング(英: Web scraping)とは、ウェブサイトから情報を抽出するコンピュータソフトウェア技術のこと。ウェブ・クローラーあるいはウェブ・スパイダーとも呼ばれる。 通常このようなソフトウェアプログラムは低レベルのHTTPを実装することで、もしくはウェブブラウザを埋め込むことによって、WWWのコンテンツを取得する。
Webスクレイピングはどのように動作しますか?
一般に、Webページをスクレイピングするとき、わずか2つのステップがあります。
Webページを取得する→ページから特定のデータをスプレッドシートまたはデータベースにコピーする
Webスクレイピングはどのように始まったのですか?
多くの人にとって、「ビッグデータ」や「機械学習」のような新鮮なテクニックのように聞こえるが、Webスクレイピングの歴史は実際にははるかに長く、World Wide Web(以下はWWWを略する)または俗に「インターネット」が生まれた時代に大きく後戻りしています。
始まりの時、インターネットは検索さえできませんでした。検索エンジンが開発される前は、インターネットはユーザーが特定の共有ファイルを見つけるためにファイル転送プロトコル(FTP)サイトの集まりに過ぎませんでした。インターネット上で利用可能な分散データを見つけて整理するために、インターネット上のすべてのページを取得し、データベースにコピーして索引が付けられる特定の自動化プログラム(Webクローラー/ボット)は作成されました。
その後、インターネットが成長し、最終的に何百万ものWebページのホームになり、テキスト、画像、ビデオ、オーディオなどを含む豊富でオープンなデータソースに変わります。
データソースが非常に豊富で簡単に検索できるようになるにつれて、様々なWebサイトに分散している情報を探すのが簡単になりました。しかし、インターネットからデータを取得したい時、すべてのWebサイトでダウンロードオプションが提供されているわけではなく、面倒で非効率な手作業でコピーするのが明らかに問題になります。
それで、Webスクレイピングが登場しました。実際に、Webスクレイピングは検索エンジンで使用されているものと同じように機能するWebボット/クローラによってサポートされています。つまり、取得とコピーすることです。唯一の違いは規模かもしれません。Webスクレイピングは特定のWebサイトからの特定のデータのみを抽出し、検索エンジンはインターネットのほとんどのWebサイトを取得します。
- タイムライン
· 1989年 WWWの誕生
技術的には、WWWはインターネットとは異なります。前者は情報空間を指し、後者はコンピュータで構成されるネットワークを指します。
WWWの発明者であるTim Berners-Leeのおかげで、私たちの日常生活の一部であった以下の3つのことをもたらしました。
- 望むWebサイトに行くために使うUniform Resource Locators(URL、インターネット上のページや画像、文章などの場所を示したアドレス)。
- Webページ間をナビゲートするための埋め込まれたハイパーリンク(たとえば、どこで製品仕様を探すのか)。
- テキストだけでなく、画像、オーディオ、ビデオ、ソフトウェアコンポーネントも含むWebページ。
· 1990年 最初のWebブラウザの誕生
またTim Berners-Leeによって発明されたWorldWideWeb(スペースなし)と呼ばれ、WWWプロジェクトに名付けられました。Webの登場から1年後、人々はそれを見てそれとやり取りする方法を持っていました。
· 1991年 最初のWebサーバーと最初のhttp:// Webページの誕生
Webはやや穏やかな速度で成長し続けました。1994年までに、HTTPサーバーの数は200台を超えました。
· 1993年6月 最初のWebロボット - World Wide Web Wanderer
今のWebロボットと同じように機能しましたが、Webのサイズを測定することのみに使われていました。
· 1993年12月 最初のクローラベースのWeb検索エンジン - JumpStation
Web上で利用可能なWebサイトがあまりないため、当時の検索エンジンは、人のWebサイト管理者がリンクを収集して特定のフォーマットに編集することに依存していました。
JumpStationは新しい進歩をもたらしました。これは、初めてWebロボットに依存するWWW検索エンジンです。
それ以来、人々はこれらのプログラムによるWebクローラーを使用してインターネットを収集し、整理し始めました。 Infoseek、Altavista、Exciteから、今のBingとGoogleまで、検索エンジンボットのコアは同じです:
Webページを見つけてダウンロード(取得)し、Webページに表示されているすべての情報をスクレイピングし、検索エンジンのデータベースに追加します。
Webページは人間のために設計されたものであり、自動化された使い方ではないため、Webボットの開発にもかかわらず、コンピュータ技術者や科学者にとっては、普通の人はもちろんのこと、Webスクレイピングを行うのはまだ難しいです。だから、人々はWebスクレイピングをより利用しやすくすることに専念してきました。
· 2000年 Web APIとAPIクローラー
APIはApplication Programming Interfaceの略で、ソフトウェアコンポーネントが互いにやりとりするのに使用するインターフェースです。
2000年、SalesforceとeBayは独自のAPIを発表しました。これにより、プログラマは公開されているデータの一部にアクセスしてダウンロードできるようになりました。
それ以来、多くのWebサイトでは、人々が公開データベースにアクセスするためのWeb APIを提供しています。
Web開発においては、APIは一般にHTTP要求メッセージ群とXMLまたはJSON形式などの応答メッセージの構造定義で構成されます。
Web APIは、Webサイトによって提供されるデータを収集するだけで、開発者にWebスクレイピングを行うためのよりフレンドリな方法を提供します。
· 2004年 Python Beautiful soup
すべてのWebサイトがAPIを提供するわけではありません。たとえそれがあっても、望むすべてのデータを提供するわけではありません。だから、プログラマーはまだWebスクレイピングを容易にする方法を開発しようとしていました。
2004年にBeautiful soupがリリースされ、Python用に設計されたライブラリです。
コンピュータプログラミングでは、ライブラリは一般的に使用されるアルゴリズムのようなスクリプトモジュールの集合であり、書き換えなしで使え、プログラミングプロセスを簡素化します。
簡単なコマンドでBeautiful soupはサイト構造を理解し、HTMLコンテナ内のコンテンツを解析するのに役立ちます。これは、Webスクレイピングのための最も洗練された高度なライブラリであり、現在も最も一般的で流行的なアプローチの1つです。
· 2005-2006年 ビジュアルなWebスクレイピングソフトウェア
2006年にStefan AndresenとKapax Software(2013年にKofaxに買収された)は、Web Integration Platformバージョン6.0を発表しました。これは、視覚的なWebスクレイピングソフトウェアとして理解されています。ユーザーは簡単にWebページのコンテンツを強調し、使用可能なExcelファイル、またはデータベースに変換できます。
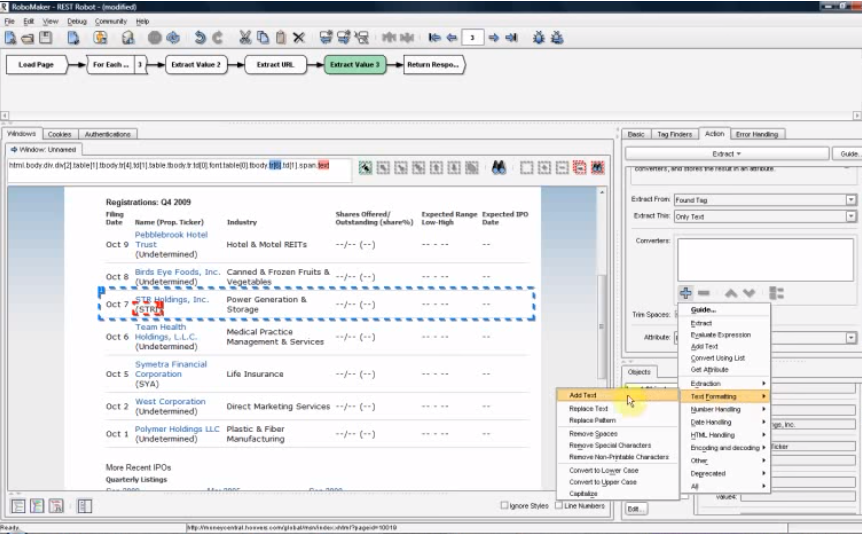
ですから、Webスクレイピングソフトウェアは数多くの非プログラマが独自にWebスクレイピングを行う方法になります。
それ以来、Webスクレイピングが主流になってきています。プログラマー以外の人にとっては、ビジュアルプロセスを提供する80件以上すぐに使用できるデータ抽出ソフトウェアを簡単に見つけることができます。
これからWebスクレイピングはどうなるのか?
人々は常にデータを求めています。私たちは、データを収集し、データを処理し、データを研究、洞察、情報、物語、資産などのさまざまなものに変換します。以前では、データの探しと収集することに、多くの時間、労力、費用を費やしていました。これは大手企業や大規模な組織だけがそういう余裕あります。
2018年には、WWWまたは「インターネット」として知られているものは、18億以上のWebサイトから構成されています。このような膨大な量のデータが、数回のクリックで利用可能になりました。より多くの人々がインターネットを利用するにつれて、毎秒でもより多くのデータが生成されます。
今は過去に経験した時代よりも簡単な時代です。Web上で利用可能な限り、個人、企業、組織は必要なデータを入手することができます。Webクローラー/ボット、API、標準ライブラリー、様々な使いやすいソフトウェアのおかげで、誰かがデータを入手する必要があれば、必ず方法があります。または、便利で手頃なプロに頼むこともできます。
guru.comで「web scraping」を検索すると、10,088件の検索結果が出てきます。つまり、10,000人以上のフリーランサーがWebサイトでWebスクレイピングサービスを提供しています。Upworkでは13,190件で、fievere.comでは1,024件です。日本国内にもきっとたくさんあります。
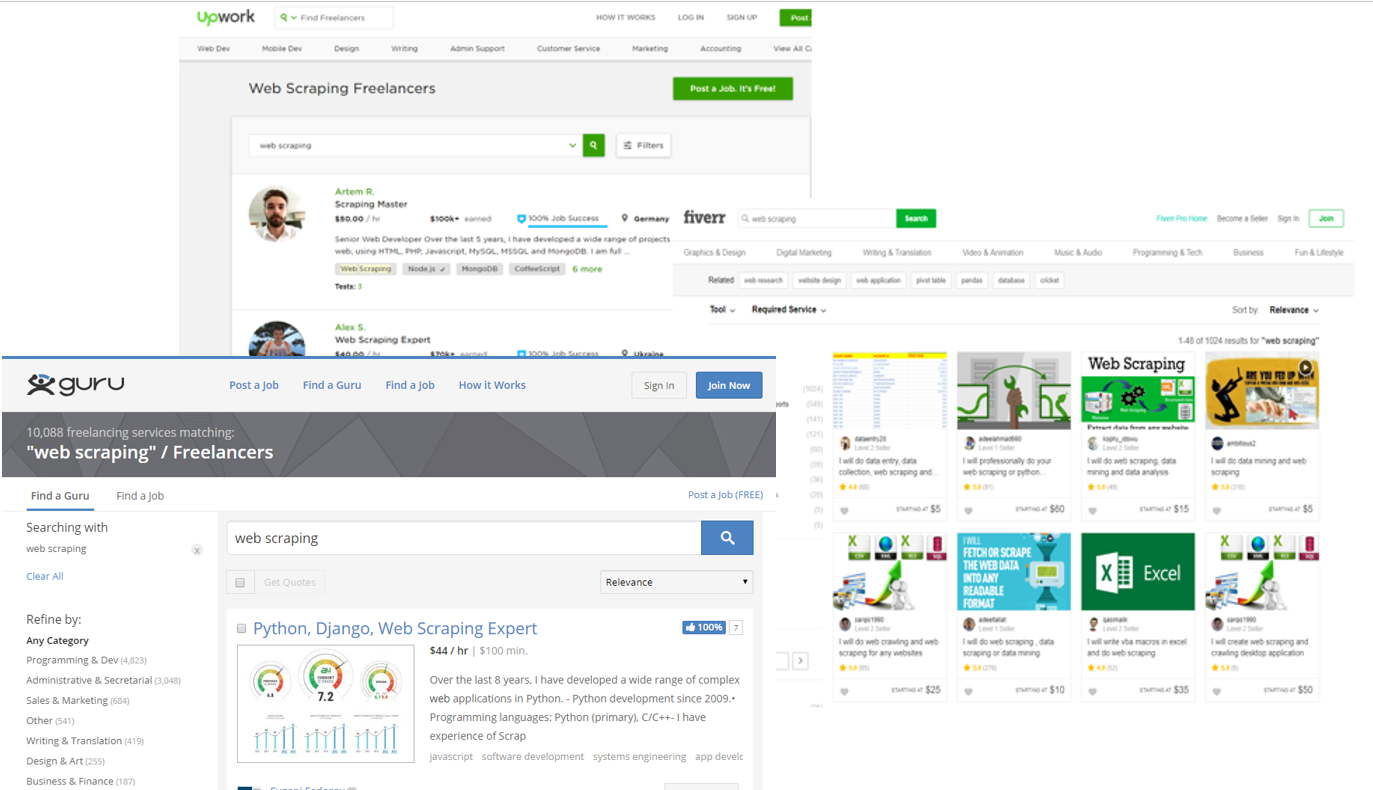
業種別の企業によるWebデータに対する需要の増加は、Webスクレイピング業界を推進し続けて、新しい市場、雇用機会、ビジネスチャンスをもたらしました。
その一方で、他の新興産業と同様に、Webスクレイピングも法的問題を招いています。
Webスクレイピングの合法性を取り巻く法的状況は進化し続けていますが、今ではまだ明確の法律がありません。今のところ、この傾向から出てくる最も興味深い法律問題の多くは、未だに解決されていなく、あるいは具体的な事実に依存しています。
Webスクレイピングはかなり長い間実践されてきたが、裁判所は、ビッグデータという背景でどのような関連法理論が適用されるかについて検討し始めているに過ぎありません。
現時点では、Webクローリングやスクレイピングに関連することがまだ発展しているため、これからどうなるのかを予測できません。しかし、確かめることは一つあります。つまり、インターネットがある限り、Webスクレイピングがあるということです。
新しく生まれたインターネットを検索可能にし、爆発的に成長するインターネットをより使いやすく、アクセスしやすくするのはWebスクレイピングです。
近い将来に、インターネットやWebスクレイピングりは、このように進むだろうということは間違いありません。